 Tutoriel | Consolidation des logs avec Rsylog, Mysql et Loganalyzer
Tutoriel | Consolidation des logs avec Rsylog, Mysql et Loganalyzer
Article publié le 23 Septembre 2013
Le tutoriel ci-dessous vous propose une solution permettant de centraliser et de consolider vos logs.
Grâce à ce petit tuto vous pourrez stocker tout les logs de vos serveurs dans une seule base MySQL. Cette solution ne pourra que vous faciliter la vie!
1) Configuration du serveur de logs
- Dans un premier temps installez Rsyslog:
yum install rsyslog rsyslog-mysql
 Rsyslog est le daemon de journalisation par défaut de Debian 7 donc inutile de tenter de l'installer par contre n'oubliez pas d'installer rsyslog-mysql : apt-get install rsyslog-mysql / yum install
Rsyslog est le daemon de journalisation par défaut de Debian 7 donc inutile de tenter de l'installer par contre n'oubliez pas d'installer rsyslog-mysql : apt-get install rsyslog-mysql / yum install
Afin que Rsyslog fonctionne sous Red-Hat/Centos n'oubliez pas de stopper syslog-ng et de démarrer rsyslog:
service syslog stop && service rsylog start
Puis de désactiver le lancement automatique de syslog au démarrage de la machine et d'activer celui de rsyslog:
chkconfig syslog off
chkconfig rsylog on
- Installez Mysql-server et démarrez le:
yum install mysql-server (sous Red-Hat/CentOS) ou apt-get install mysql-server (sous Debian/Ubuntu)
/etc/init.d/mysql-server start
- Démarrer Mysql
/etc/init.d/mysqld start
- Création de la base:
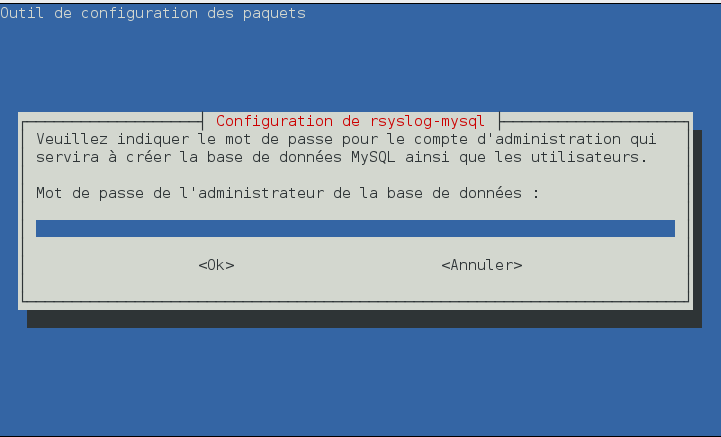
Sous debian la création de la base donnée se fait automatiquement grâce à l'outil DB-config. Renseignez juste le mot de passe mysql du user user de MySQL
Pour les utilisateurs de Red-Hat/Centos, vous devez exécuter un script de création de base:
cd /usr/share/doc/rsyslog-mysql-<version>
mysql -u root -p[votre mot de passe] < createDB.sql
(Rien ne vous empêche de modifier le script afin de modifier le nom de la base de donnée!)
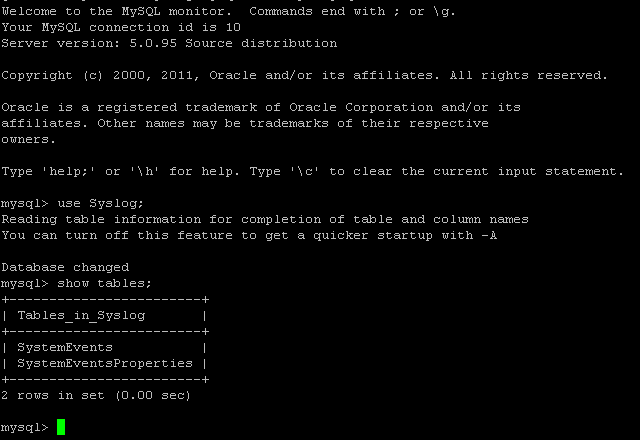
- Checker que votre base ait bien été créée:
mysql -u root -p
Je vous conseille d'initialiser un mot de passe pour l'utilisateur root de votre base mysql:
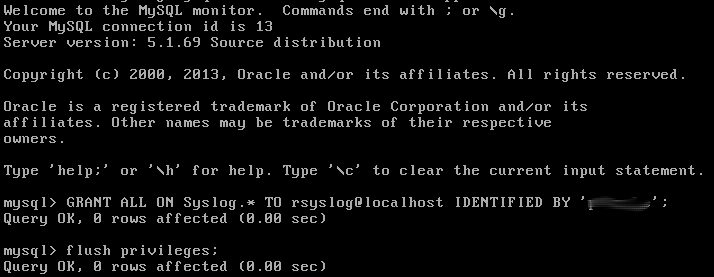
La partie flouté correspond au mot de passe que vous voulez attribuer au user Syslog
- Editez le fichier /etc/rsyslog.conf
Décommentez ces lignes:
$ModLoad ommysql
$ModLoad imudp
$UDPServerRun 514
$ModLoad imtcp
$InputTCPServerRun 514
Ajoutez ces lignes qui correspondent aux paramètres de connexions de la base de donnée ainsi qu'à la restriction de connexion par sous réseau (pour plus de sécurité):
*.* 😮 mmysql:127.00.1,<nom de la base>,<login>,<mot de passe>
le 😮 sans les guillemets
$AllowedSender UDP, 127.0.0.1, 192.168.1.0/24 #liste des sous réseaux autorisés à se connecter
$AllowedSender TCP, 127.0.0.1, 192.168.1.0/24 #liste des sous réseaux autorisés à se connecter
Redémarrez rsyslog en vous assurant qu'aucun autre daemon de journalisation est en cours d’exécution:
service rsyslog restart
2) Parti client
Ajoutez juste la ligne suivante à la fin du fichier /etc/rsyslog.conf
*.* @<ip du serveur>:514
Si vous voulez que rsyslog gère d'autre log (par exemple apache, mysql etc...)
Ajoutez cette ligne
$InputFileName <chemin du log a géré>
3) Installation de logAnalyzer
- Installez apache et PHP5
yum install httpd php php-mysql (sous Centos/RedHat) ou apt-get install apache php php-mysql (sous debian)
- Telechargez le package d'installation:
http://loganalyzer.adiscon.com/downloads
- Decompressez l'archive
tar -xvf <package>
- Copier les sources vers votre répertoire apache:
mkdir /var/www/loganalyzer/ (pour debian)
mkdir /var/www/loganalyser/ (pour Centos/Debian
cp <repertoire de loganalyser>/src/*<repertoire apache>
cp <repertoire de loganalyser>/contrib/* <repertoire apache>
- Exécutez le script configure.sh (sans oublier de le rendre executable via la commande chmod 700 configure.sh)
./configure.sh
- Connectez vous via votre navigateur à l'interface web de loganalyser (URL: <ip ou dns de la machine>/loganalyser):
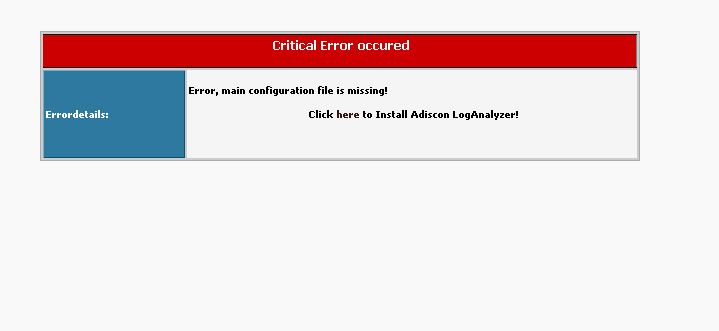
Cliquez sur "here"
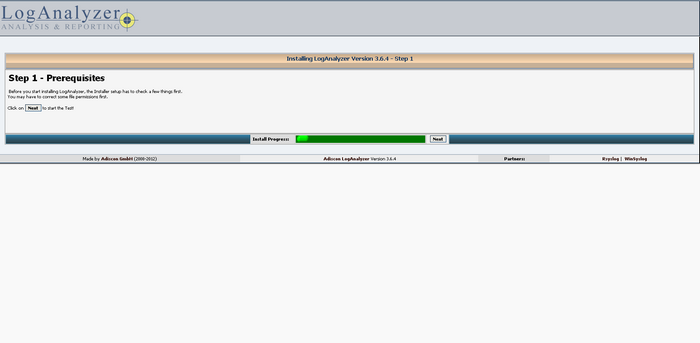
Cliquez sur next
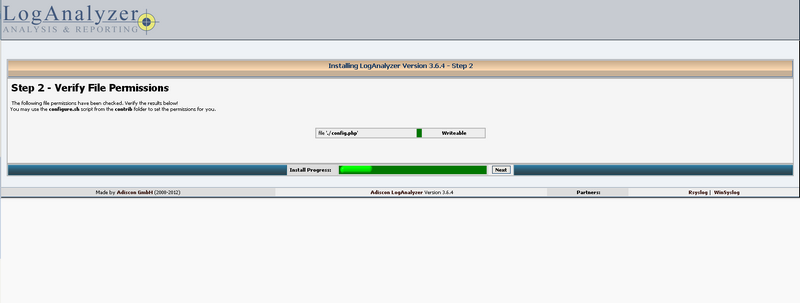
Cliquez sur next
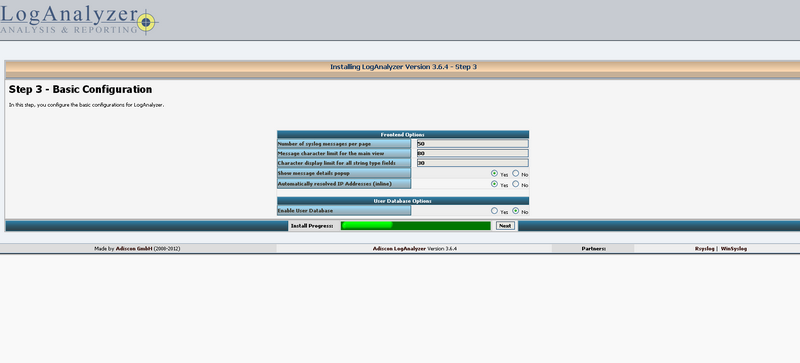
Cliquez sur "yes" à "enable user database" et remplissez les informations de connexion de votre base de donnée rsyslog. Cliquez sur "yes" à "require user to be logged in".
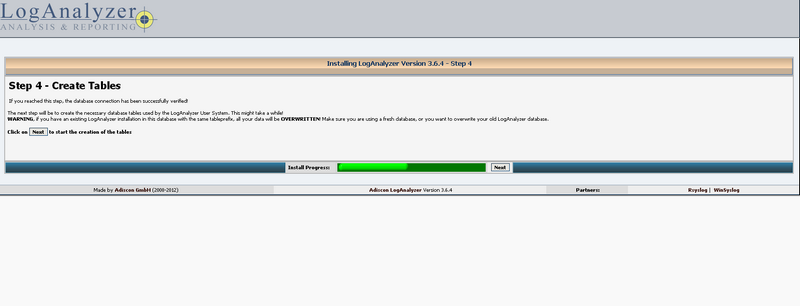
Cliquez sur next
Cliquez sur next
Créez le user avec lequel vous vous connecterez sur la gui de loganalyser puis cliquez sur next
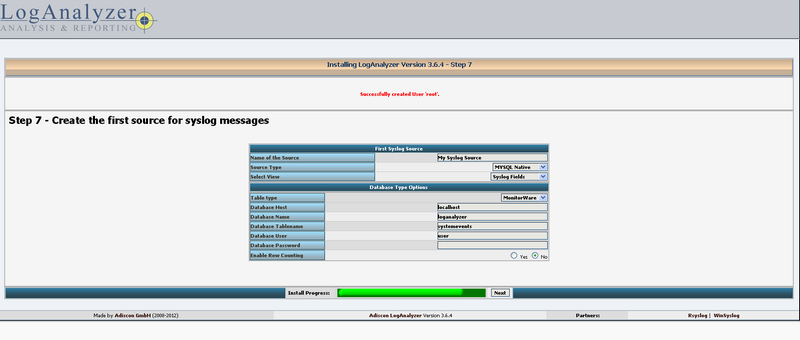
Sélectionnez "MYSQL Native" via le menu déroulant de "Source Type" puis renseignez les informations de connexions de la base de donnée de rsyslog et cochez yes à "enable row counting" puis cliquez sur next.
Cliquez sur finish.
Maintenant il ne vous reste plus qu'à vous connecter à loganalyser depuis votre navigateur et enjoy!!!!
tutoriel | installer un domaine nis
Article publiée le 14 Septembre 2013
La difficulté du métier d'admin système dépend toujours de la grandeur de son infrastructure. Plus il y a de serveurs à administrer plus il faut-être malin.
Prenons le simple exemple de l'administration des utilisateurs. Si vous avez 1000 serveurs à votre actif je vous vois mal faire des useradd pendant deux jours!
Soit vous faite un script SHELL de déploiement, soit ...
Vous utilisez NIS!
Si vous en avez jamais entendu parlé, NIS est un protocole client/serveur permettant la centralisation des informations sur un réseau UNIX.
En gros vous pouvez centraliser tout les fichiers de configuration de vos serveurs UNIX.
Pratique me direz vous!
Ci-dessous la procédure d'installation de NIS adaptée pour Debian/Ubuntu et RedHat/Centos:
![]() Faites très attention avec ce protocole, pensez à sécuriser votre infrastructure car une tel mise en place peut également représenter une faille de sécurité...
Faites très attention avec ce protocole, pensez à sécuriser votre infrastructure car une tel mise en place peut également représenter une faille de sécurité...
1) Installation partie serveur sous Centos/RedHat
- Installez les paquets:
yum install ypserv rpccind
- Initialisez votre domaine NIS
ypdomainname <nom de domaine>
- Editez le fichier /var/yp/Makefile
Remplacez "ALL = passwd group hosts rpc services netid protocols netgrp" par "ALL = passwd shadow group hosts rpc services netid protocols netgrp"
Exemple : ypdomainname vince.domain
- Ajoutez votre serveur NIS dans son propre domaine
vi /etc/sysconfig/network
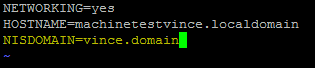
Verifiez bien que vos machines disposent bien d'un DNS (via les fichiers hosts ou serveurs DNS)
- On démarre les services:
/etc/init.d/rpcbind start
/etc/init.d/ypserv start
/etc/init.d/yppasswdd start
- On fait en sorte que ces services soient démarrés au démarrage de la machine
chkconfig rpcbind on
chkconfig ypserv on
chkconfig yppasswdd on
- On initialise la base nis avec la commande /usr/lib64/yp/ypinit -m
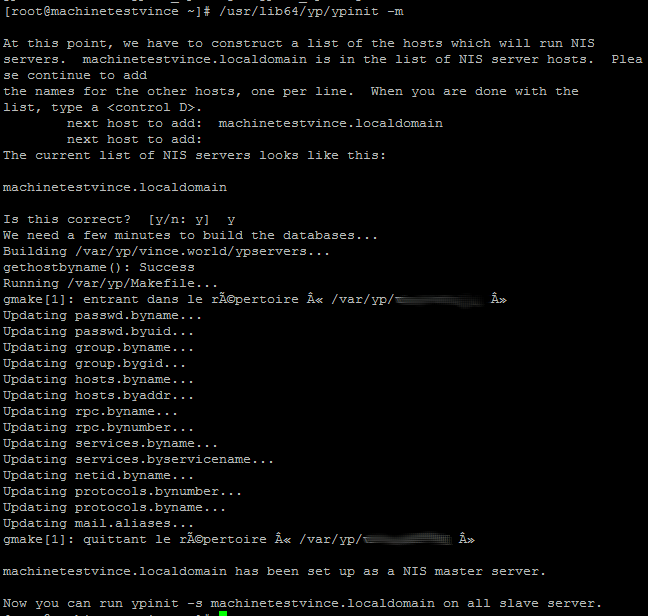
Comme vous pouvez le constater c'est ici que vous entrez le nom des autres serveurs NIS si vous voulez mettre en place des slave (utile uniquement si vous avez une grosse infrastructure)
2) Installation partie serveur sous Debian/Ubuntu
- Installez les paquets:
apt-get install nis
Si cette écran apparaît renseignez le nom de votre domaine NIS
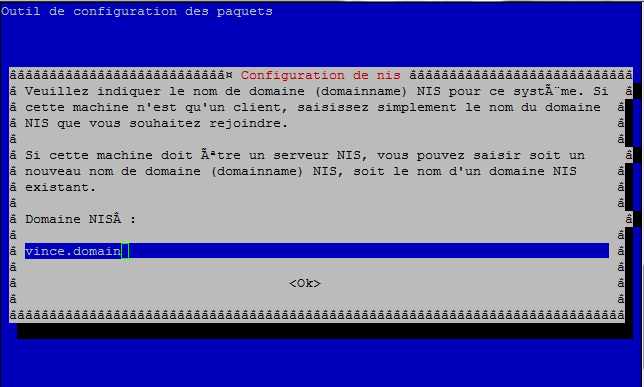
- Éditez le fichier /etc/default/nis
Remplacez "NISSERVER=false" par "NISSERVER=master"
- Éditez le fichier /var/yp/Makefile
Remplacez "ALL = passwd group hosts rpc services netid protocols netgrp" par "ALL = passwd shadow group hosts rpc services netid protocols netgrp"
- Exécutez la commande /usr/lib/yp/ypinit -m
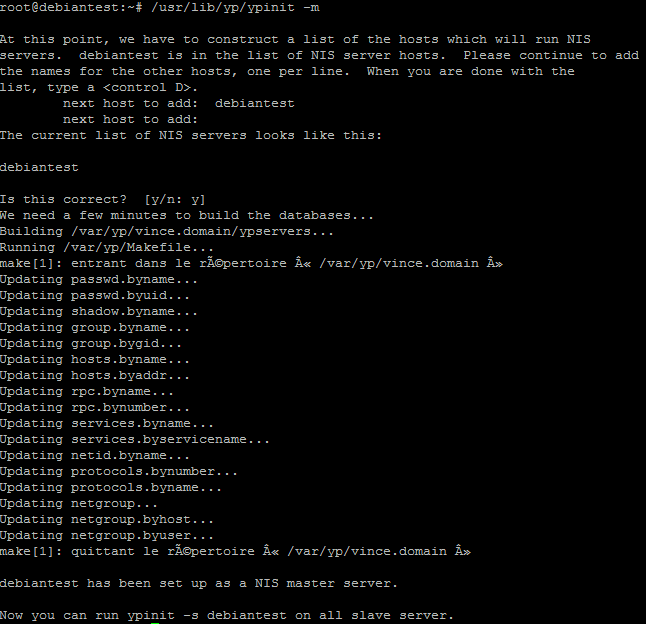
- Redémarrez NIS:
/etc/init.d/nis restart
3) Installation partie client
Sous Centos:
- Editez le fichier /etc/sysconfig/network et rajoutez la ligne:
NISDOMAIN=<votre domaine NIS>
- Editez le fichier /etc/sysconfig/authconfig et modifiez "USENIS=no" par "USENIS=yes"
- Editez le fichier /etc/yp.conf et ajoutez la ligne
domain <nom de votre domaine NIS> server <Dns de votre serveur nis>
- Editez le fichier /etc/nsswitch.conf (permet de choisir quelles élément seront centralisé par le NIS), pour cela ajoutez "nis" après "files" :
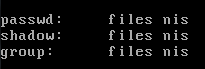
- Faites en sorte que le service NIS démarre bien au démarrage de la machine:
chkconfig rpcbind on
chkconfig ypbind on
reboot
Il ne vous reste plus qu'à checker en créant un user sur le serveur et essayer de vous loguer avec sur la machine cliente!
Après la création d'un user n'oubliez pas de de faire un refresh de la base NIS. Pour cela:
cd /var/yp && make
Petite astuce: si vous voulez que le répertoire home de votre user se crée tout seul:
Ajouter cette ligne dans le fichier /etc/pam.d/system-auth
session optional pam_mkhomedir.so skel=/etc/skel umask=077
Sous Debian/Ubuntu
- Installez le paquet nis:
apt-get install nis
- Editez le fichier /etc/yp.conf
Rajouter la ligne :
domain <nom du domaine> server <nom du serveur NIS>
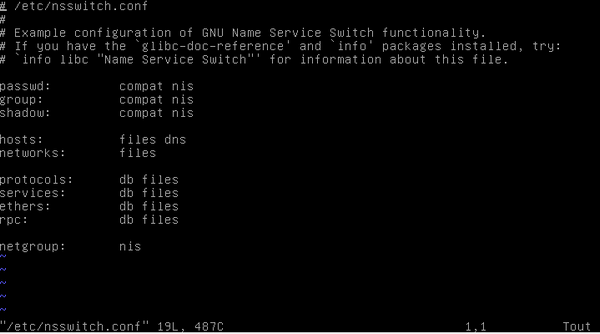
- Editez le fichier /etc/nsswitch.conf
Rajoutez "nis" après "compat" devant tout les éléments qui devront être centralisés
Exemple:
Il ne reste plus qu'à redémarrer.
Enjoy ! 🙂
Sauvegarder ses données avec Rsync
Article publiée le 13 Septembre 2013
En parcourant pas mal de forums, j'ai pu remarquer que pas mal de jeunes admins ne connaissaient pas Rync.
Rsync est un petit outil de sauvegarde extrêmement puissant. Grâce à cette outil j'ai pu sauvegarder des centaines de giga-octet de données sans problèmes.
Rsync se charge en plus de garder tous les droits et attributs de vos fichiers et gère en natif SSH pour faire une sauvegarde d'une machine vers une autre.
Installation:
apt-get install rsync (Pour debian) ou yum install rsync (pour Centos/RedHat)
Comment ça marche?
- En local
rsync -azv <fichier ou répertoire source> <répertoire de destination>
le -a conserve tout les attribut et droits des fichiers
le -z compression au moment de la copie (fait gagner du temps et limite le trafic réseau si vous utilisez rsync via scp)
le -v active le mode verbeux pour voir en temps réel ce qui se passe!
- Vers une autre machine
rsync -azv <fichier ou répertoire source> login@<ip ou dns du serveur distant>:<répertoire de destination>
![]() Rsync est très intelligent, si le fichier existe déjà dans le répertoire de destination, alors il ne sera pas sauvegardé de nouveau! Très utile si votre commande est interrompu en cours de sauvegarde.
Rsync est très intelligent, si le fichier existe déjà dans le répertoire de destination, alors il ne sera pas sauvegardé de nouveau! Très utile si votre commande est interrompu en cours de sauvegarde.
Si vous administrez une petite structure, je vous conseille de faire vos sauvegardes avec cette outil via un petit script shell. 😉
tutoriel | Installer et configurer Tomcat 7
Article publiée le 09 Septembre 2013
Mis à jour le 8 Novembre 2016
 Tomcat 8 étant sorti, je me suis permis de rédiger un petit tutoriel adapté:
Tomcat 8 étant sorti, je me suis permis de rédiger un petit tutoriel adapté:
http://journaldunadminlinux.fr/tutoriel-installer-et-configurer-tomcat-8/
Tomcat est le conteneur libre de servlets le plus utilisé.
En parcourant les forums j'ai remarqué que pas mal d'admin avaient des soucis pour installer et configurer Tomcat.
Ci-dessous le tutoriel d'installation et de configuration de Tomcat 7 (adapté pour Debian/Ubuntu et RedHat/CentOS):
Je privilégie l'installation manuelle de Tomcat plutôt que de passer par le gestionnaire de paquet. Vous pourrez ainsi personnaliser votre installation et choisir une version récente de Tomcat.
1) Installation
Prérequis: java
yum install java-1.6.0 pour (RedHat/Centos) ou apt-get install openjdk* (Sous debian/Ubuntu)
- Tout d'abord récupérez le tar.gz sur le site de tomcat via http://tomcat.apache.org/download-70.cgi (section core téléchargez la version tar.gz)
Au moment de la rédaction de cette article Tomcat 8 est sorti en version RC1. Je vous déconseille fortement d'utiliser une tel version car celle-ci est encore trop instable.
- Créez proprement votre répertoire d'installation de tomcat, dans mon cas cela sera /apps/tomcat
mkdir /apps/tomcat
- Décompressez l'archive dans le répertoire de destination:
mv <votre archive>.tar.gz <repertoire d'installation> && tar -xvf <repertoire d'installation>/<votre archive>.tar.gz
exemple: mv apache-tomcat-7.0.42.tar.gz && tar -xvf /apps/tomcat/apache-tomcat-7.0.42.tar.gz
- Faites un ls dans le repertoire d'installation et vous pourrez voir ceci:

Quelques petites explications:
- Le répertoire bin contient tous les scripts de tomcat notamment ceux de démarrage et d’arrêt.
- Le répertoire conf contient tous les fichiers de configuration de tomcat
- Le répertoire webapps contient toutes les webapps (vos servlets java)
2) Configuration
- Allez dans le répertoire conf:
cd conf
- Si vous désirez changer le port d'écoute éditez le fichier server.xml et éditez cette ligne en remplaçant le port par défaut 8080 par celui que vous désirez:
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<!-- A "Connector" using the shared thread pool-->
- Editons ensuite le fichier tomcat-user afin de définir le mot de passe de l'interface d'administration de tomcat:
Le dernier "paragraphe" du fichier de configuration est commenté. Pour le dé-commentez enlevez :
<!-- et -->
Ajoutez ensuite les balises rolename:
<role rolename="manager"/>
<role rolename="manager-gui"/>
Créons ensuite le user qui aura les droits d'admin de votre serveur tomcat:
<user username="tomcat-admin" password="tomcat" roles="manager,manager-gui"/>
Sans oublier de modifier le password 😉
-Il ne reste plus qu' à redémarrer Tomcat :
rendez vous dans le répertoire bin (de tomcat) et exécutez ces scripts:
./shutdown.sh (pour arréter tomcat)
./startup.sh (pour démarrer tomcat)
- Connectez vous à l'interface d'administration de votre serveur tomcat via votre navigateur depuis cette URL: <ip ou DNS de votre machine>:8080
- Cliquez sur Manager app et entrez les identifiants que vous avez paramétrés précédemment dans votre fichier tomcat-users.xml

Ici vous trouverez la liste des Webapp déployées.
-Il existe 2 méthodes pour déployer une Webapp (fichier .war):
La première (la plus simple) consiste à cliquer sur le bouton déployer et de selectionnez votre fichier war.
Tomcat se chargera de la déployer pour vous. Une fois le déploiement terminé vous pourrez voir apparaître une nouvelle ligne avec le nom de votre Webapp.
La deuxième plus longue mais très utile si vous voulez scripter des déploiements automatiques consiste à arrêter votre serveur tomcat, déposez votre fichier war dans le répertoire webapps et redémarrer le service tomcat.
Votre Webapp sera automatiquement déployée.
3) Tunning :
Il est possible, si vous déployez des applications lourdes ou en grand nombre, que vous ayez des problèmes mémoires.
Dans ce cas vous pourrez avoir des messages d'erreur ou de grosses lenteurs lors de l’exécution de vos webapps.
Pour cela éditez le fichier startup.sh et ajoutez à la ligne export JAVA_OPTS= -server -Xms<mémoire minimal alloué> -Xmx <mémoire maximum alloué>
Exemple:
export JAVA_OPTS="-server -Xms2048m -Xmx2048m"
Redémarrez votre serveur Tomcat afin que les modifications soient prises en comptes.
Si vous rencontrez d'autres problèmes mémoire vous pouvez vous rendre sur cette page :
Cette article traite d'un problème Tomcat et pourra peut-être vous aider.
4) Script de démarrage
Afin de vous faciliter la vie, je vous livre ci-dessous le script de démarrage de tomcat à déposer dans le répertoire init.d:
#!/bin/sh
CATALINA_HOME=<repertoire tomcat>; export CATALINA_HOME
JAVA_HOME=<repertoire java>; export JAVA_HOME
TOMCAT_OWNER=<votre user tomcat>; export TOMCAT_OWNER
start() {
echo -n "Starting Tomcat: "
su $TOMCAT_OWNER -c $CATALINA_HOME/bin/startup.sh
sleep 2
}
stop() {
echo -n "Stopping Tomcat: "
su $TOMCAT_OWNER -c $CATALINA_HOME/bin/shutdown.sh
}
# See how we were called.
case "$1" in
start)
start
;;
stop)
stop
;;
restart)
stop
start
;;
*)
echo $"Usage: tomcat {start|stop|restart}"
exit
esac
5) Best Pratice
- Si votre application doit-être accessible depuis le monde extérieur je vous conseille de procéder à un couplage (Apache/Tomcat) avec les règles firewall qui vont bien
- Utilisez toujours un serveur apache en front en mode revese proxy. Vos clients ne doivent pas se connecter en direct sur le Tomcat. Un tuto est disponible: http://journaldunadminlinux.fr/tutoriel-mettre-en-place-un-reverse-proxy-sur-apache-via-mod_proxy/
monitoring | Surveiller votre système avec SAR
Article publiée le 2 Septembre 2013
La surveillance de l'état de santé des machines est une tâche récurrente pour un admin système. Un bon admin système doit être capable de fournir rapidement toutes les informations sur son système (cause d'un ralentissement, dysfonctionnement etc.)
Ci dessous la présentation et le tuto d'installation d'un autre outil de monitoring (car on en a jamais assez!!) SAR.
Sar permet d'avoir l'historique concernant l'activité de votre système contrairement aux autres outils qui vous fournissent uniquement des informations en temps réels.
1) Installation
Pour installer Sar sous debian:
apt-get install sysstat
Pour installer Sar sous CentOs/Red-Hat/Fedora:
yum install sysstat.
2) Configuration
Sous debian activez le collecteur d'activité, pour cela éditez le fichier /etc/default/sysstat et remplacez ENABLED="false" par ENABLED="true"
Sous CentOs/Red-Hat/Fedora il vous suffit de démarrer le service: service sysstat start
Par défaut systat effectue une collecte toutes les 10 minutes. Je vous conseille, afin d'avoir une vision de votre système plus fine de réduire l'intervalle à 2 minutes:
- Editez la crontab de systat:
vi /etc/cron.d/systat
Sous debian modifiez cette ligne:
5-55/10 * * * * root command -v debian-sa1 > /dev/null && debian-sa1 1 1
par
*/2 * * * * root command -v debian-sa1 > /dev/null && debian-sa1 1 1
Sous Centos/RedHat/Fedora modifiez cette ligne:
*/10 * * * * root /usr/lib64/sa/sa1 1 1
par
*/2 * * * * root /usr/lib64/sa/sa 1 1 1
- Enregistrez le fichier crontab
- Redemarrez le service systat
/etc/init.d/sysstat restart
3) Utilisation de la commande SAR
La commande SAR vous permettra d'afficher le contenu de votre systat dans la sortie standard (votre écran).
Exemple d'affichage de la commande sar -u (charge CPU):

Etat de la mémoire : sar - r

Etat du Swap: sar -W

Etat des IO disque : sar -b

IO par disque : sar -d

Enfin vous avez également la possibilité d'afficher le résultat de l'intégralité des commandes SAR via la commande:
sar -A
Enjoy! 🙂
tuto | installation et gestion de gfs2
Article publiée le 24 Août 2013
Un système de fichier clusterisé permet le partage d'une partition sur plusieurs machines.
Les avantages d'un tel système de ficher sont nombreux:
- Montage d'un fs sur plusieurs machines différentes
- Performances grandements améliorées
- Gestion de grandes quantités de données
- Meilleur gestion des volumes contenant énormément de petits fichiers
- Bonne gestion des gros fichiers
- Possibilité de gérer des quotas
Ayant testé et même vu le fonctionnement de plusieurs FS clusterisé je dois dire que le système de fichier GFS2 est le plus simple à mettre en place.
Ma philosophie en tant qu'admin système est de mettre en place les solutions les plus économiques, les plus faciles et les plus performantes.
GFS2 (conçu par Red Hat) répond à ces trois critères.
Le tutoriel ci-dessous vous donne la marche à suivre pour mettre en place GFS2.
GFS2 étant un produit de RED HAT, ce tutoriel sera exclusivement effectué via 2 machines CentOS 6.4.
Avant de commencer ce tutoriel assurez vous que votre SAN soit correctement paramétré et vos FS montés.
Assurez vous également que votre serveur DNS est correctement configuré pour résoudre les noms des machines.
Si vous ne disposez pas de serveur DNS administrable, renseignez correctement vos fichiers hosts (/etc/hosts).
Installons les paquets requis:
yum install cman gfs2-utils kmod-dlm modcluster ricci luci cluster-snmp iscsi_initiator-utils openais oddjobs rgmanager
1) Creation Cluster
Commençons par créer un cluster de machine:
Je vous assure cela sera très simple avec l'interface d'administration Web de Luci!
Tout d'abord démarrons tous les service nécessaire au cluster:
Sur votre node 1 (considéré comme le "Master"):
- chkconfig luci on && service luci start
Changez ensuite le mot de passe Unix de Luci:
passwd luci
Sur tout les nodes:
- chkconfig ricci on && service ricci start
- chkconfig gfs2 on && service gfs2 start
- chkconfig cman on && service cman start
Maintenant connectez vous à l'interface Web de Luci:
https://<ip de votre node 1>:8084
Luci est une interface graphique permettant de configurer les fichiers de configuration /etc/cluster/cluster.conf des différents nœuds et de gérer tous les services de clustering.
Entrez vos login root pour accéder à l'interface d'administration:
Cliquez sur Create pour créer votre cluster et remplissez les informations. Ajoutez tout vos nœuds sauf celui qui héberge luci qui lui sera ajouté d'office:
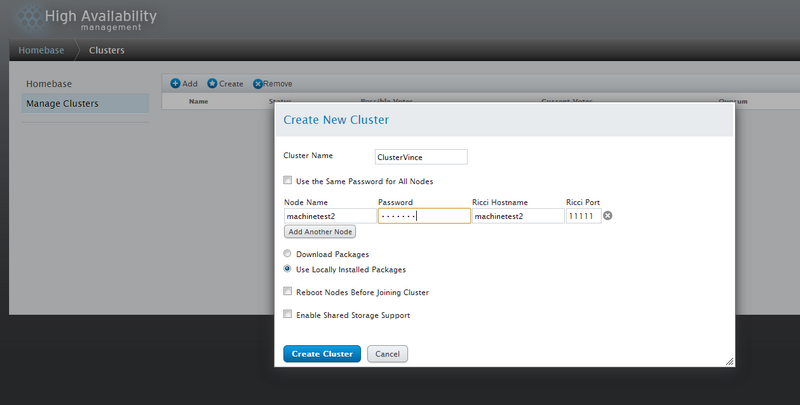
 Encore une fois vérifiez que votre DNS ou votre fichier hosts soient parfaitement configurés!
Encore une fois vérifiez que votre DNS ou votre fichier hosts soient parfaitement configurés!
Cliquez sur Create Cluster une fois tout vos nœuds saisies.
Si tout se passe bien vous devriez avoir un écran ressemblant à la capture ci-dessous:
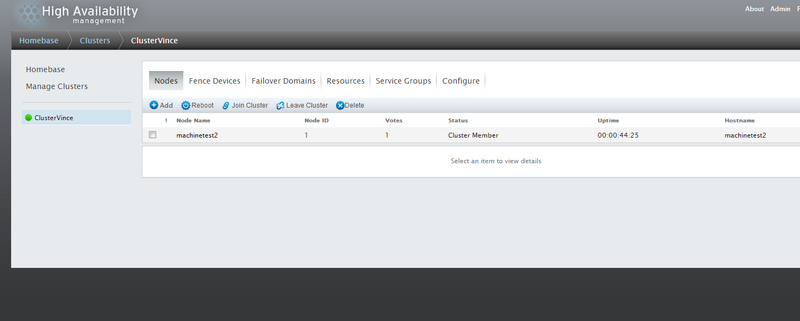
Ça y'est votre Cluster est créé et opérationnel!
2) Création partition GFS2
D'abord on crée le FS, pour cela exécutez la commande suivante sur un de vos noeuds:
mkfs.gfs2 -p lock_dlm -t <nom du cluster>:gfs2 -j 8 <chemin de votre volume San>
Exemple:
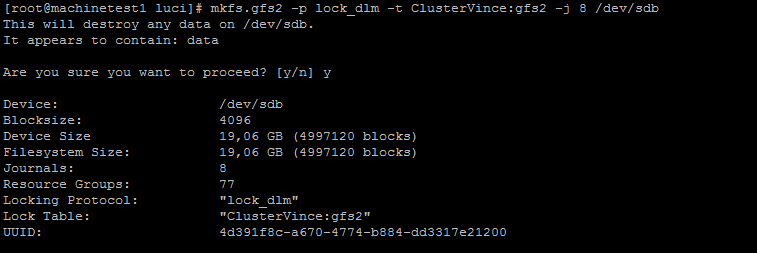
Une fois ceci terminée il ne reste plus qu'à monter la partition sur tout vos nœuds:
mount -o acl -t gfs2 <chemin de votre volume> <votre point de montage>
Exemple:
mount -o acl -t gfs2 /dev/sdb /mnt/testgfs2/
Voila votre Cluster GFS2 est opérationnel!
Pour faire les choses bien jusqu'au bout n'oubliez pas d'éditez le fstab!
Exemple:
vi /etc/fstab:
/dev/sdb /mnt/testgfs2 gfs2 defaults,acl 0
3) Quelque commande bien utile
Pour monter une partition gfs2 avec le système de quota actif:
gfs2_quota limit -u user -l size <point de montage>
Pour fixer un quota:
gfs2_quota warn -u user -l size <point de montage>
Pour afficher le quota d'un user
gfs2_quota get -u user
Pour afficher le quota d'un volume
gfs2_quota list -f <point de montage>
Pour réparer votre fs gfs2 corrompus:
gfs2_fsck /dev/my_vg/my_gfs
Pour conclure GFS2 est le système de fichier idéal si vous avez besoin d'un partage pouvant gérer un grand nombre de fichier ou une masse importante de données tout en gardant d'excellentes performances.
tutoriel | Connecter un client Linux à un iscsi target
Publiée le 20 Aout 2013
Petit tuto qui vous expliquera comment faire pour connecter un volume ISCSI disponible depuis votre baie ou de votre serveur iscsi sur votre client Linux.
Ce tutoriel sera adapté pour les distribs RedHat/Centos/Fedora et Ubuntu/Debian
- Dans un premier temps installez open-iscsi
apt-get install open-iscsi (pour debian/Ubuntu) ou yum iscsi-initiator-utils (pour RedHat/Centos/Fedora)
- Lancer la commande suivante pour détecter les target iscsi.
iscsiadm --mode discovery --type sendtargets --portal <adresse de votre serveur iscsi>
Si tous se passe bien, la commande vous renverra l'ip de votre serveur iscsi avec l'IQN.
Exemple:

- Il ne reste plus qu'à connecter votre volume ISCSI, pour cela lancez la commande suivante:
iscsiadm --mode node --targetname <votre IQN> \ --portal <ip de votre serveur iscsi> --login
Exemple:

Il ne vous reste plus qu'à checker que votre volume soit reconnu par l'OS avec un petit fdisk -l
- Pour déconnecter votre volume proprement, utilisez la commande suivante:
iscsiadm --mode node --targetname <votre IQN> \ --portal <ip de votre serveur iscsi> --logout
Surveiller votre système avec Nmon
Article publié le 13 Aout 2013
Mis à jour le 14 Aout 2013
Un bon admin système est un admin qui sait ce qui se passe sur son système à tout moment. Qui peut savoir en 10 secondes montre à la main les causes d'une éventuelle perte de performances ou autre petites "joyeuseries" 😉
La plupart des outils utilisés sont top, htop, iotop, iostat et j'en passe...
Pourtant un petit outil très similaire à Glance (pour HP-UX) existe: Nmon
Disponible dans les dépôts officiels de debian un petit "apt-get install nmon" suffira ou fedora via un yum install nmon.
Pour les utilisateurs de Red-Hat/Centos, je vous invite à télécharger les sources directement sur le site du développeur:
http://nmon.sourceforge.net/pmwiki.php
Cet outil vous fournira un état complet de l'état de votre système (CPU, mémoire, disque, IO, network IO, etc, etc etc...)
Pas besoin de vous expliquer comment cet outil fonctionne car celui ci est extrêmement intuitif comme vous pourrez le constater sur la capture d'écran ci dessous:


Enjoy 🙂
[tutoriel] Installation et configuration | OpenFiler
Article publiée le 10 Aout 2013
Mise à jour le 22 Mars 2016
OpenFiler est pour moi une petite merveille de l'OpenSource. Il vous permet de monter votre SAN en deux temps trois mouvements. Pour moi c'est la solution idéal pour les TPE/PME ayant peu de moyen.
Cette solution très fiable pourra même faire le bonheur d'entreprises plus grosses avec de gros moyen IT.
De plus il est possible de souscrire à un support ou d'acheter des Upgrade pour adapter votre solution de stockage à la virtualisation (optimisation des I/O) ou au support Fibre Channel.
Le site officiel d'OpenFiler: http://www.openfiler.com/
Ce tutoriel vous fournira la procédure d'installation et de configuration pour avoir un SAN iSCSI fonctionnel.
Téléchargez l'ISO d'open Filer via ce lien: http://www.openfiler.com/community/download
Pour ce tutoriel j'ai utilisé la version 2.99 (la plus récente)
1) Installation
Prérequis:
Machine avec au minimum 512MB de ram et 2 disques dur (ou volume RAID).
Un disque sera réservé pour le système et l'autre pour les Datas
Si vous avez l'habitude des installation d'OS Linux vous pouvez passez le chapitre "installation" de ce tutoriel
* Bootez sur l'ISO et appuyer sur entrer:

* Après le chargement du noyau vous arrivez sur cette écran:
Cliquez sur "next"
Choisissez la configuration de votre clavier et cliquez sur "next"
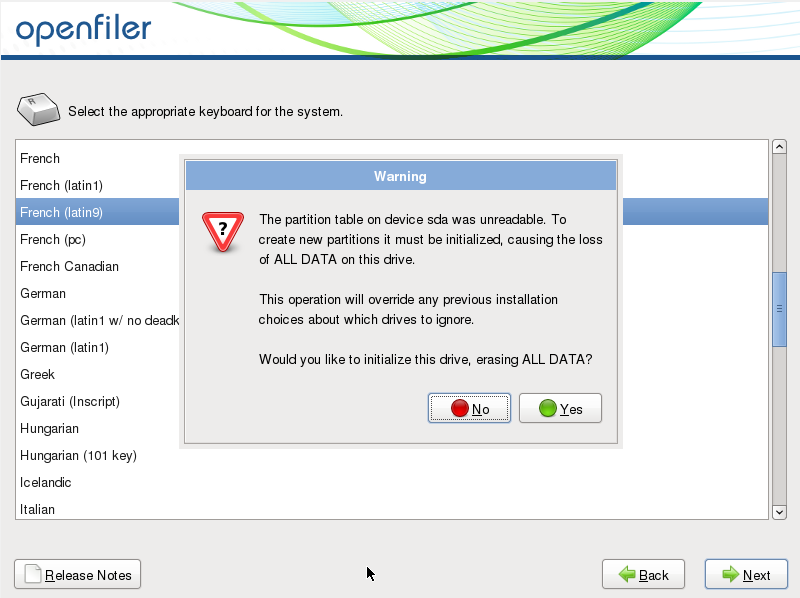
Cliquez sur Yes pour que l'installateur formate vos disques.
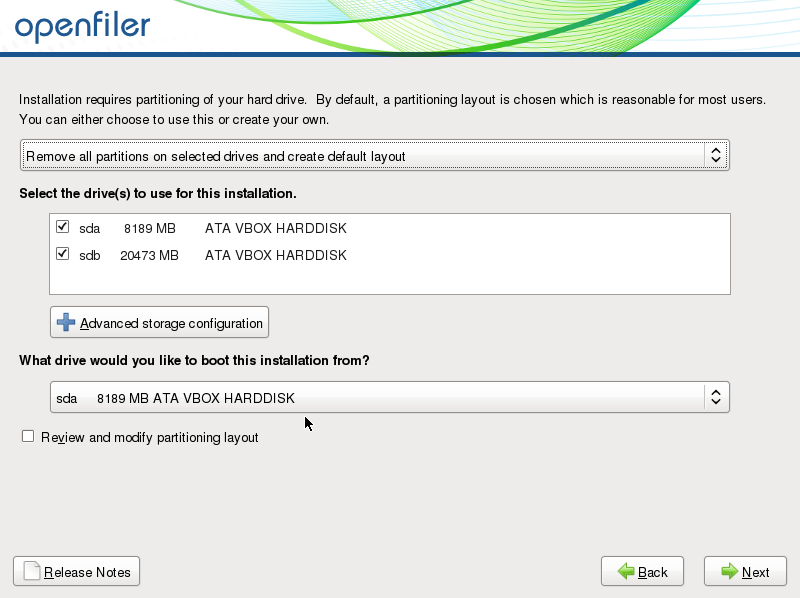
Vous pouvez ici partitionner vos disques. Dans mon cas je vais laisser l'installateur gérer le partitionnement des mes 2 disques. Cliquez sur "next" et confirmez en cliquant sur le bouton Yes de la boite de dialogue qui apparaîtra.
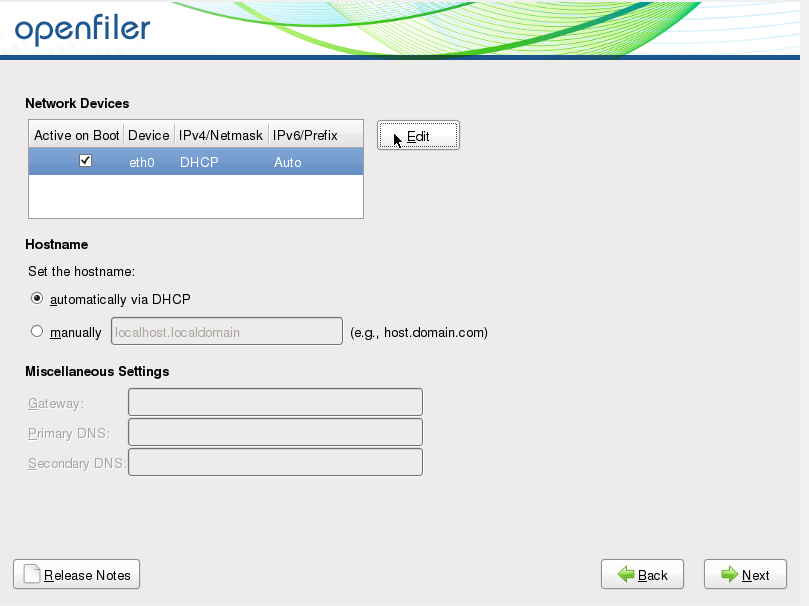
Cliquez sur édit et procédez à la configuration réseau:
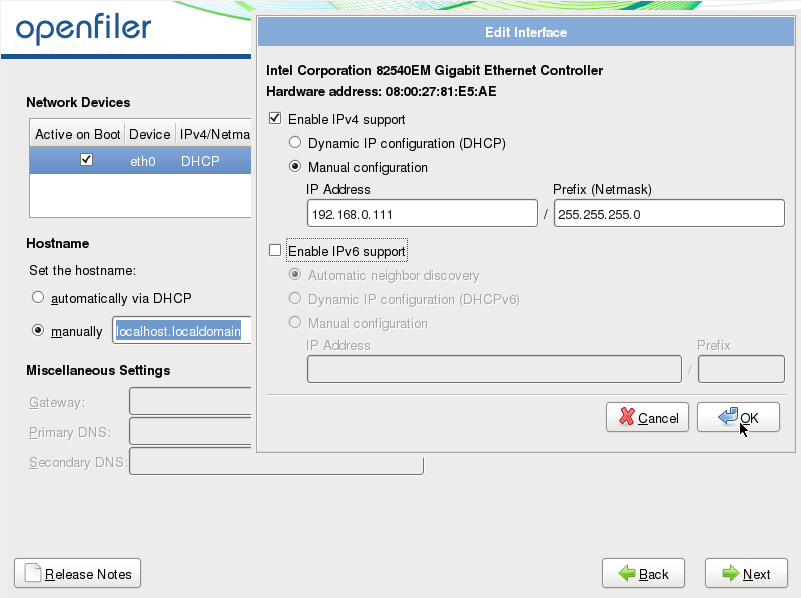
Cliquez sur OK et procédez au paramétrage IP de votre passerelle et de votre serveur DNS puis cliquez sur "next"
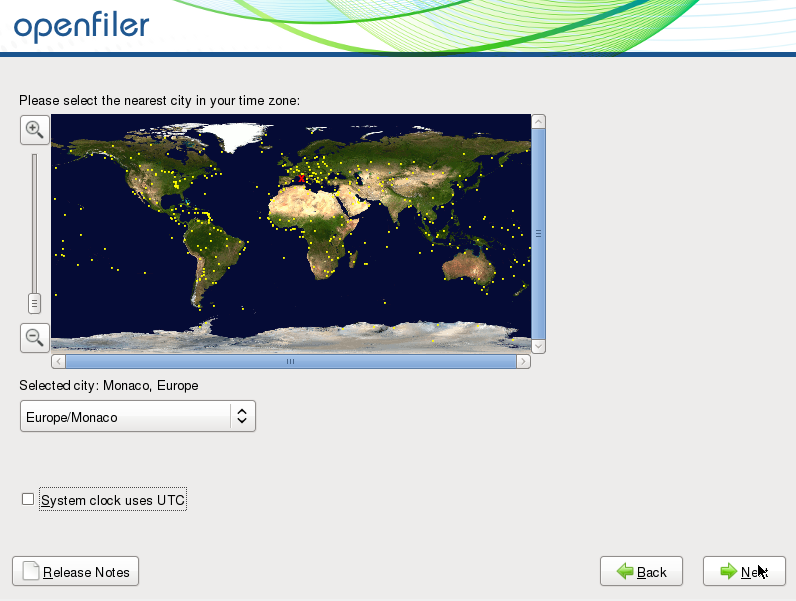
Sélectionnez ici votre fuseau horaire puis cliquez sur Next.
A l'écran suivant il vous sera demander de définir le mot de passe. Après l'avoir fais cliquez sur "Next"
Un dernier écran de confirmation apparaîtra alors, cliquez sur next.
Ca y'est votre OS s'installe!
Cliquez sur le bouton "reboot" une fois l'installation terminée.
2) Configuration de votre SAN
Une fois votre OS chargé un écran de ce type apparait:
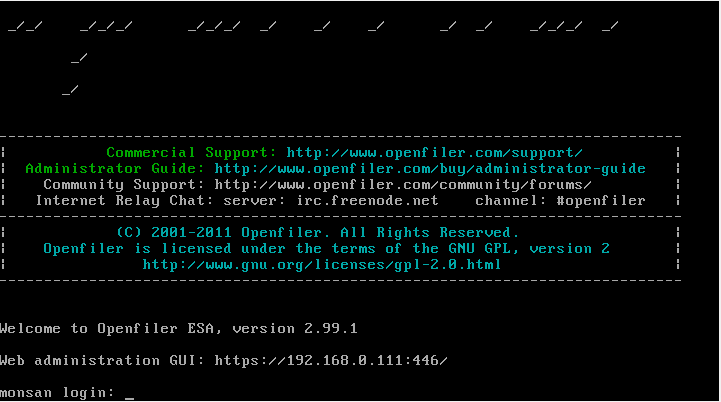
Vous pouvez décidez de vous loguer sur le Shell de l'openFiler, chose que je vous déconseille car tout est déjà correctement paramétré!
Relevez l'URL de la Web Administration GUI et rentrez la dans votre navigateur.
Validez le certificat de sécurité non validé pour arriver à l'écran de Login:
Open filer possède 2 interface d'administration:
- La première est accessible en entrant vos identifiant UNIX (c'est à dire root/<votre mot de passe root>). Une interface vous permettra uniquement de choisir la langue,gérer les quotas ainsi que les comptes utilisateurs de la deuxième interface.
- La deuxième interface est accessible en entrant les mots de passe par défaut de la WebGui d'open filer (openfiler/password). Celle ci vous permettra de paramétrer votre SAN.
*Pour commencer nous allons nous connecter sur la 1er interface pour mettre la langue en Francais (certain me diront merci ;-))
Une fois votre langue sélectionnée cliquez sur submit puis sur "logout" (en haut à droite).
* Maintenant loguez vous avec les identifiants par défaut d'openfiler pour commencer à paramétrer votre SAN.
Rappel des identifiants: login : openfiler
mot de passe : password
Voici l'interface d'openfiler. Franchement c'est un vrai plaisir!!!
Je vais maintenant faire un exemple de création de volume SAN avec des volumes iscsi
Les personnes expertes en stockage qui liront ce tuto ne seront pas dépaysées!
Tous d'abord créons un volume Physique, pour cela cliquez sur le bouton "Volume" puis sur le lien "create new physical volume"
Vous devriez avoir l'écran ci-dessous s'afficher:
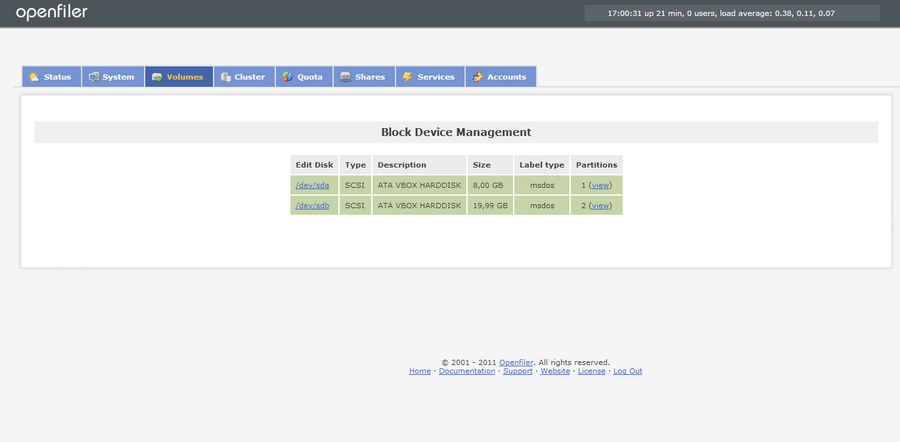
Je vous déconseille fortement d'utilisez le disque système pour vous en servir comme disque de stockage (performance oblige!)
Cliquez sur le lien /dev/<disk> dans la 1er colonne à gauche correspondant à votre disque.
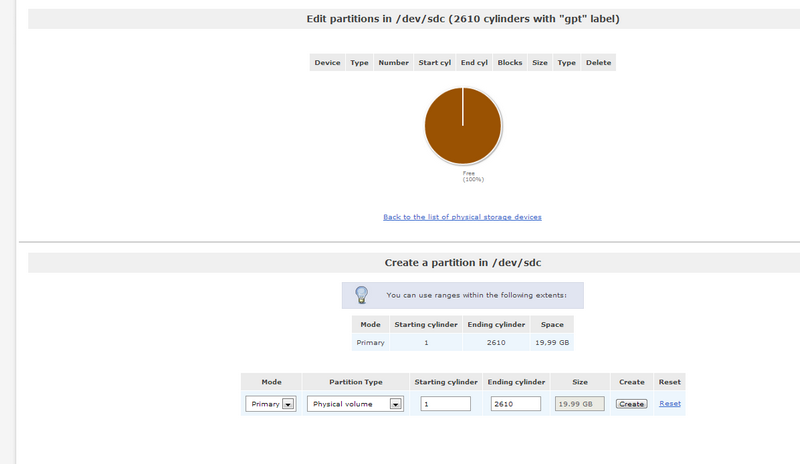
Créez votre partition puis cliquez sur "create".
Cliquez sur l'onglet volume en haut pour revenir à l'écran de gestion des volumes:
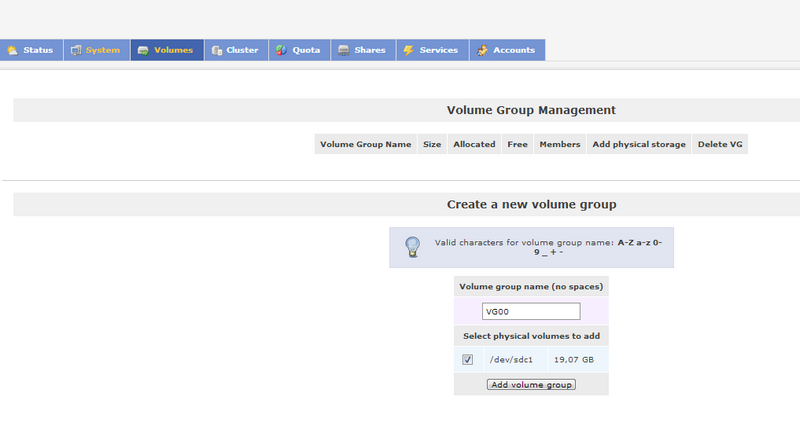
C'est exactement le même système que les LVM.
Nous allons maintenant créer un volume Group composé d'un ou plusieurs disques physiques.
Cochez le ou les disques sans oublier d'indiquer un nom à votre volume group puis cliquez sur le bouton "Add Volume Group".
- Nous allons maintenant activer le service ISCSI. Pour cela cliquez sur l'onglet "service".
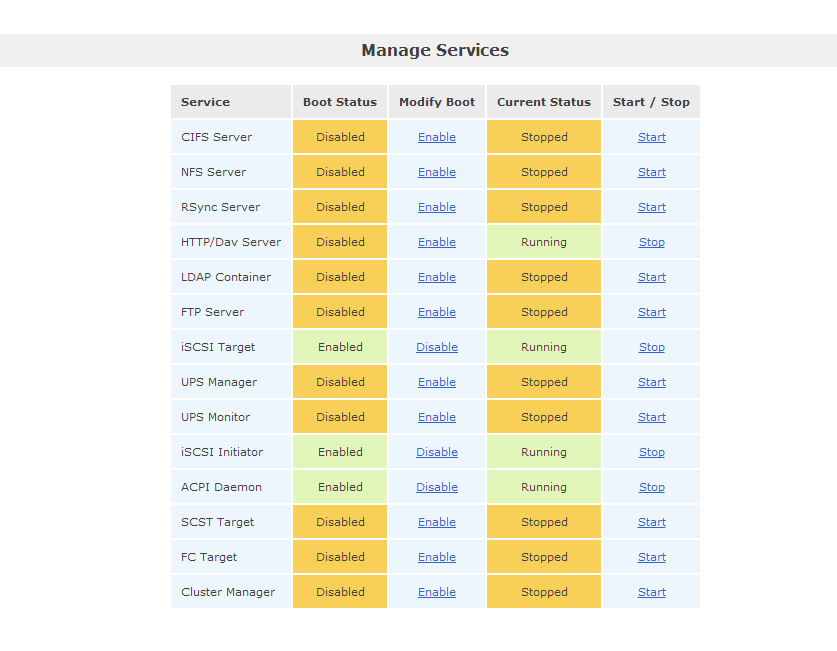
C'est ici que vous trouverez tous les services supportés par OpenFiler. Dans notre cas nous allons activer le service "iSCSI Initiator" et iSCSI Target". Pour cela Cliquez sur "Enable" pour l'activer et "start" pour le démarrer.
Notez que vous avez également le service NFS de disponible si vous voulez créer un partage tous simple accessible depuis plusieurs machines.
Une fois les services démarrés cliquez sur l'onglet share.
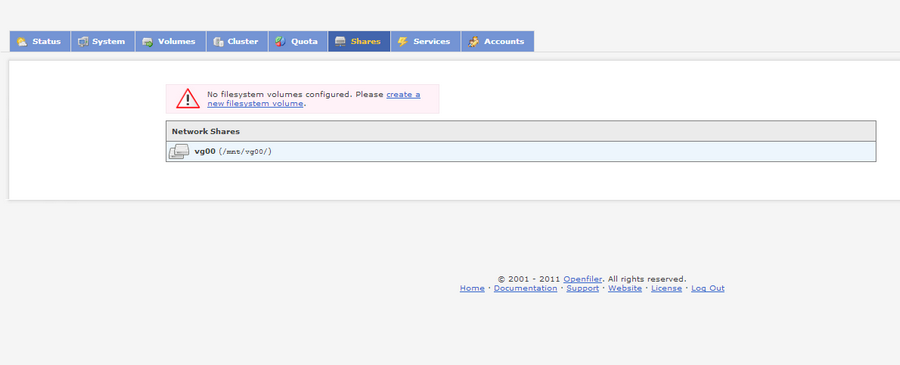
Cliquez sur "Create a new filesystem volume"
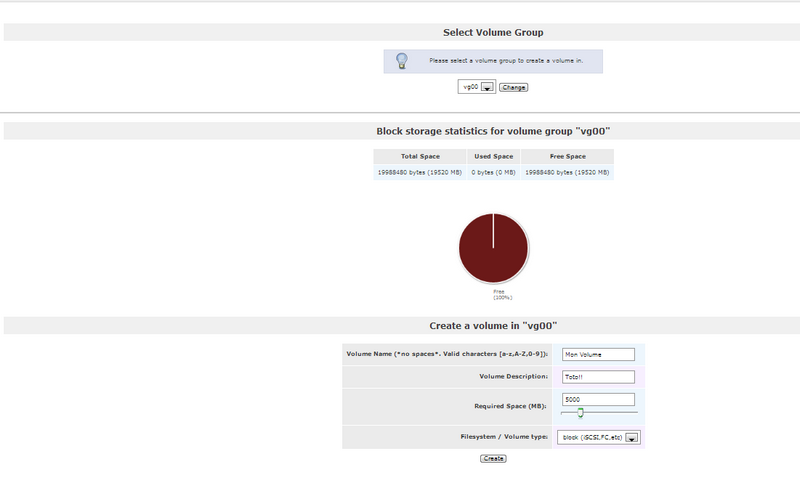
Renseignez le nom de votre volume ainsi l'espace que vous voulez lui allouer et cliquez sur "create".
Attention si vos Volume utilise le protocole ISCSI selectionnez "block" dans le menu déroulant "filesystem"
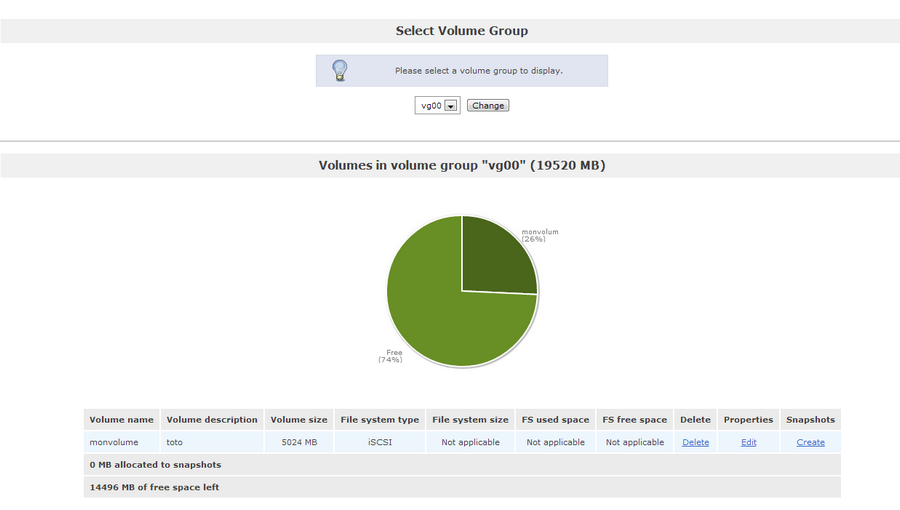
Cliquez sur l'onglet volume.
Ca y'est votre volume est pret! Vous pouvez augmenter ou diminuer sa taille à chaud. La gestion de Snapshots est également gérée par openfiler!
Cliquez sur edit puis sur iscsi target à droite de l'écran.
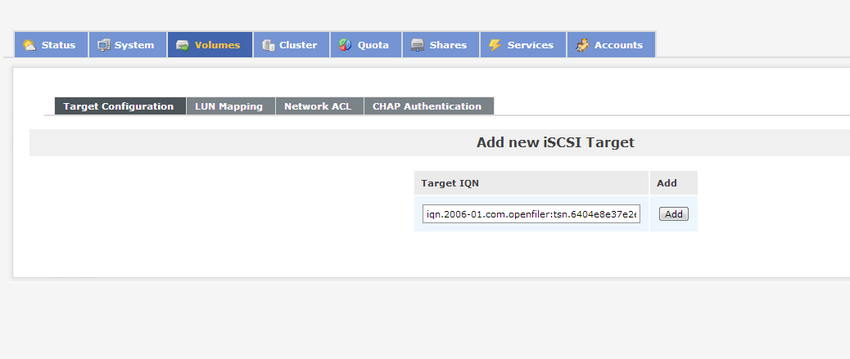
Cliquez sur le bouton add pour ajouter un "target iqn" qui vous sera indispensable pour connecter votre volume.
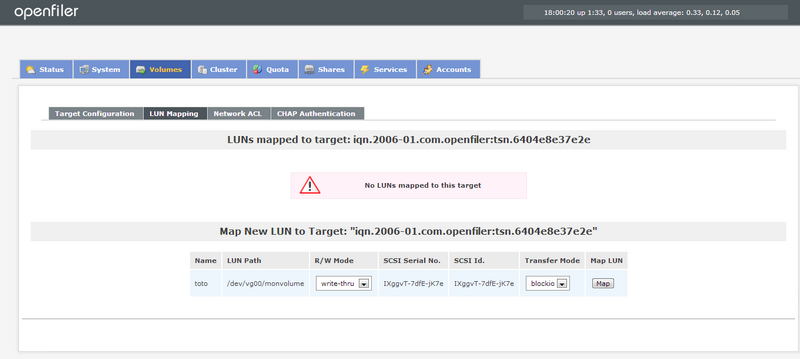
Cliquez sur map pour mapper votre Lun
Cliquez ensuite sur "update" en bas de la page.
Ça y'est votre SAN est opérationnel!!
Connaître la date d’installation d’un système Linux
Publiée le 31 Juillet 2013
Une info qui peut vous être utile est la date d'installation d'un système Linux (surtout si vous ne gérez pas les machines).
Cette commande liste tous les fichiers de configuration du répertoires /etc est récupère la date de la plus ancienne.
ls -lct /etc | tail -1 | awk '{print $6, $7, $8}'
[Tutoriel] Installation serveur collaboratif Zimbra
Article publiée le 25 Juillet 2013
Mise à jour le 30 Juillet 2013
I) Installation de Zimbra
Le projet OpenSource Zimbra attire mon attention depuis pas mal de temps.
Zimbra est un groupware ( Serveur collaboratif) regroupant un service de mail, un ldap et un service de calendrier totalement gratuit!!!
Cette solution est pour moi idéal pour les petites entreprises disposant de peu de moyens mais ayant des besoins plus important.
D'autres éditions de Zimbra payantes et propriétaires, sponsorisé par Vmware sont disponibles.
Ici le lien qui vous fournira le comparatif des éditions.
Ce tutoriel vous expliquera comment installer et configurer cette solution avec CentOS 6.4
Ce tutoriel prend en compte le fait que vous ayez un serveur DNS correctement configuré (notamment le MX)
* Configurer votre interface réseau avec une IP en statique et vérifier que SElinux est désactivé.
*Editez le fichier Hosts et rajoutez l'entrée (Seulement au cas ou vous ne disposez pas d'un serveur DNS):
<ip de votre machine> <nom long> <nom court>
Exemple:
192.168.0.23 zimbra.localdomain zimbra
 Si malgré une configuration correct de votre fichier Hosts (ou configuration DNS) l'installateur vous jette, vérifier la configuration de votre hostname via la commande hostname -f. Si aucun n'est défini initialisez le via la commande hostname <nom de votre machine>
Si malgré une configuration correct de votre fichier Hosts (ou configuration DNS) l'installateur vous jette, vérifier la configuration de votre hostname via la commande hostname -f. Si aucun n'est défini initialisez le via la commande hostname <nom de votre machine>
* Installez les prérequis nécessaire à l'installation de Zimbra:
yum install perl sysstat nc
*Telechargez zimbra:
wget http://files2.zimbra.com/downloads/8.0.4_GA/zcs-8.0.4_GA_5737.RHEL6_64.20130524120036.tgz
*Décompressez l'archive:
tar -xvf zcs-8.0.4_GA_5737.RHEL6_64.20130524120036.tgz
*Rendez vous dans le répertoire d'installation
cd zcs-8.0.4_GA_5737.RHEL6_64.20130524120036
*Lancez l'installation :
./install.sh
*Validez en tapant Y à chaque invite:
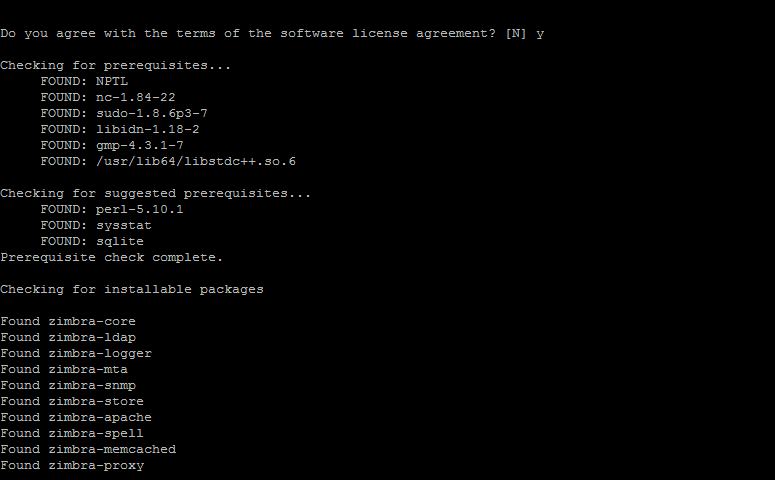
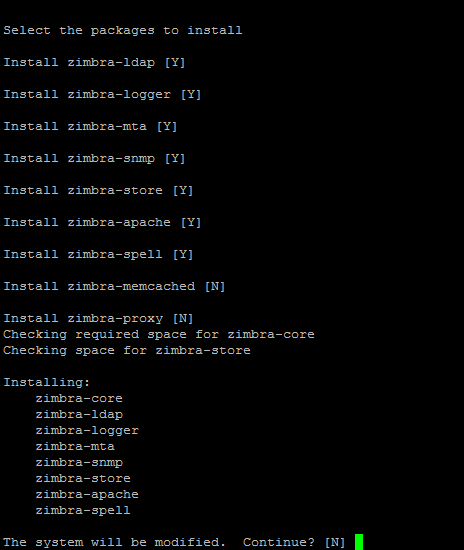
Tapez Y et validez pour lancer l'installation.
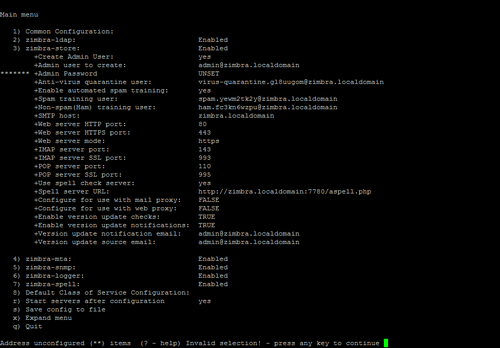
Une fois arrivé à cette écran:
- « adresse unconfigured » taper « 3 » pour initialiser le mot de passe de la console administrateur de zimbra
- select, ou « r » taper « 4 » toujours pour initialiser ce mot de passe
- taper le mot de passe qui sera celui du compte administrateur
- select, ou « r » taper « r » pour le menu précédent
- puis taper « a » pour appliquer
- et enfin taper « y » pour le « system will be modified »
Une fois l'installation terminée vous pouvez accéder à l'interface d'admin via l'url: https://<ip de votre serveur>:7071/
Le webmail de Zimbra est accessible via cette URL: https://<ip de votre serveur>
Utilisateur : admin@<domaine>
Mot de passe : Mot de passe configuré lors de l'installation
Pour démarrer ou stopper le service Zimbra: service zimbra start/stop/restart ou /etc/init.d/zimbra start/stop/restart
N'oubliez pas de stopper les services mails natifs de votre distrib (postfix sous Red-Hat ou exim4 sous debian) avant de démarrer Zimbra
L'interface d'administration de Zimbra est extrêmement intuitif.
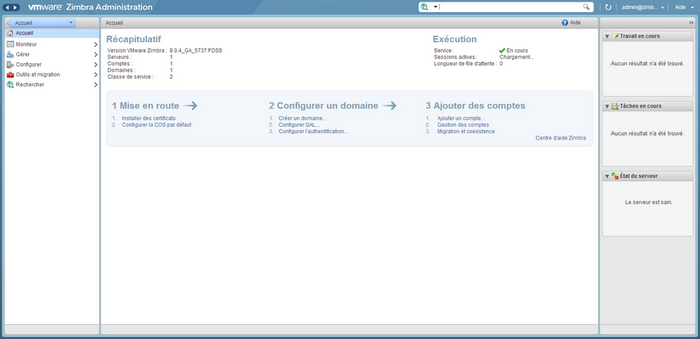
Pour commencer la configuration de votre serveur Zimbra il suffit de suivre le Wizard de configuration visible sur la page d'accueil ("Mise en route", "Configurer un domaine, "Ajouter des comptes).
enjoy 🙂
ESXI error loading /s.v00
Article publiée le 24 Juillet 2013
J'ai pu constater une erreur courante lors de l'installation de VmWare ESXI 4 ou 5 qui m'est tombée dessus récemment.
Lors du chargement des fichier .v00. il peut arriver que celui ci bloque sur /s.v00

En écumant la base de connaissance de VmWare j'ai fini par trouver la solution:
Dans les paramètre CPU du bios de votre serveur vous devez désactiver les paramètres suivants:
Adjacent Cache Line Prefetch == OFF
Hardware Prefetcher == OFF
Demand-based Power MGMT == OFF
Vous pouvez maintenant redémarrer votre installation 🙂
Augmenter la taille du swap
Article publiée le 10 Juillet 2013
Article mise à jour le 15 Mars 2016
En écumant les tutos sur internet j'ai trouvé tout et n'importe quoi sur la façon d'augmenter la taille d'un swap.
En effet il peut vous arriver, pour donner un peu d'air à votre système ou satisfaire des prérequis, de devoir augmenter la taille de votre Swap.
Il va s'en dire que toute vos partitions sont en LVM. Si ce n'est pas le cas je vous invite fortement à reconsidérer votre décision technique 😉
Ce lien vous emmènera vers un tuto que j'ai rédigé sur les LVM
Ce mini tuto explique la méthode la plus simple d'augmenter à chaud la taille d'un SWAP.
Avant de débuter, veillez à ce que votre système ne soit pas en train de swapper. Si tel est le cas il est préférable de stopper les services gourmand en mémoire.
-Désactivez le swap:
swapoff -v <chemin de votre partition swap>
Exemple : swapoff -v /dev/vg_root/lv_swap
-Augmenter la taille de votre LV
lvresize -L +<valeur de l'espace que vous voulez rajouter>g <chemin de votre partition swap>
Exemple: lvresize -L +16g /dev/vg_root/lv_swap
-Réactivez votre swap
swapon -va
-Vérifiez la nouvelle taille de votre swap via la commande "top"
Compression en multithreading (pigz & lbzip2)
Publiée le 01 Juillet 2013
La compression est extrêmement pratique! Seulement les délais de compression et de décompression peuvent vite devenir un cauchemar.
Lors d'une de mes précédentes mission cette problématique c'est très vite posée à l'un de mes collègues admin. La solution proposée par l'un d'eux a été des plus astucieuse!
La plupart des outils de compressions connus utilisent qu'un seul thread alors que de nos jours les serveurs gèrent de mieux en mieux le multithreading.
Pour ma part je trouve cela très dommage. Si vous avez des milliers d'archives à traiter, les méthodes conventionnelles risquent d'être vite limitées.
Mais encore une fois nos barbus ont pensés à tout!
PIGZ : Cette outil disponible dans tous les dépots officiels (installation via apt et yum) vous permet de gérer vos archives gzip bien plus rapidement que gunzip.
Pigz gère le multithreading et le gain en performance est non négligeable!
Ci dessous le Benchmark entre Gzip et Pigz::
Voici 10 fichiers de 10Mo chacun:
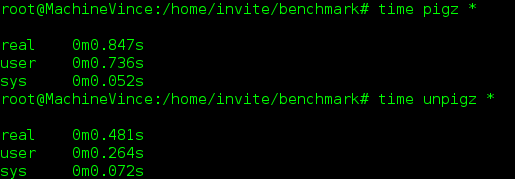
Les temps d’exécutions avec Pigz:
Et celle avec gzip:


Comme vous pouvez le constater Pigz est bien plus performant (et encore le test a été effectués avec un échantillon de dix fichiers de 10Mo, imaginez le gain de temps avec des milliers de fichiers!).
Site des développeurs: http://zlib.net/pigz/
LBZIP2 :
Ci-dessous le benchmark:
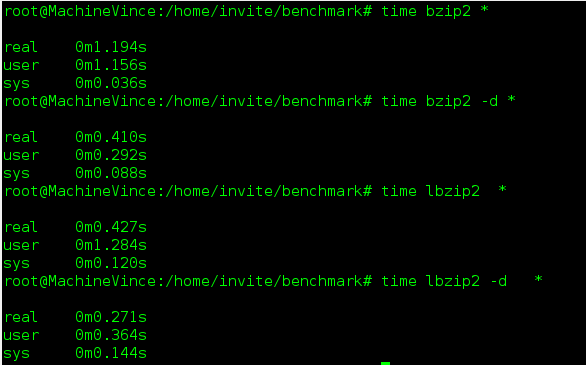
Beaucoup font l'éloge de PBZIP2 pour effectuer des compression en Bzip2 mais après des test j'ai pu m'apercevoir que LBZIP2 est beaucoup plus performant aussi bien en compression qu'en décompression.
Tout ces tests ont été effectuées sur une machine core i7, 8 Go de Ram avec une distribution Debian Wheezy. Les fichiers de tests ont été créés dans une partition EXT4.
Rotation des logs avec logrotate
Publiée le 26 Juin 2013
La gestion des logs est très importante. La problématique qui se pose très souvent à un admin est de gérer ses logs pour que celles-ci soient disponibles le plus longtemps possible sans saturer le stockage.
Logrotate est la solution idéal pour gérer les logs de vos service UNIX.
Logrotate permet d'archiver vos logs, de les compresser et d'effectuer des purges automatiques. La puissance de logrotate réside dans le fait qu'il peut archiver vos logs même quand celles ci sont en cours d'écriture!
Pour configurer logrotate allez dans le répertoire /etc/logrotate.d
Ce répertoire contient la configuration de la rotation des logs pour chaque service.
Admettons que nous voulons gérer les logs du service "toto":
- Créer un fichier toto dans le répertoire /etc/logrotate.d
-Editez le et ajoutez la configuration suivante:
# Indiquez le chemin de votre log
<chemin de votre fichier log> {
#Ne supprime pas le fichier mais vide le fichier log après en avoir fait une copie
copytruncate
# Logrotate analysera l'état de vos logs de manière journalière (vous pouvez spécifier weekly ou monthly pour chaque semaine ou chaque mois)
daily
# Logrotate conservera 7 archives
rotate 7
#Les logs seront compressées
compress
#Ne produit pas d'erreur si votre log n'existe pas
missingok
# Logrotate archivera votre log uniquement si la taille dépasse les 100M
size 100M
}
Enjoy 🙂
[TOMCAT] SEVERE: Failed to initialize java.lang.OutOfMemoryError: PermGen space
Publiée le 13 Juin 2013
Java est très très gourmand en ressource. L'administration des serveurs hébergeant des applications JAVA est un travail ardue.
Un problème que j'ai rencontré sur plusieurs serveurs tomcat durant mes différentes mission est le fameux :
Failed to initialize java.lang.OutOfMemoryError: PermGen space
Etant encore novice dans la gestion des environnements JAVA je suis resté assez perplexe devant un tel message d'erreur.
Je check mon fichier startup.sh pour voir si mon xmx et xms sont bien paramétrés:
export JAVA_OPTS="-Djava.awt.headless=true -Dfile.encoding=UTF-8
-server -Xms2048m -Xmx2048m"
La solution est d'augmenter le Maxpermsize (qui correspond à la mémoire allouée aux process java non géré par le garbage collector dit ramasse miette).
Pour résoudre le problème il suffit de paramétrer votre JAVA_OPTS de la façon suivante:
export JAVA_OPTS="-Djava.awt.headless=true -Dfile.encoding=UTF-8
-server -Xms2048m -Xmx2048m
-XX:NewSize=256m -XX:MaxNewSize=256m -XX:PermSize=256m
-XX:MaxPermSize=256m -XX:+DisableExplicitGC"
Présentation de BTRFS et comment migrer
Article publié le 9 Juin 2013
Mise à jour le 02 Décembre 2015
Présentation
BTRFS est un des dernier système de fichier révolutionnaire (développé principalement par Oracle et RedHAT) qui devrait remplacer à terme EXT4.
Il n'apporte pas réellement de gain en performance mais sa force réside dans ses fonctionnalités.(vous pourrez noter néanmoins un léger gain en performance à partir du Noyau 3.6)
J'ai été impressionné par les possibilités qu'offre BTRFS en terme d'administration:
- Création de SnapShot
- Meilleur gestion de l'intégrité des données ( Somme de controle)
- Compression en natif
- Sauvegarde incrémental intégrée au système de fichier
- Défragmentation à chaud
- Création de sous volumes
De plus le système de fichier BTRFS est optimisé pour la gestion des petits fichiers. En effet si vous avez un nombre très important de petits fichiers vous gagnerez en place et en performance par rapport à un système de fichier de type EXT3/EXT4
Création d'une nouvelle Partition
Pour formater une partition en btrfs, rien de plus simple.
mkfs.btrfs <votre fs>
Migration
Dans un premier temps il est nécessaire d'installer btrfs-tools sous Debian ou btrfs-progs sous Red-Hat. (comme à mon habitude et pour des raisons idéologique ;-), mes tests sont effectués sur une Debian tout en essayant de m'adapter au maximum pour les utilisateurs de RedHat/CentOS).
# apt-get install btrfs-tools (sous Debian) ou yum install btrfs-progs (Sous RedHAT)
- Convertissons un système de fichier EXT4 vers BTRFS
Pour cela démontez votre volume:
#umount <votre fs>
Utilisez la commande btrfs-convert pour convertir votre FS EXT4 en BTRFS:
#btrfs-convert <votre fs>
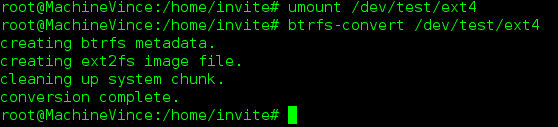
N'oubliez pas de modifier votre fstab en remplacant EXT4 par btrfs.
- Remontez votre fs avec un mount -a
Présentation des fonctionnalités
1) Création de sous volume
Cette fonctionnalité est absolument génial, elle vous facilitera la vie en terme d'administration!
Pour créer un sous volume:
# btrfs subvolume create <votre-nom-sous-volume>
Pour supprimer un sous volume:
#btrfs subvolume delete <votre-nom-sous-volume>
2) Les SnapShots
Créer un Snapshot:
Le système de snapshot est très abouti. Il vous permet de prendre "une image" de votre sous volume. En cas de problème (perte de fichier ou autre) vous pourrez recharger votre snapshot pour récupérer l'état de votre volume au moment ou le snapshot a été pris. (similaire aux snapshot de machine virtuel même si le fonctionnement est différent).
#btrfs subvolume snapshot <nom de votre sous volume> <nom de votre snapshot>
Cette commande créera un répertoire à la racine de votre FS. Ce répertoire correspondra à votre snapshot et contiendra toute votre arborescence avec son contenu.
Restaurer un Snapshot:
Rien de plus simple! Il suffit de faire un mv du répertoire de votre snapshot vers le le sous Volume à restaurer!
Autosnap:
Cette petite fonctionnalité vous permettra de faire des Snapshot automatiques, très utile pour sécuriser vos données.
#btrfs autosnap enable -m <fréquence de snapshots en minute> -c <Nombre de snapshots en rétention (roulement)> <votre sous volume>
Exemple:
#btrfs autosnap enable -m 30 -c 10 <votre sous volume> </btrfstest/toto>
Dans cette exemple un SnapShot sera effectué toutes les 30 minutes sur le sous volume "toto". Un historique de 10 SnapShots sera conservé!
Vous pouvez même aller plus loin. Admettons que vous soyez rik rak niveau stockage vous pourrez faire en sorte que vos plus anciens SnapShot soientt supprimés au bout d'un certain seuil d'occupation d'espace disque
#btrfs au fslimit -n <% d'espace disque occupé> <Votre sous volume>
En conclusion le système de Snapshot est extrêmement performant et présente un très bon complément avec vos sauvegardes journalières.
(Dans le cas typique où vous créez un fichier dans la journée et que vous le supprimez par erreur avant la sauvegarde)
3) La compression
Btrfs prend nativement en charge la compression
Pour cela deux étapes sont nécessaires
- On modifie le fstab en conséquence:
Exemple:
<votre fs> <point de montage> btrfs defaults,compress 0 1
-on compresse soit avec lzib (Meilleur compression mais plus gourmand en CPU) ou lzo (Plus économe en ressource mais moins bonne compression):
compress=<algo de compression>
Migrer ext3 vers ext4
Article publié le 7 Juin 2013
Ext4 est un sytème de fichier qui possède beaucoup d'avantages :
- Vitesse d'écriture multiplié par 2!
- Possibilité de créer des FS allant jusqu'a 16Eo (Exa octet)
- Possibilité de générer des fichiers jusqu'à 16To
- Beaucoup moins de chance d'avoir des données corrompus en écriture.
- Et beaucoup d'autres avantages!!!
J'ai entendu pas mal de gens dire que EXT4 n'est pas fiable ou qu'il présente des risques: ce sont des foutaises!!!! EXT4 est plus fiable que EXT3 donc faites vous plaisir!
J'ai noté une grosse amélioration des performances des base de données (Oracle et MySQL) ayant leur tablespace sur des FS en EXT4(vos DBA n'en seront que plus heureux!)
Si vous décidez de faire des tests de performance, je vous conseille de les effectuer uniquement avec un noyau en version 2.6.32-X. En effet les noyaux plus anciens (à partir de 2.6.18-x) supportent l'EXT4 mais ne sont pas optimisés pour en tirer le plein potentiel. (Mais rien ne vous empêche de migrer pour tirer profit des autres avantages de ce système de fichier)
Maintenant une problématique: la migration.
Heureusement nos chers barbus ont pensés s à tout! Il est en effet possible de migrer à chaud vos données sans effectuer une migration lourde (suppression et création d'un nouveau FS)
Ci-dessous la procédure:
Pour les utilisateurs de RedHat/Centos ayant une version antérieur à la 6.0 installez le paquet suivant:
e4fsprogs (yum install e4fsprogs)
-Démontez le lecteur à migrer:
# umount <fsck -pf /dev/sdb1votre point de montage>
-Ajustons les paramètres de votre FS pour le passage en EXT4:
#tune2fs -O extents,uninit_bg,dir_index /<votre FS>
-Vérifiez la cohérence de votre FS:
#fsck -pf /<votre fs>
-Modifiez votre fstab en remplacant "ext3" par "ext4" sur la ligne correspondante au FS que vous avez modifié
-Monter votre FS
#mount -a
Faites un df -T pour vérifier que votre FS est bien en EXT4 (juste pour la conscience ;-))
NB : Dans mon prochain article je vous parlerai un peu de btrfs
apticron : notification des mises à jours debian
Article publié le 1 Juin 2013
Pour moi un bon admin doit toujours être averti des dernière mises à jour de son OS.
Un petit outil très sympathique nommé apticron permet d'être averti par mail dés que de nouvelles mises à jour sont disponibles! Egalement très pratique dans le cas ou vous administrez beaucoup de serveur pour savoir l'état des mises à jours de chacun d'entre eux.
Le contenu des mails est très détaillé car il vous donne toutes les mises à jours non installé sur votre machine avec le détail de ses corrections, sa date de publication ainsi que le nom du développeur.
Cette outil est codé en Shell par un membre de la communauté Debian et je dois dire que je suis assez admiratif du travail!
Vous devez avoir un sender mail type postfix ou sendmail configuré pour que apticron soit capable d'envoyer des mails.
Pour installer cette outil :
#apt-get install apticron
Le fichier de configuration apticron se situe dans /etc/apticron/apticron.conf
Editons le:
#vi /etc/apticron/apticron.conf
Vous pourrez constater que le fichier de configuration est bien garni mais seulement trois lignes nous intéresserons:
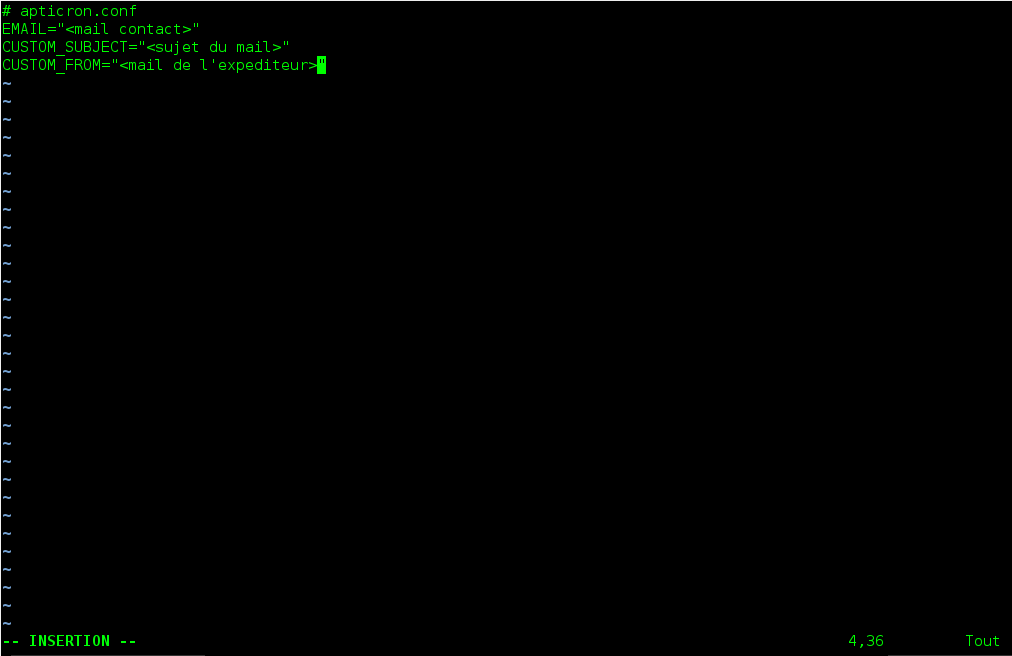
Une fois votre configuration effectuée enregistrez votre fichier.
Lancez apticron:
# apticron
Si votre configuration est correct vous devriez recevoir un mail dans votre boite de messagerie avec la liste de toutes les nouvelles mises à jours disponible.
Par défaut apticron est configuré pour vous envoyer des mails tous les jours en cas de nouvelles mises à jours. Si vous installez cette outil sur tous vos serveurs, la situation peu vite devenir ingérable (SPAM ;-)).
Pour cela je vous suggère une notification hebdomaraire:
# rm /etc/cron.d (on supprime le cron journalier)
# cd /etc/cron.weekly && ln -s /usr/sbin/apticron apticron (on crée un lien symbolique du cron hebdomadaire vers le binaire d'apticron)
Outil de monitoring HP UX glance
Article publié le 30 Mai 2013
Tout admin à sa bête noir, une situation qu'il redoute.
Ma bête noire à moi s'appelle HP UX. Franchement j'ai toujours eu énormément de mal avec cette OS qui est pourtant extrêmement puissant (quand il est bien administré).
Ayant déjà eu l'opportunité de travaillé sur cette OS, j'ai pu malgré tout relever des outils très puissant made in HP.
Glance a particulièrement retenu mon attention.
Exemple: capture d'écran avec glance -m permettant de monitorer votre consommation mémoire.
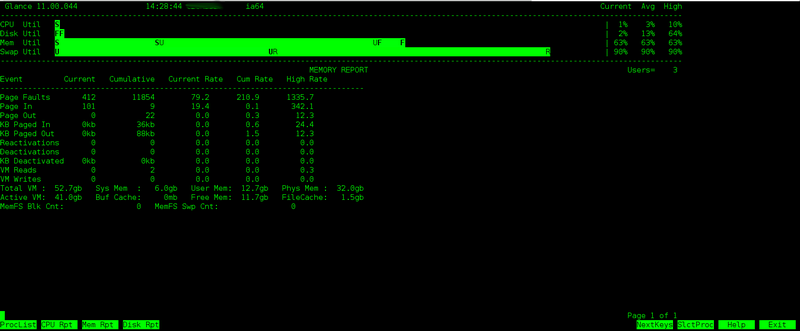
glance -d : monitoring de disque
glance -c: monitoring CPU
glance -a : Average cpu load par unité de calcul
glance -v : monitoring de vos Volume group (I/O)
glance -u : monitoring de vos disques
glance -l : monitoring de vos interfaces réseaux
glance -g : monitoring de vos process
glance -A : Monitoring par application
Franchement cette outil est extrêmement puissant et vous permettra d'avoir une vue rapide de votre système en 2 temps 3 mouvements.
Si vous êtes vraiment séduit par cette outil vous pourrez trouver une version pour Linux.
Malheureusement glance est un produit propriétaire ce qui implique que si vous voulez l'obtenir pour un autre système que HPUX il vous faudra passer par la case achat...
