Tutoriel | Découverte de Prometheus et Grafana
Article publié le 28 Décembre 2018
Je profite du calme des fêtes de fin d’année pour vous faire partager ma veille techno sur l’outil de supervision Prometheus. Cet outil de supervision est l’un des plus puissants que j’ai pu tester! Dans ce tutoriel, vous trouverez toutes les manipulations que j’ai faites pour tester ce produit. Durant mes tests, je me suis servis de deux machines. L’une hébergeant prometheus et Grafana et la seconde qui hébergera les services à monitorer.
Je vais expliquer dans un premier temps comment installer Prometheus. Ensuite, je vais superviser une machine Linux hébergeant un service Apache et une base de données Mysql.
Enfin, je brancherai un Grafana sur mon prometheus pour avoir de jolies graph!
1) Fonctionnement de Prometheus

Prometheus récupère toutes les metric de ce que vous voulez monitorer grâce à un composant qui s’appelle « Exporter ». En gros considérez l’exporter comme un agent de monitoring classique.
Le gros avantage est qu’il existe un exporter pour quasiment tout! Vous pouvez trouver la liste des exporter ci-dessous:
https://prometheus.io/docs/instrumenting/exporters/
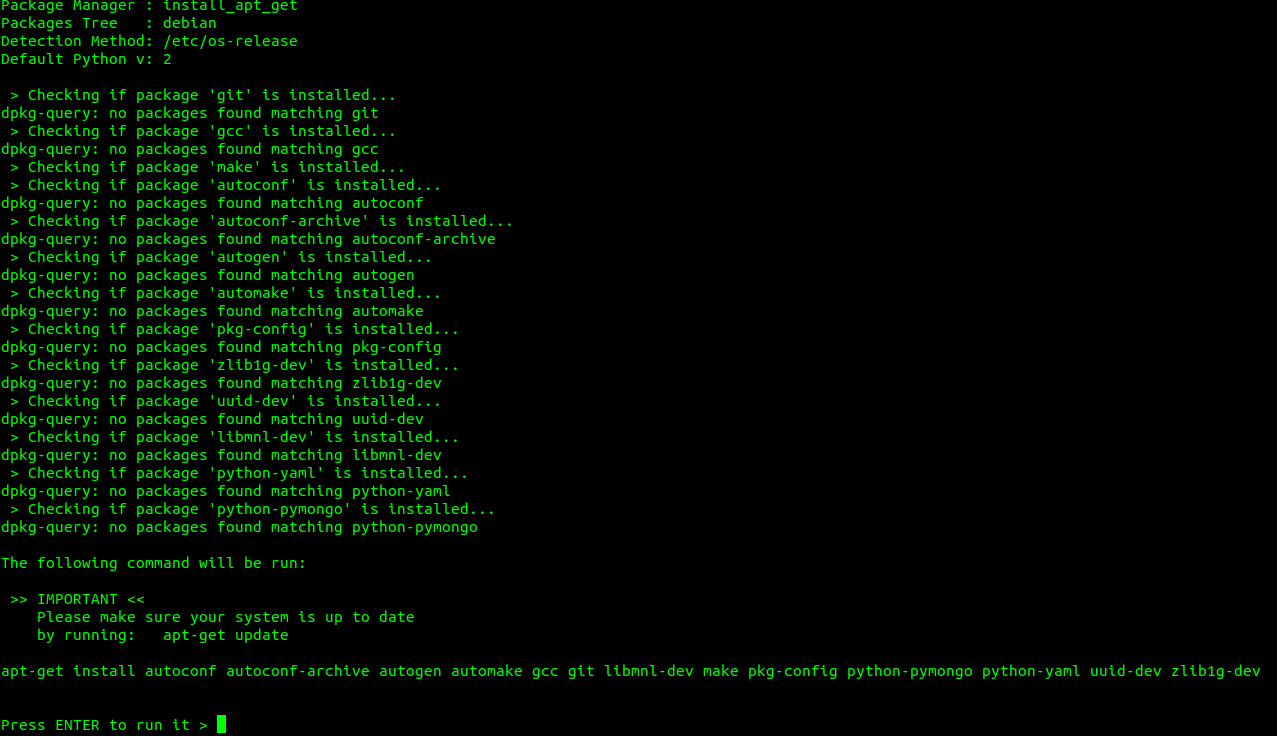
2) Installation et configuration de prometheus
– Téléchargez la dernière version des sources de prometheus:
https://prometheus.io/download/
– Décompressez l’archive
tar -xvf prometheus-* && cd prometheus-*
– Éditez le fichier prometheus.yml et remplacez le contenu par la configuration suivante:
global:
scrape_interval: 15s
evaluation_interval: 15srule_files:
# – « first.rules »
# – « second.rules »scrape_configs:
– job_name: prometheus
static_configs:
– targets: [‘localhost:9090’]
– Lancez Prometheus (en mode crado mais rien ne vous empêche de faire un service systemd propre! 😉 )
./prometheus –config.file=prometheus.yml
– On va ensuite créer un reverse proxy apache afin de pouvoir afficher l’interface Web de prometheus bindé sur le localhost (installez apache2 et activez le mode proxy)
Ci-dessous le contenu du virtualHost (j’ai renseigné mon fichier host pour faire pointer prometheus.local vers l’ip de ma machine)
<VirtualHost *:80>
ServerName prometheus.local
CustomLog ${APACHE_LOG_DIR}/prometheus.local.log combined
ErrorLog ${APACHE_LOG_DIR}/prometheus.local-error.log
LogLevel warnProxyPreserveHost On
ProxyPass / http://localhost:9090/
ProxyPassReverse / http://localhost:9090/</VirtualHost>
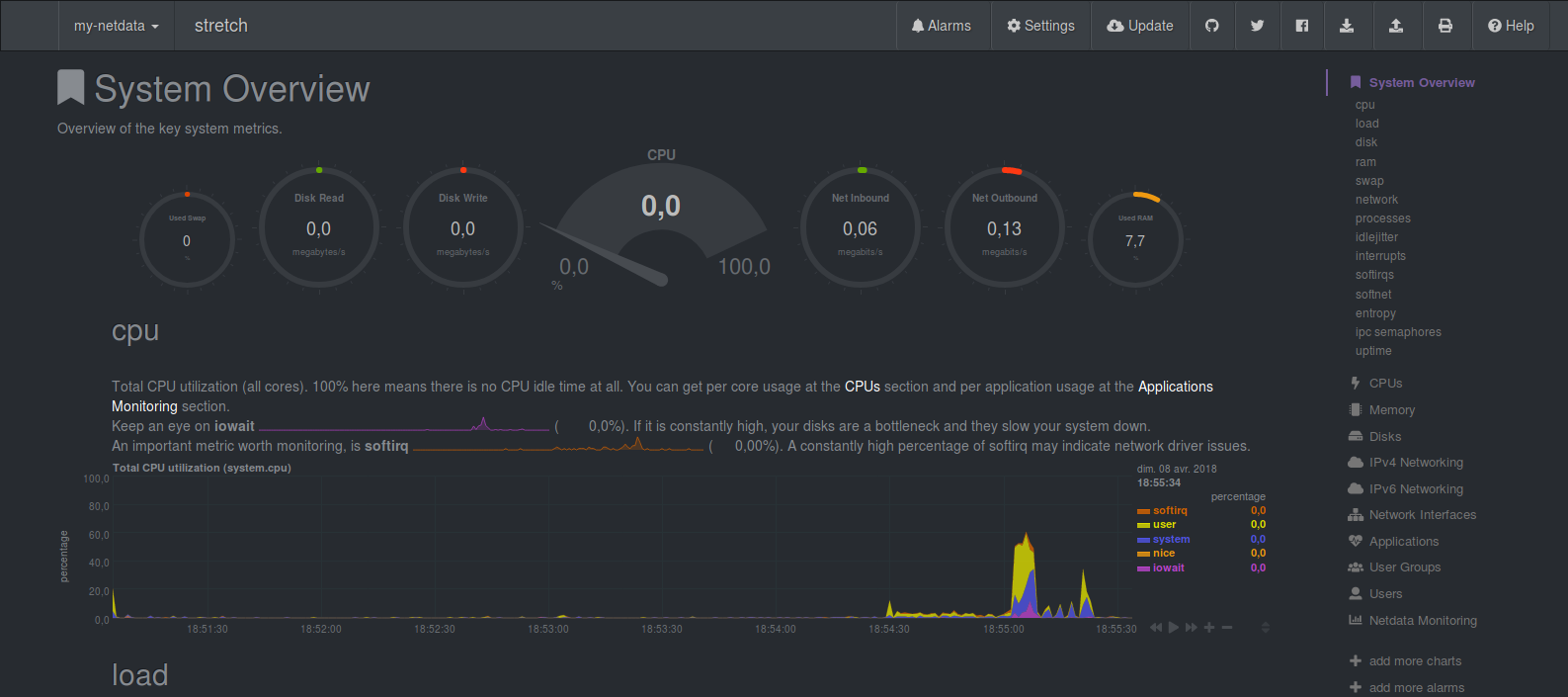
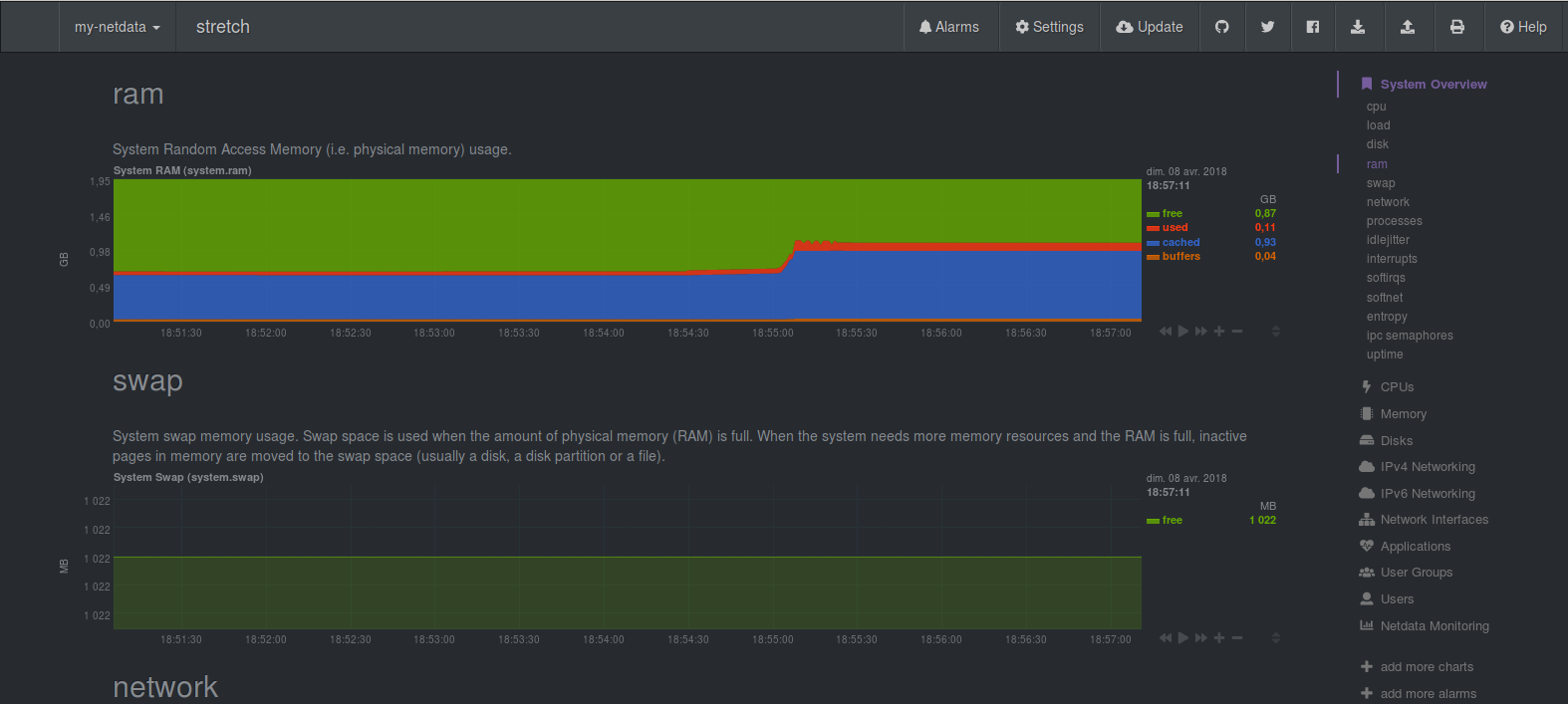
– Si tout s’est bien passé vous devriez pouvoir afficher l’interface Web de Prometheus:
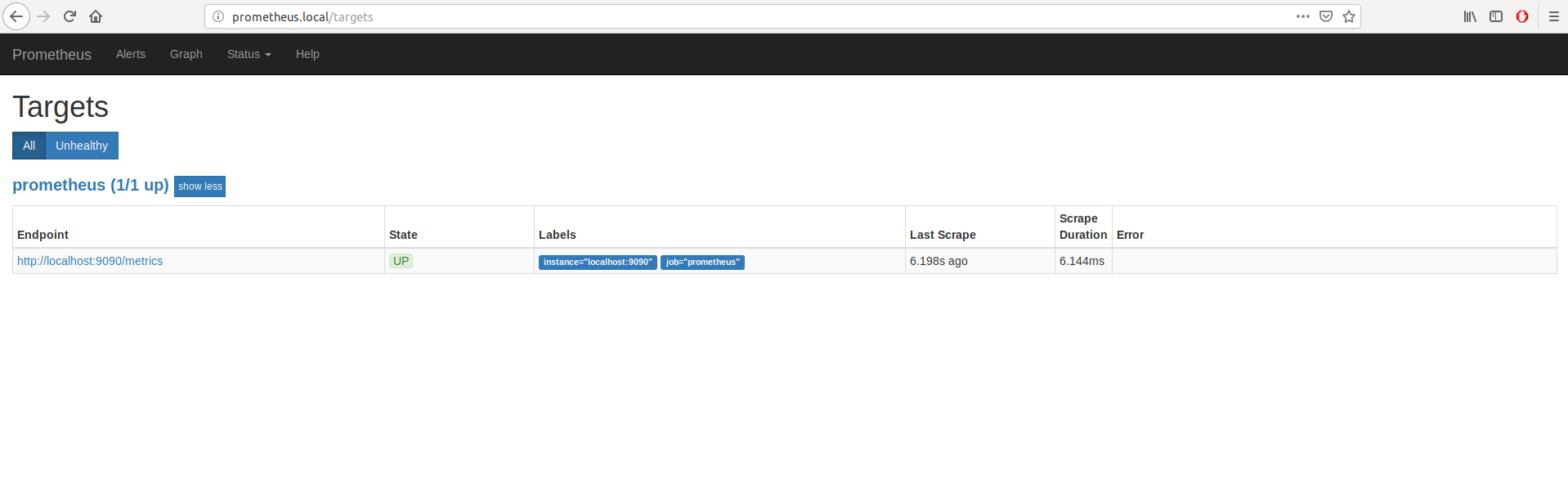
– Cliquez sur l’onglet « Status » puis « Targets » pour voir tout ce qui est monitoré par Prometheus (pas grand chose pour le moment):
3) Configuration des exporters
Comme je l’ai dit précédemment, nous allons monitorer sur notre serveur cible les métrique de l’OS, Apache2 et MySQL.
Pour rappel la liste de tout les exporter est disponible via ce lien: https://prometheus.io/docs/instrumenting/exporters/ (un Exporter est un « agent » à installer sur le serveur à monitorer)
3.1) Monitoring de l’OS (Distribution Linux)
Nous allons pour cela utiliser le « node exporter ».
Télécharger la dernière version de go: https://golang.org/dl/
Une fois l’archive décompressée positionnez vous dans le répertoire bin.
Le binaire node_exporter est disponible:
– Lancez-le
./node_exporter &
– Il ne reste plus qu’à modifier le fichier de configuration (sur votre serveur prometheus) prometheus.yml et y rajouter la configuration suivante avant de redémarrer votre service prometheus:
– job_name: LinuxServer
scrape_interval: 5s
static_configs:
– targets: [‘<ip de votre machine>:9100’]
– Logiquement la target devrait apparaître depuis l’interface web de Prometheus:

3.2) Monitoring d’une instance Apache2
Prérequis: le paquet Golang doit être installé
– Créer un répertoire go dans votre répertoire de travail.
– On alimente le GO PATH:
export GOPATH=<répertoire de travail>/go
– On télécharge apache_exporter
go get github.com/neezgee/apache_exporter
– On lance le apache_exporter
<répertoire de travail>/go/bin/apache_exporter &
– Il ne reste plus qu’à modifier le fichier de configuration (sur votre serveur prometheus) prometheus.yml et y rajouté la configuration suivante avant de redémarrer votre service prometheus:
– job_name: ApacheServer
scrape_interval: 5s
static_configs:
– targets: [‘<ip de votre machine>:9117’]
– Logiquement la target devrait apparaître depuis l’interface web de Prometheus:

3.3) Monitoring d’une base de donnée MySQL
– Récupérez sur le GITHUB de prometheus la dernière version de l’exporter mysqld: https://github.com/prometheus/mysqld_exporter/releases
– Décompressez l’archive précédemment téléchargée sur votre serveur hébergeant votre base de donnée MySQL
– Connectez-vous sur votre base de donnée et lancez les deux requêtes suivantes:
CREATE USER ‘exporter’@’localhost’ IDENTIFIED BY ‘passwordexporter’ WITH MAX_USER_CONNECTIONS 3;
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO ‘exporter’@’localhost’;
FLUSH PRIVILEGES;
– Alimentez la variable d’environnement avec les identifiants du user exporter précédemment créés:
export DATA_SOURCE_NAME=’exporter:<motdepasseduuserexporter’@(hostname:3306)/’
– Lancez l’exporter mysqld:
export DATA_SOURCE_NAME=’exporter:toto@(hostname:3306)/’
– Il ne reste plus qu’à modifier le fichier de configuration (sur votre serveur prometheus) prometheus.yml et y rajouté la configuration suivante avant de redémarrer votre service prometheus:
– job_name: MySQL
scrape_interval: 5s
static_configs:
– targets: [‘<ip de votre machine>:9104’]
– Logiquement la target devrait apparaître depuis l’interface web de Prometheus:

4) Grafana
Il ne reste plus qu’à interfacer les metrics récoltées par prometheus via les exporters que nous avons installé sur notre machine cible avec un Grafana.
L’installation de Grafana est très simple et est disponible sur le site officiel:
– Debian/Ubuntu: http://docs.grafana.org/installation/debian/
– Centos/RedHat: http://docs.grafana.org/installation/rpm/
4.1) Configuration du Datasource Prometheus
Dans un premier temps, nous allons configurer le datasource prometheus dans Grafana (afin qu’il soit directement connecté avec notre serveur prometheus). Dans ce tuto j’ai installé Grafana sur la même machine que Prometheus.
– Cliquez sur la roue dentée situé dans la bar de menu à gauche:
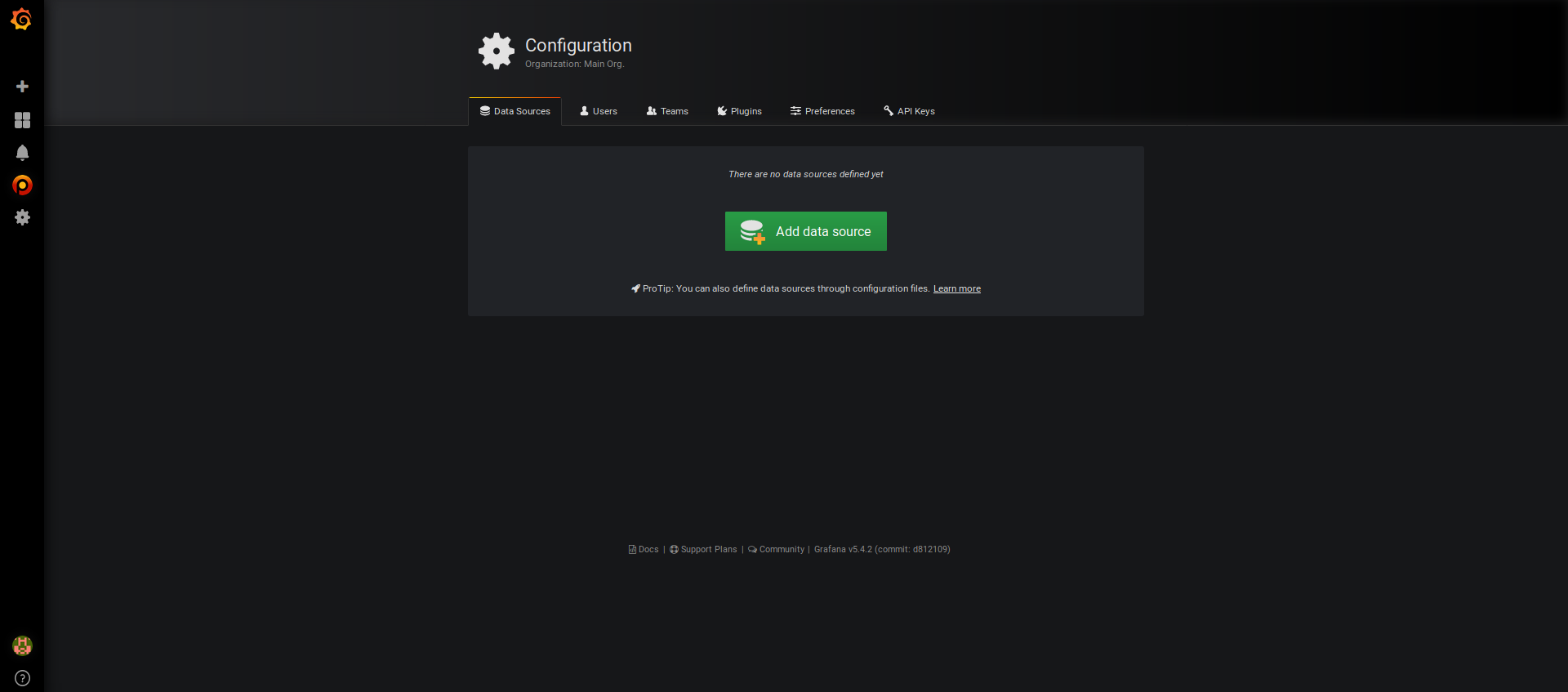
– Cliquez sur le bouton « Add Data source » puis cliquez sur « Prometheus »
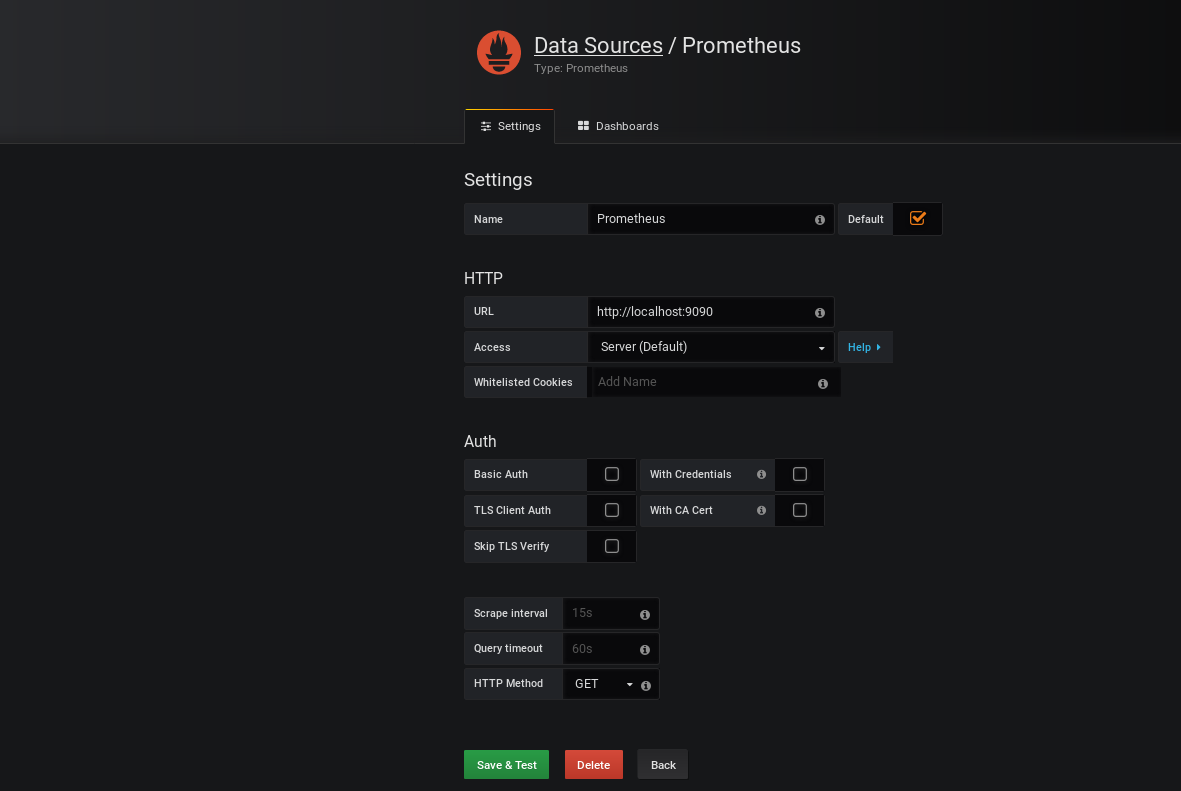
– Renseignez les informations demandées comme l’image ci-dessous puis cliquez sur le bouton « Save & Test »
4.2) Création du Dashboard Node Exporter (les métriques de notre OS)
Pour cela inutile de réinventer la roue. Des dashboard tout prêt sont fournis gracieusement par la communauté Grafana: https://grafana.com/dashboards
En recherchant j’ai trouvé ce dashboard:
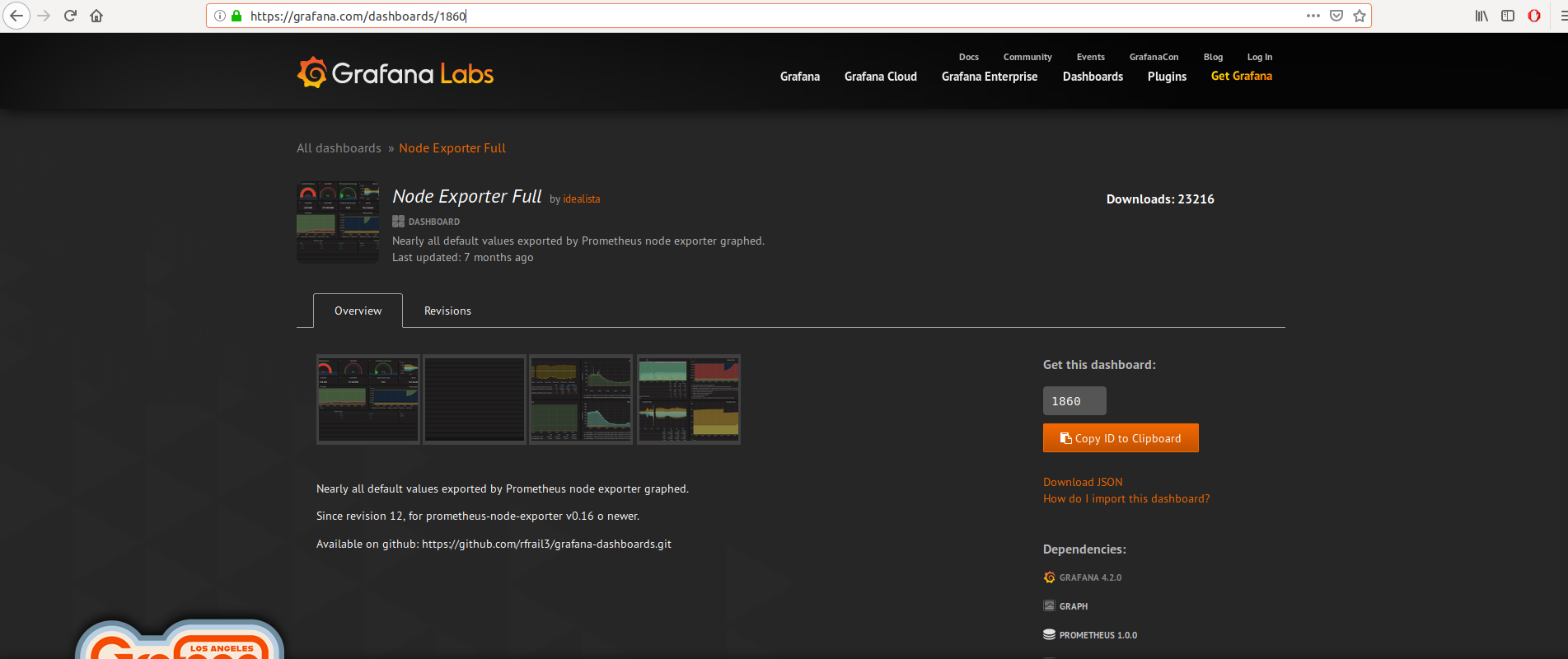
Conservez l’ID du dashboard.
– Cliquez sur le bouton « + » sur la gauche de l’interface puis sur « import »
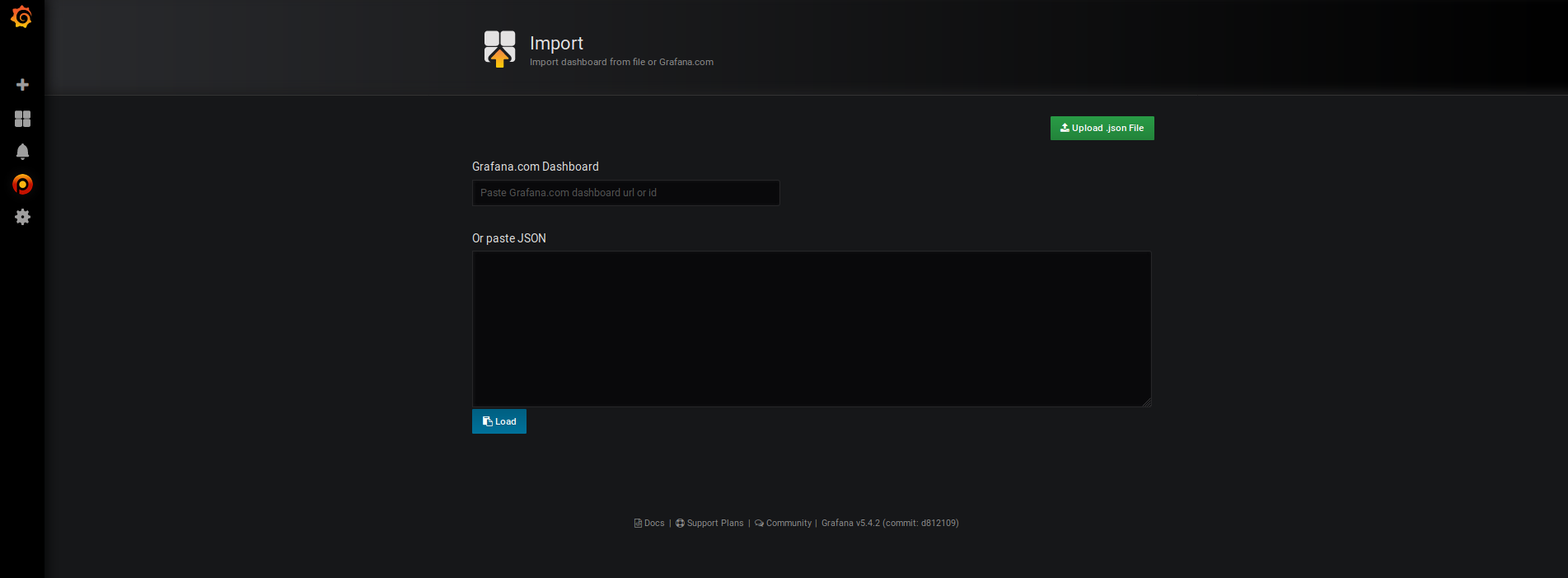
– Renseignez l’ID du dashboard que l’on a récupéré sur le site de Grafana dans le 1er champ (1860).
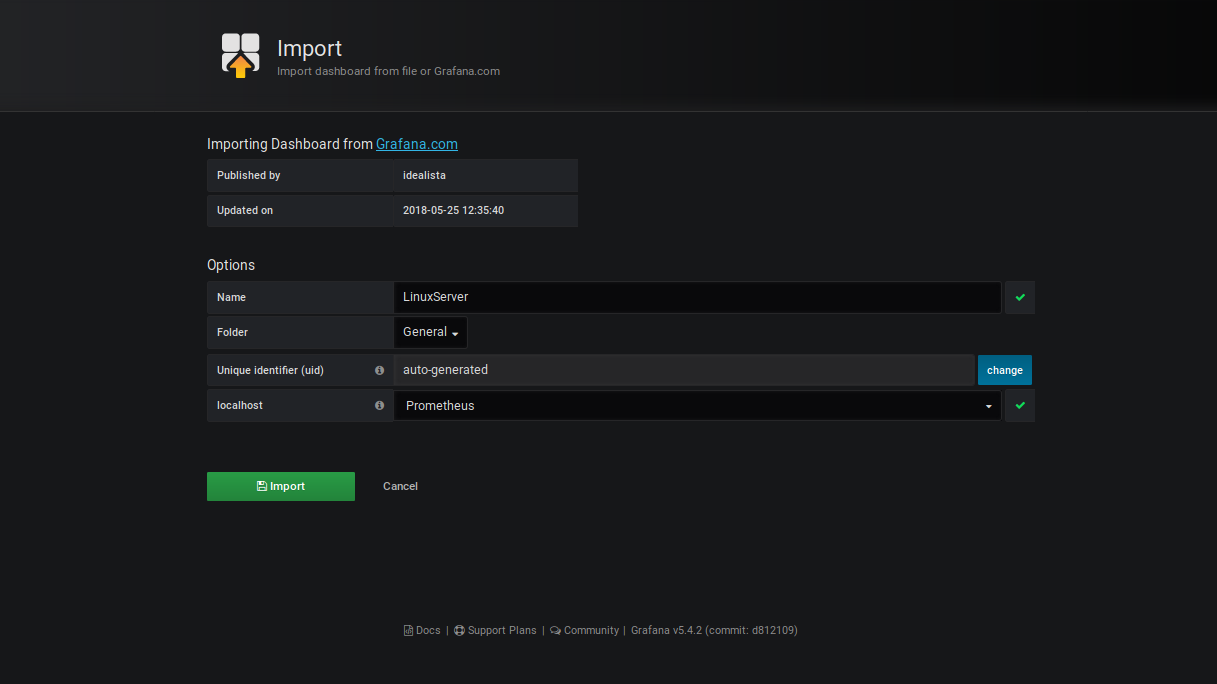
– Renseignez les champs comme la capture ci-dessus puis cliquez sur le bouton « Import »
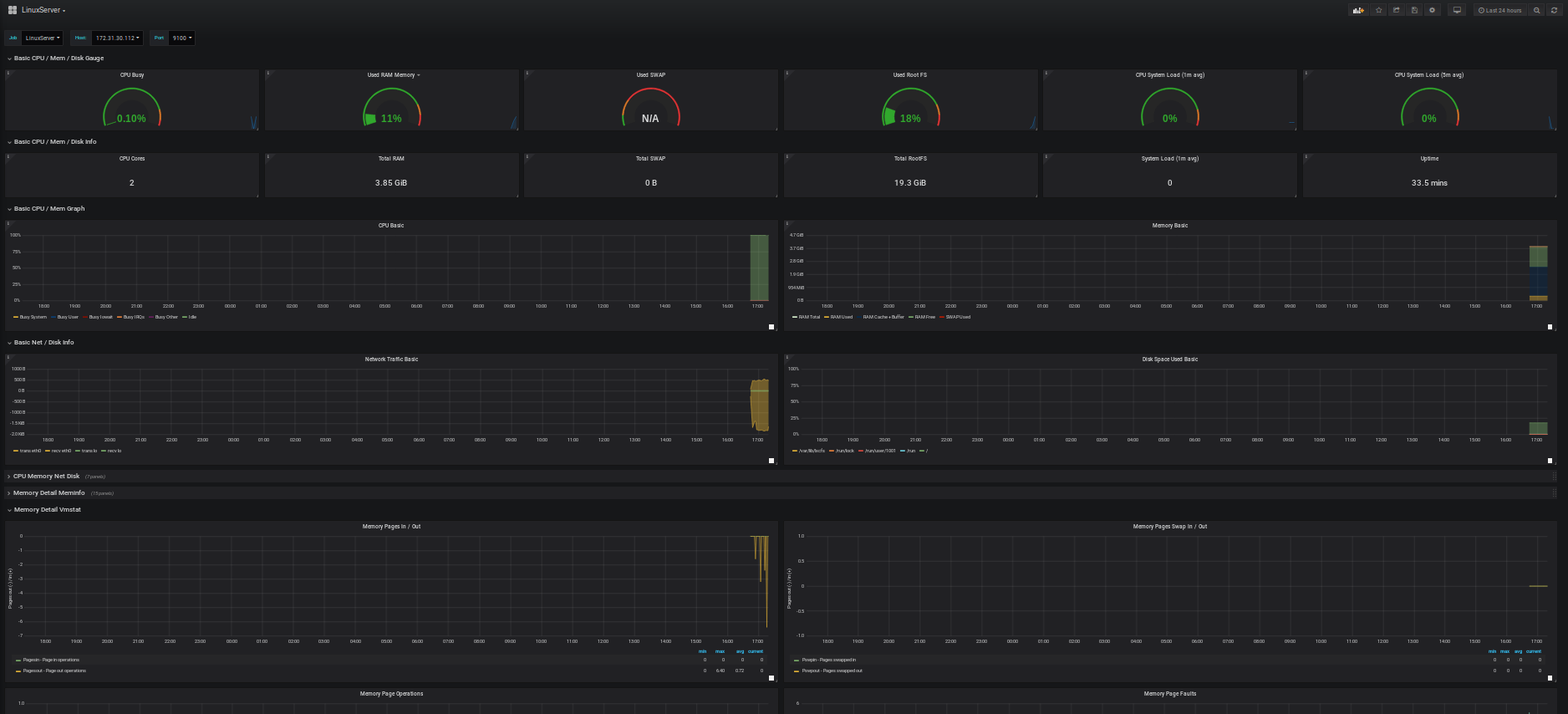
– Il ne reste plus qu’à profiter de vos graph!
4.3) Création du Dashboard Apache
Même méthode que pour le dashboard node-exporter (partie 4.2 de ce tutoriel), importez le dashboard id 3894.
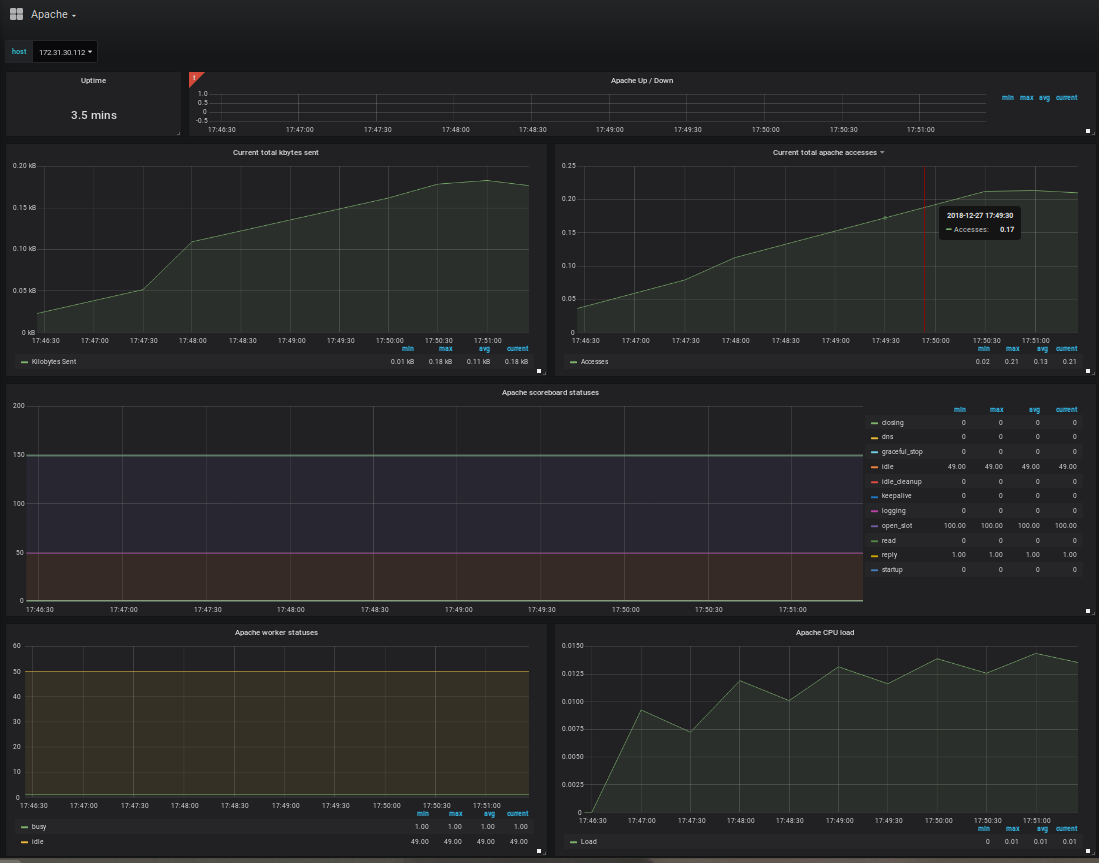
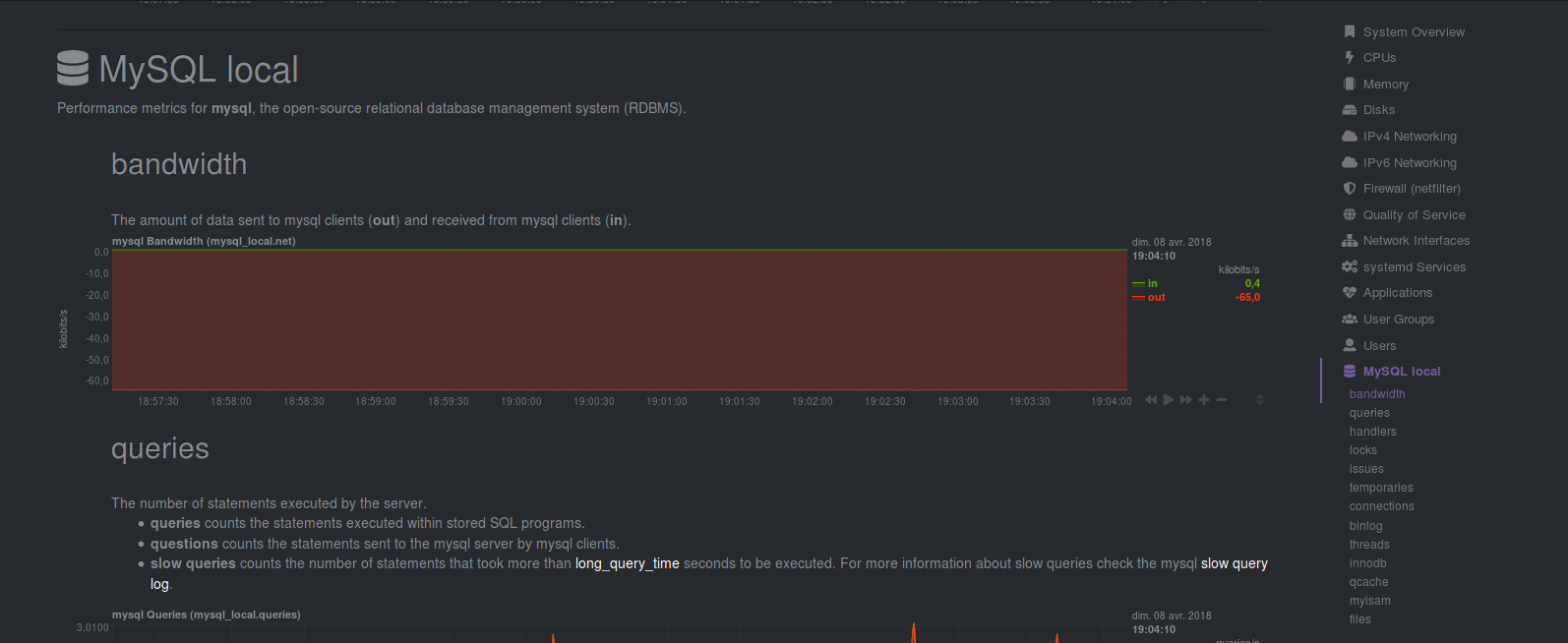
4.4) Création du Dashboard MySQL
La marche à suivre pour le Dashboard MySQL est un peu différente car nous allons utiliser le plugin grafana Percona qui se sert du datasource Prometheus.
– Cliquez sur la route dentée à gauche puis sur « plugins », puis cliquez sur « Percona »

– Cliquez sur « Enable »:
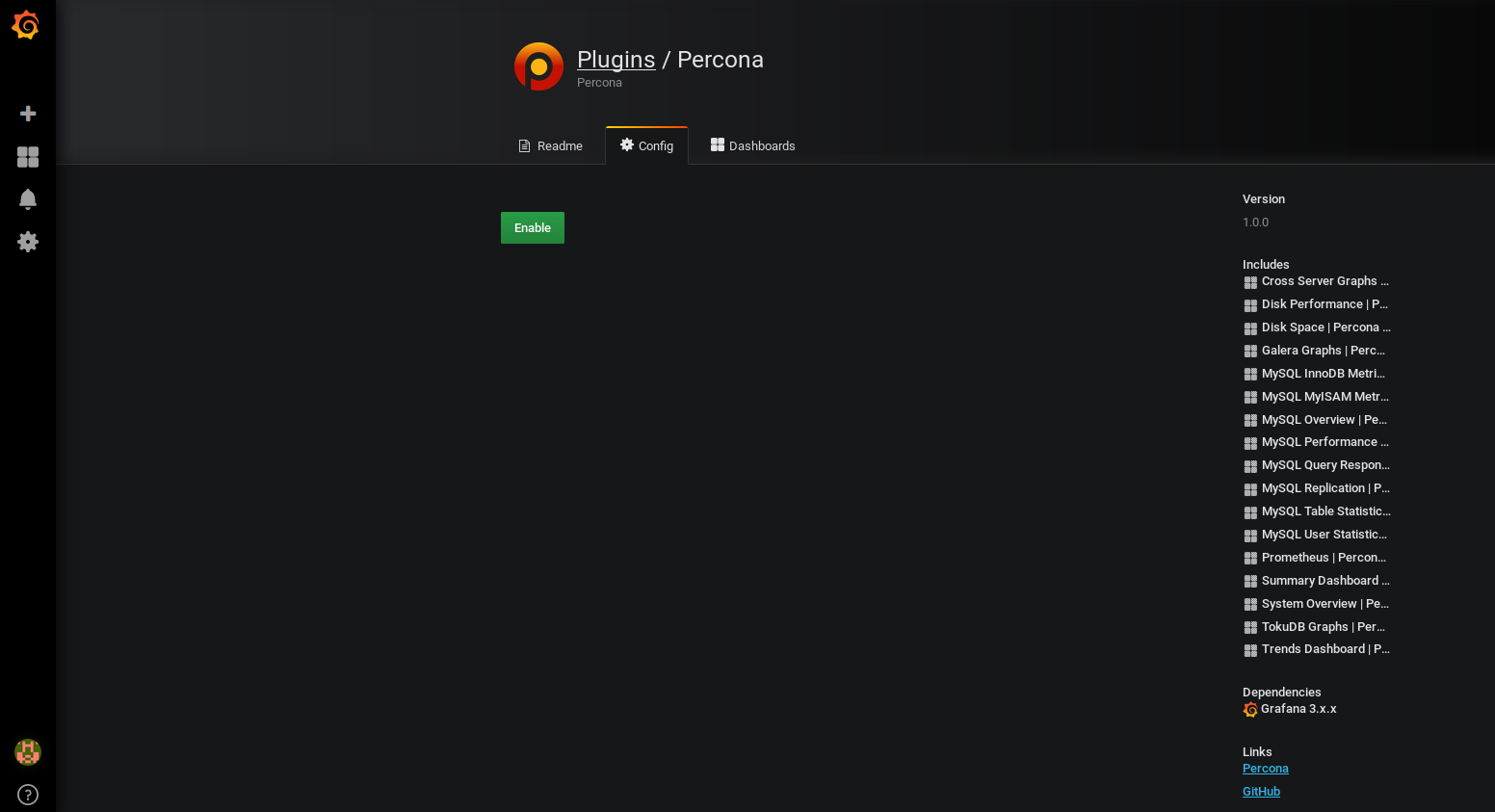
– Cliquez sur ensuite sur l’onglet Dashboard et importez les Dashboard qui seraient susceptible de vous intéresser (sinon importez les tous !)
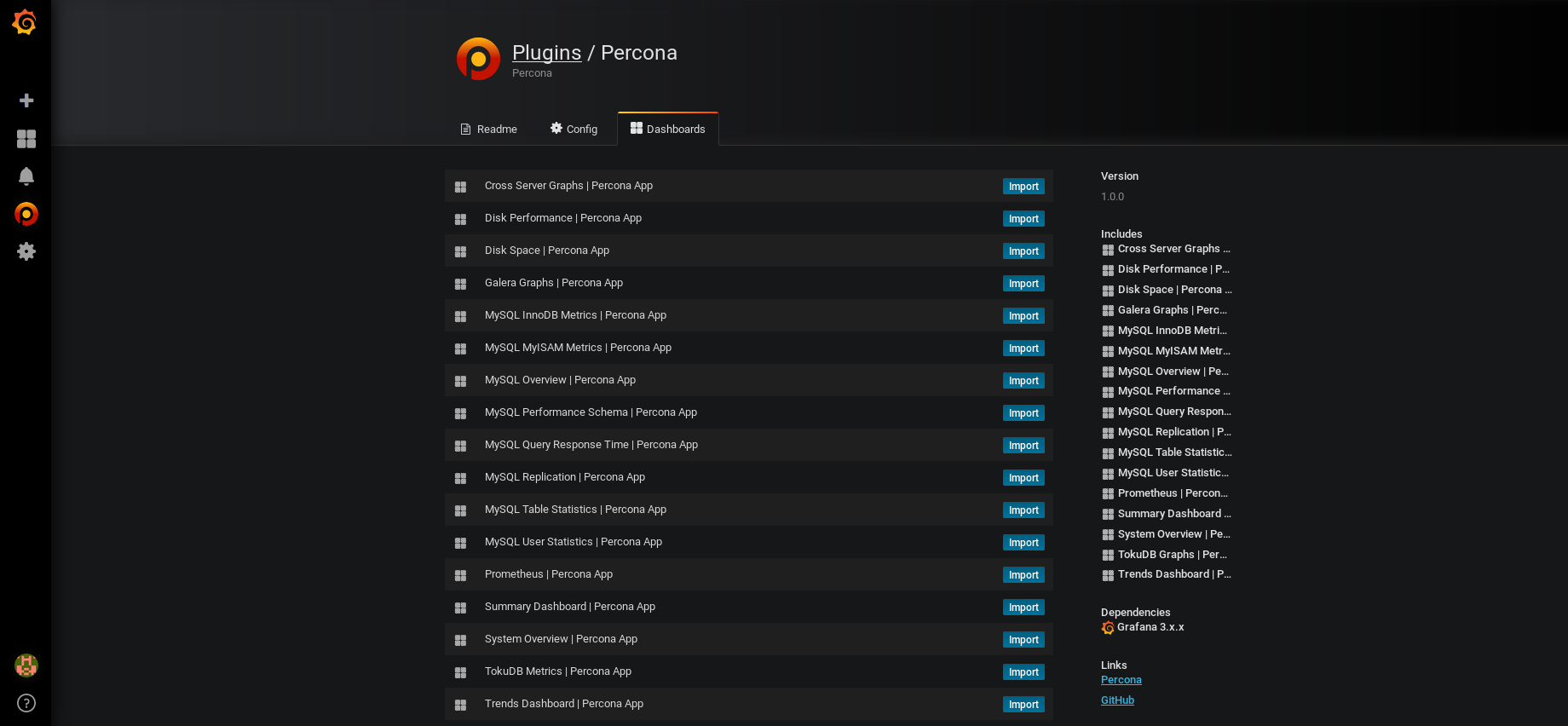
– Normalement, les Dashboard suivants ont été rajoutés automatiquement (où ceux que vous avez spécifiquement séléctionnés):
– En cliquant sur l’un d’eux (par exemple MySQL Overview) vous devriez voir apparaître vos Graph:
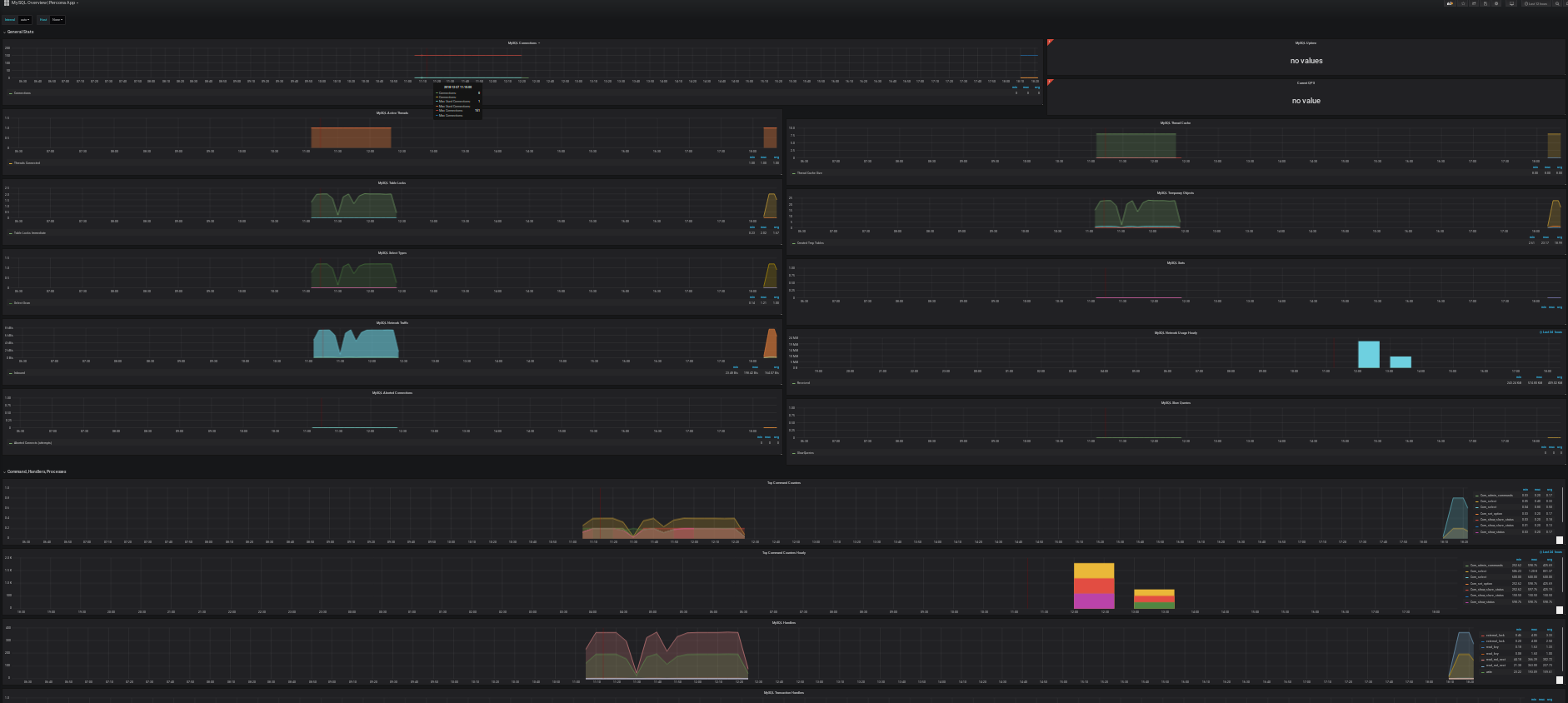
Enjoy!