Tutoriel | Configurer la réplication master/slave d’une instance PostgreSQL
Article publié le 7 Septembre 2018
Un petit tutoriel sur la manière la plus facile de mettre en place une réplication Master/Slave d’une instance PostgreSQL. Une réplication Master/Slave est extrêmement utile. Elle vous permettra d’avoir un failover et donc une continuité de service en cas de perte de votre master mais également de répartir la charge en redirigeant toute les requête read-only (select) sur votre slave.
Dans ce tutoriel, deux instances PostgreSQL seront installées sur deux machines distinctes.
 La version utilisée lors de la rédaction de ce tutoriel est la version 10. Si vous utilisez une version différente de postgresql, ce tutoriel sera toujours valable, seul le chemin du répertoire d’installation de postgresql et certaines commandes changeront légèrement.
La version utilisée lors de la rédaction de ce tutoriel est la version 10. Si vous utilisez une version différente de postgresql, ce tutoriel sera toujours valable, seul le chemin du répertoire d’installation de postgresql et certaines commandes changeront légèrement.
1) Configuration du Master
– Éditez votre fichier postgresql.conf (sa localisation diffère en fonction de la distribution et de la version de PostgreSQL installé) et faites les modifications suivantes:
listen_addresses = ‘*’
wal_level = hot_standby
max_wal_senders = <nombre de noeuds dans votre cluster> # Logiquement 2 dans notre cas master/slavesynchronous_standby_names = ‘<hostname du master>’wal_keep_segments = 100
– Créez un user dédié à la réplication via cette requête SQL:
create user replica replication;
– Éditez le fichier pg_hba.conf et rajoutez la ligne suivante (permettant ainsi la connexion de votre slave sur votre master):
host replication replica <ip de votre slave> trust
– Redémarrez enfin votre service PostgreSQL
2) Configuration du Slave
– Arrêtez votre instance PostgreSQL.
– Supprimez tout le contenu du répertoire data situé dans le répertoire d’installation de votre instance PostgreSQL
– Lancez la commande suivante afin d’établir le lien avec votre master:
pg_basebackup -D <pgsql_path>/data -h <ip ou fqdn du master> -U replica
– Éditez ou créez si il n’existe pas déja le fichier recovery.conf situé dans le répertoire data et ajoutez y les lignes suivantes:
standby_mode=ontrigger_file=’/tmp/promotedb’primary_conninfo=’host=<ip ou fqdn du master> port=5432 user=replica application_name='<valeur de synchronous_standby_name indiqué dans le postgresql.conf du master>’
– Changez le owner du répertoire data (suite à sa précédente suppression celui ci a été recréé avec le user root):
chown -R postgres:postgres <pgsql_path>/data
hot_standby=on
/usr/pgsql/bin/pg_ctl-10 -D /var/lib/pgsql/10/data start
3) Test
Afin de rédiger ce tuto j’ai utilisé 2 machines: vdahmane5 comme master et vdahmane6 comme slave.
Pour tester, j’ai créé une nouvelle base de données sur le master:
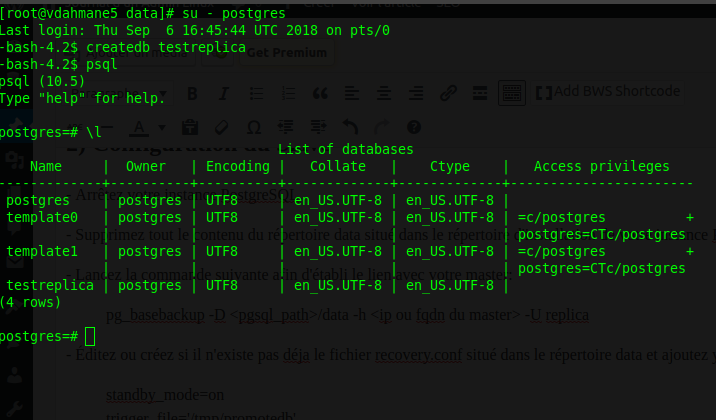
Je me connecte ensuite sur le slave et vérifie que la création de la base « testreplica » a bien faite:
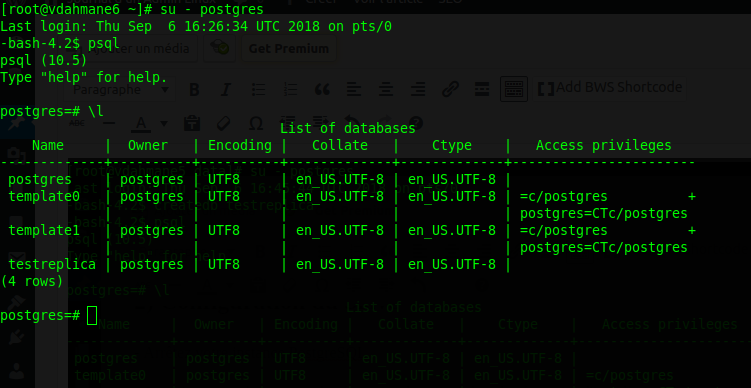
La réplication fonctionne!
Attention toutefois, si jamais des données sont directement insérées dans le slave, votre réplication sera par terre. Il vous faudra la reconstuire.