Tutoriel | Héberger son IA locale avec Ollama et lui apprendre vos données (RAG) sans exploser son serveur !
Article publié le 28 Février 2026
Salut à tous !
Aujourd’hui, on va s’attaquer à un gros morceau, mais on va le faire à notre sauce d’admin sys : proprement, en local, et sans dépendre du cloud.
Vous en avez marre d’entendre parler d’IA tout en sachant que la moindre question posée à ChatGPT envoie vos données internes, vos docs techniques ou les infos de votre boîte directement sur des serveurs aux États-Unis ? Moi aussi.
La bonne nouvelle, c’est qu’héberger son propre LLM (Large Language Model) n’est plus réservé à ceux qui ont 15 000 € à mettre dans un cluster de GPU. Aujourd’hui, on va voir comment déployer Ollama sur une simple VM Linux (un petit 4 vCPUs / 16 Go de RAM fera l’affaire), et surtout, on va voir comment lui injecter vos propres données grâce à la magie du RAG (Retrieval-Augmented Generation).
Accrochez vos ceintures, on va se monter un chatbot souverain et ultra-léger !
1. Ollama : Le « Docker » des modèles d’IA
Si vous savez utiliser Docker, vous savez utiliser Ollama. C’est un outil écrit en Go qui simplifie à l’extrême le téléchargement et l’exécution de modèles d’IA en local. Il gère la RAM, le CPU, et expose même une API REST compatible avec celle d’OpenAI. Que demander de plus ?
Installation
Sur votre distribution Linux préférée (Debian, Ubuntu…), l’installation se fait via un script officiel. Oui, je sais, on n’aime pas trop les curl | bash, mais ici c’est l’outil officiel et il configure tout le service systemd proprement.
curl -fsSL https://ollama.com/install.sh | sh
Vérifions que le démon tourne correctement :
systemctl status ollama

Télécharger et lancer un modèle
Pour notre VM sans carte graphique, on va éviter les modèles obèses à 70 milliards de paramètres. On va partir sur Gemma 3 (1B) Il est bluffant et tourne parfaitement sur CPU.
# On télécharge et on lance le modèle interactif ollama run gemma3:1b
Boum ! Vous avez un prompt interactif. Vous discutez avec une IA qui tourne à 100% sur votre machine. Pour sortir, faites un petit /bye.
Par défaut, Ollama écoute sur le port 11434 en local. Vous pouvez tester son API avec un simple curl :
curl http://localhost:11434/api/generate -d '{ "model": "gemma3:1b", "prompt": "Explique-moi ce qu'est un hyperviseur en une phrase.", "stream": false }'

C’est cool, mais ce modèle a un défaut : il ne connaît rien de VOUS. Il ne connaît pas vos procédures internes, ni votre wiki, ni les tarifs de votre boîte. C’est là qu’entre en jeu le RAG.
2. Le RAG : Donner un cerveau métier à votre IA
Plutôt que d’essayer de ré-entraîner le modèle avec vos données (le fameux fine-tuning, qui coûte un bras en puissance de calcul et qui est une galère à maintenir), on utilise le RAG (Retrieval-Augmented Generation).
Le concept est brillant de simplicité :
-
On découpe vos documents (fichiers TXT, PDF, Markdown) en petits morceaux.
-
On transforme ces morceaux en vecteurs (une suite de chiffres) et on les stocke dans une petite base de données.
-
Quand l’utilisateur pose une question, on cherche les morceaux de vos documents qui s’en rapprochent le plus.
-
On envoie ces morceaux à Ollama en lui disant : « Voici des infos de mon wiki interne. Utilise-les pour répondre à cette question : … »
C’est l’équivalent de donner un livre ouvert à un étudiant pendant un examen.
3. Pratique : Le script RAG « Admin-Friendly » (Ultra-Light)
Beaucoup de tutos vous diront d’installer l’usine à gaz LangChain ou le monstrueux PyTorch (qui va vous bouffer 4 Go d’espace disque). Sur Journal d’un admin Linux, on aime quand c’est slim.
On va écrire un script Python qui n’utilise que l’API de notre serveur Ollama (pour la génération ET pour la vectorisation) et une minuscule base de données appelée ChromaDB.
Les prérequis
Sur votre machine, on télécharge un modèle spécialisé d’Ollama (minuscule et ultra-rapide) pour créer nos vecteurs :
ollama pull nomic-embed-text
Puis on installe les deux seules dépendances Python nécessaires :
pip3 install requests chromadb
Vos données
Créez un fichier wiki_interne.txt avec quelques infos factices pour le test :
Serveur d’impression : L’IP du serveur d’impression de l’étage 2 est 192.168.1.50. Il faut utiliser le driver générique PCL6.
VPN : Pour se connecter au VPN de l’entreprise, le port utilisé est le 1194 en UDP. Le certificat doit être renouvelé tous les ans.
Serveur Web : Notre site principal tourne sous Nginx sur le serveur SRV-WEB-01 (Debian 12).
Le Script Python : rag_local.py
Voici notre script fait maison. Il est agnostique, rapide, et ne fait pas exploser la RAM.
import requests
import chromadb
import argparse
# --- CONFIGURATION ---
URL_OLLAMA = "http://localhost:11434"
MODEL_IA = "gemma3:1b" # Modèle qui rédige la réponse
MODEL_VECTEUR = "nomic-embed-text" # Modèle qui lit le document
def get_embedding(text):
""" Demande à Ollama de transformer le texte en suite de nombres (vecteurs) """
res = requests.post(f"{URL_OLLAMA}/api/embeddings",
json={"model": MODEL_VECTEUR, "prompt": text})
return res.json()["embedding"]
def interroger_mon_ia(question, fichier_txt):
try:
# 1. On charge notre fichier de doc interne
with open(fichier_txt, 'r', encoding='utf-8') as f:
contenu = f.read()
# On découpe grossièrement par paragraphes
paragraphes = [p.strip() for p in contenu.split('\n') if len(p.strip()) > 10]
# 2. Création de notre base de données vectorielle (en RAM pour la vitesse)
db_client = chromadb.Client()
collection = db_client.get_or_create_collection(name="mon_wiki")
# 3. On injecte nos paragraphes dans la base via Ollama
print(f"[*] Indexation de {len(paragraphes)} blocs de texte en cours...")
for i, texte in enumerate(paragraphes):
vecteur = get_embedding(texte)
collection.add(ids=[str(i)], embeddings=[vecteur], documents=[texte])
# 4. Recherche magique : on trouve les infos liées à la question !
vecteur_question = get_embedding(question)
resultats = collection.query(query_embeddings=[vecteur_question], n_results=1)
contexte_trouve = "\n".join(resultats['documents'][0])
# 5. On demande à l'IA de faire une synthèse avec NOS infos
prompt = (
f"Tu es un admin sys expert. Utilise UNIQUEMENT le contexte ci-dessous pour répondre.\n"
f"CONTEXTE INTERNE :\n{contexte_trouve}\n\n"
f"QUESTION : {question}\n\n"
f"RÉPONSE :"
)
res_ia = requests.post(f"{URL_OLLAMA}/api/generate",
json={"model": MODEL_IA, "prompt": prompt, "stream": False})
return res_ia.json().get('response', 'Erreur de génération')
except Exception as e:
return f"Erreur critique : {str(e)}"
# --- EXÉCUTION ---
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Interrogez vos docs locales avec l'IA")
parser.add_argument("question", type=str, help="Votre question")
parser.add_argument("-f", "--fichier", type=str, default="wiki_interne.txt", help="Fichier source")
args = parser.parse_args()
reponse = interroger_mon_ia(args.question, args.fichier)
print(f"\n[RÉPONSE DE L'IA] :\n{reponse}")
Il ne reste plus qu’à poser une question ultra-spécifique à notre script depuis le terminal :
python3 rag_local.py "Sur quel port tourne notre VPN ?"
Sortie :
[*] Indexation de 3 blocs de texte en cours... [RÉPONSE DE L'IA] : 1194 en UDP !

💥 Bim ! L’IA ne vous a pas fait une réponse générique copiée sur Wikipédia, elle a lu votre fichier de configuration et vous a répondu avec vos données. Le tout sans qu’un seul octet n’ait quitté votre serveur en bare-metal ou votre VM.
Conclusion
L’association d’Ollama (pour l’inférence) et d’un petit script Python avec ChromaDB (pour le RAG) est une véritable tuerie. C’est robuste, ça consomme peu de ressources disque par rapport aux grosses stacks d’IA habituelles, et ça ouvre la porte à des dizaines d’usages :
-
Un chatbot d’entreprise qui interroge vos logs ou vos manuels de procédures.
-
Une API (en rajoutant un peu de FastAPI par dessus) pour le support IT interne.
-
Une solution d’IA à proposer à vos clients, sans les soucis liés au RGPD !
Et vous, vous l’hébergez où votre IA ? Dites-le-moi en commentaire ou venez en discuter avec nous sur le réseau !


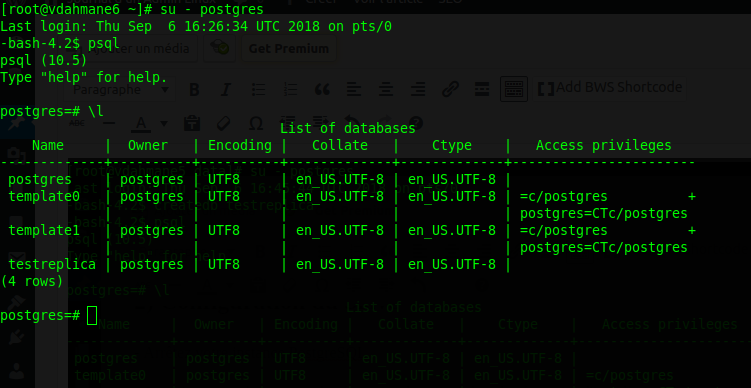
 La version utilisée lors de la rédaction de ce tutoriel est la version 10. Si vous utilisez une version différente de postgresql, ce tutoriel sera toujours valable, seul le chemin du répertoire d’installation de postgresql et certaines commandes changeront légèrement.
La version utilisée lors de la rédaction de ce tutoriel est la version 10. Si vous utilisez une version différente de postgresql, ce tutoriel sera toujours valable, seul le chemin du répertoire d’installation de postgresql et certaines commandes changeront légèrement.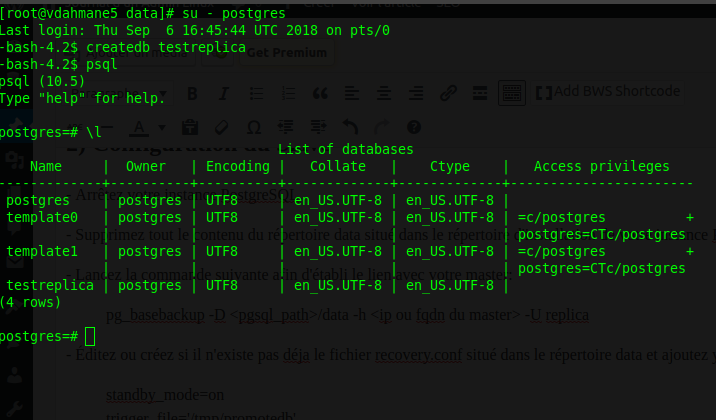








 A adapter selon la version de votre Debian (à l’heure ou cet article a été écrit, la 9 n’est pas encore sortie en version stable). De plus la version de opennebula (dernière version en date de cet article: 5.4) est à adapter dans le lien (deb http://downloads.opennebula.org/repo/<version opennebula>/Debian/8 stable opennebula)
A adapter selon la version de votre Debian (à l’heure ou cet article a été écrit, la 9 n’est pas encore sortie en version stable). De plus la version de opennebula (dernière version en date de cet article: 5.4) est à adapter dans le lien (deb http://downloads.opennebula.org/repo/<version opennebula>/Debian/8 stable opennebula)