 Tutoriel | Héberger son IA locale avec Ollama et lui apprendre vos données (RAG) sans exploser son serveur !
Tutoriel | Héberger son IA locale avec Ollama et lui apprendre vos données (RAG) sans exploser son serveur !
Article publié le 28 Février 2026
Salut à tous !
Aujourd'hui, on va s'attaquer à un gros morceau, mais on va le faire à notre sauce d'admin sys : proprement, en local, et sans dépendre du cloud.
Vous en avez marre d'entendre parler d'IA tout en sachant que la moindre question posée à ChatGPT envoie vos données internes, vos docs techniques ou les infos de votre boîte directement sur des serveurs aux États-Unis ? Moi aussi.
La bonne nouvelle, c'est qu'héberger son propre LLM (Large Language Model) n'est plus réservé à ceux qui ont 15 000 € à mettre dans un cluster de GPU. Aujourd'hui, on va voir comment déployer Ollama sur une simple VM Linux (un petit 4 vCPUs / 16 Go de RAM fera l'affaire), et surtout, on va voir comment lui injecter vos propres données grâce à la magie du RAG (Retrieval-Augmented Generation).
Accrochez vos ceintures, on va se monter un chatbot souverain et ultra-léger !
1. Ollama : Le "Docker" des modèles d'IA
Si vous savez utiliser Docker, vous savez utiliser Ollama. C'est un outil écrit en Go qui simplifie à l'extrême le téléchargement et l'exécution de modèles d'IA en local. Il gère la RAM, le CPU, et expose même une API REST compatible avec celle d'OpenAI. Que demander de plus ?
Installation
Sur votre distribution Linux préférée (Debian, Ubuntu...), l'installation se fait via un script officiel. Oui, je sais, on n'aime pas trop les curl | bash, mais ici c'est l'outil officiel et il configure tout le service systemd proprement.
curl -fsSL https://ollama.com/install.sh | sh
Vérifions que le démon tourne correctement :
systemctl status ollama

Télécharger et lancer un modèle
Pour notre VM sans carte graphique, on va éviter les modèles obèses à 70 milliards de paramètres. On va partir sur Gemma 3 (1B) Il est bluffant et tourne parfaitement sur CPU.
# On télécharge et on lance le modèle interactif ollama run gemma3:1b
Boum ! Vous avez un prompt interactif. Vous discutez avec une IA qui tourne à 100% sur votre machine. Pour sortir, faites un petit /bye.
Par défaut, Ollama écoute sur le port 11434 en local. Vous pouvez tester son API avec un simple curl :
curl http://localhost:11434/api/generate -d '{ "model": "gemma3:1b", "prompt": "Explique-moi ce qu'est un hyperviseur en une phrase.", "stream": false }'

C'est cool, mais ce modèle a un défaut : il ne connaît rien de VOUS. Il ne connaît pas vos procédures internes, ni votre wiki, ni les tarifs de votre boîte. C'est là qu'entre en jeu le RAG.
2. Le RAG : Donner un cerveau métier à votre IA
Plutôt que d'essayer de ré-entraîner le modèle avec vos données (le fameux fine-tuning, qui coûte un bras en puissance de calcul et qui est une galère à maintenir), on utilise le RAG (Retrieval-Augmented Generation).
Le concept est brillant de simplicité :
-
On découpe vos documents (fichiers TXT, PDF, Markdown) en petits morceaux.
-
On transforme ces morceaux en vecteurs (une suite de chiffres) et on les stocke dans une petite base de données.
-
Quand l'utilisateur pose une question, on cherche les morceaux de vos documents qui s'en rapprochent le plus.
-
On envoie ces morceaux à Ollama en lui disant : "Voici des infos de mon wiki interne. Utilise-les pour répondre à cette question : ..."
C'est l'équivalent de donner un livre ouvert à un étudiant pendant un examen.
3. Pratique : Le script RAG "Admin-Friendly" (Ultra-Light)
Beaucoup de tutos vous diront d'installer l'usine à gaz LangChain ou le monstrueux PyTorch (qui va vous bouffer 4 Go d'espace disque). Sur Journal d'un admin Linux, on aime quand c'est slim.
On va écrire un script Python qui n'utilise que l'API de notre serveur Ollama (pour la génération ET pour la vectorisation) et une minuscule base de données appelée ChromaDB.
Les prérequis
Sur votre machine, on télécharge un modèle spécialisé d'Ollama (minuscule et ultra-rapide) pour créer nos vecteurs :
ollama pull nomic-embed-text
Puis on installe les deux seules dépendances Python nécessaires :
pip3 install requests chromadb
Vos données
Créez un fichier wiki_interne.txt avec quelques infos factices pour le test :
Serveur d'impression : L'IP du serveur d'impression de l'étage 2 est 192.168.1.50. Il faut utiliser le driver générique PCL6.
VPN : Pour se connecter au VPN de l'entreprise, le port utilisé est le 1194 en UDP. Le certificat doit être renouvelé tous les ans.
Serveur Web : Notre site principal tourne sous Nginx sur le serveur SRV-WEB-01 (Debian 12).
Le Script Python : rag_local.py
Voici notre script fait maison. Il est agnostique, rapide, et ne fait pas exploser la RAM.
import requests
import chromadb
import argparse
# --- CONFIGURATION ---
URL_OLLAMA = "http://localhost:11434"
MODEL_IA = "gemma3:1b" # Modèle qui rédige la réponse
MODEL_VECTEUR = "nomic-embed-text" # Modèle qui lit le document
def get_embedding(text):
""" Demande à Ollama de transformer le texte en suite de nombres (vecteurs) """
res = requests.post(f"{URL_OLLAMA}/api/embeddings",
json={"model": MODEL_VECTEUR, "prompt": text})
return res.json()["embedding"]
def interroger_mon_ia(question, fichier_txt):
try:
# 1. On charge notre fichier de doc interne
with open(fichier_txt, 'r', encoding='utf-8') as f:
contenu = f.read()
# On découpe grossièrement par paragraphes
paragraphes = [p.strip() for p in contenu.split('\n') if len(p.strip()) > 10]
# 2. Création de notre base de données vectorielle (en RAM pour la vitesse)
db_client = chromadb.Client()
collection = db_client.get_or_create_collection(name="mon_wiki")
# 3. On injecte nos paragraphes dans la base via Ollama
print(f"[*] Indexation de {len(paragraphes)} blocs de texte en cours...")
for i, texte in enumerate(paragraphes):
vecteur = get_embedding(texte)
collection.add(ids=[str(i)], embeddings=[vecteur], documents=[texte])
# 4. Recherche magique : on trouve les infos liées à la question !
vecteur_question = get_embedding(question)
resultats = collection.query(query_embeddings=[vecteur_question], n_results=1)
contexte_trouve = "\n".join(resultats['documents'][0])
# 5. On demande à l'IA de faire une synthèse avec NOS infos
prompt = (
f"Tu es un admin sys expert. Utilise UNIQUEMENT le contexte ci-dessous pour répondre.\n"
f"CONTEXTE INTERNE :\n{contexte_trouve}\n\n"
f"QUESTION : {question}\n\n"
f"RÉPONSE :"
)
res_ia = requests.post(f"{URL_OLLAMA}/api/generate",
json={"model": MODEL_IA, "prompt": prompt, "stream": False})
return res_ia.json().get('response', 'Erreur de génération')
except Exception as e:
return f"Erreur critique : {str(e)}"
# --- EXÉCUTION ---
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Interrogez vos docs locales avec l'IA")
parser.add_argument("question", type=str, help="Votre question")
parser.add_argument("-f", "--fichier", type=str, default="wiki_interne.txt", help="Fichier source")
args = parser.parse_args()
reponse = interroger_mon_ia(args.question, args.fichier)
print(f"\n[RÉPONSE DE L'IA] :\n{reponse}")
Il ne reste plus qu'à poser une question ultra-spécifique à notre script depuis le terminal :
python3 rag_local.py "Sur quel port tourne notre VPN ?"
Sortie :
[*] Indexation de 3 blocs de texte en cours... [RÉPONSE DE L'IA] : 1194 en UDP !

💥 Bim ! L'IA ne vous a pas fait une réponse générique copiée sur Wikipédia, elle a lu votre fichier de configuration et vous a répondu avec vos données. Le tout sans qu'un seul octet n'ait quitté votre serveur en bare-metal ou votre VM.
Conclusion
L'association d'Ollama (pour l'inférence) et d'un petit script Python avec ChromaDB (pour le RAG) est une véritable tuerie. C'est robuste, ça consomme peu de ressources disque par rapport aux grosses stacks d'IA habituelles, et ça ouvre la porte à des dizaines d'usages :
-
Un chatbot d'entreprise qui interroge vos logs ou vos manuels de procédures.
-
Une API (en rajoutant un peu de FastAPI par dessus) pour le support IT interne.
-
Une solution d'IA à proposer à vos clients, sans les soucis liés au RGPD !
Et vous, vous l'hébergez où votre IA ? Dites-le-moi en commentaire ou venez en discuter avec nous sur le réseau !
Tutoriel | Dokploy : Le PaaS qui veut réconcilier l’Admin Linux avec le déploiement moderne
Article publié le 19 Janvier 2026
À l'heure où les notions de cloud souverain et d'écosystème "Auto-hébergé" reviennent en force, utiliser Dokploy sur votre infrastructure "on-premise" devient de plus en plus pertinent.
Dokploy est une solution open source qui permet de déployer en 10 minutes un PaaS sur des serveurs classiques, qu'ils soient sur votre cloud privé ou chez un cloud provider public (AWS, GCP ou Azure).
1) Installation
Pour ce tuto, j'ai utilisé une VM sous Debian 12 avec 4 vCPU et 16 Go de RAM afin d'être peinard.
L'installation est une formalité, même pour un admin débutant. Il suffit d'exécuter ce script avec l'utilisateur root :
sudo curl -sSL https://dokploy.com/install.sh | sh
Que fait ce script?
-
Vérification des dépendances : Il installe
curl,sudoetgit. -
Setup Docker : S'il n'est pas présent, il installe Docker Engine.
-
Swarm Mode : Il exécute
docker swarm init(si ce n'est pas déjà fait). C'est crucial car Dokploy utilise les services Swarm pour la gestion du réseau. (Même si je ne suis pas fan de Docker Swam il faut admettre que c'est bien pratique) -
Pull & Run : Il télécharge l'image Docker de Dokploy et lance le service.
Une fois terminé, vérifiez que l'interface web est dispo sur le port 3000 et enregistrez votre premier utilisateur.
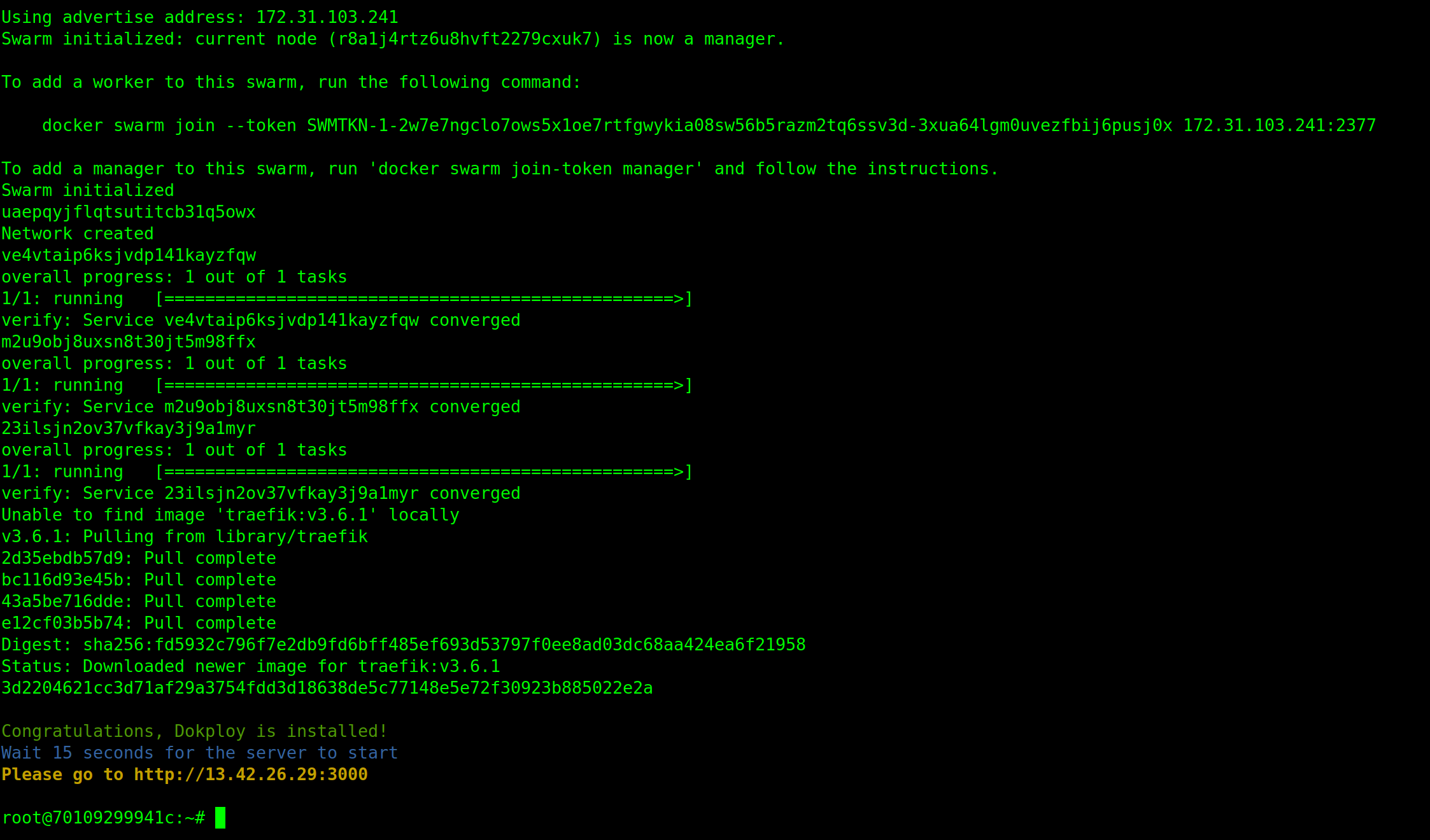
Sous le capot, un petit docker ps -a vous confirmera que tout tourne proprement.

2) Prise en main
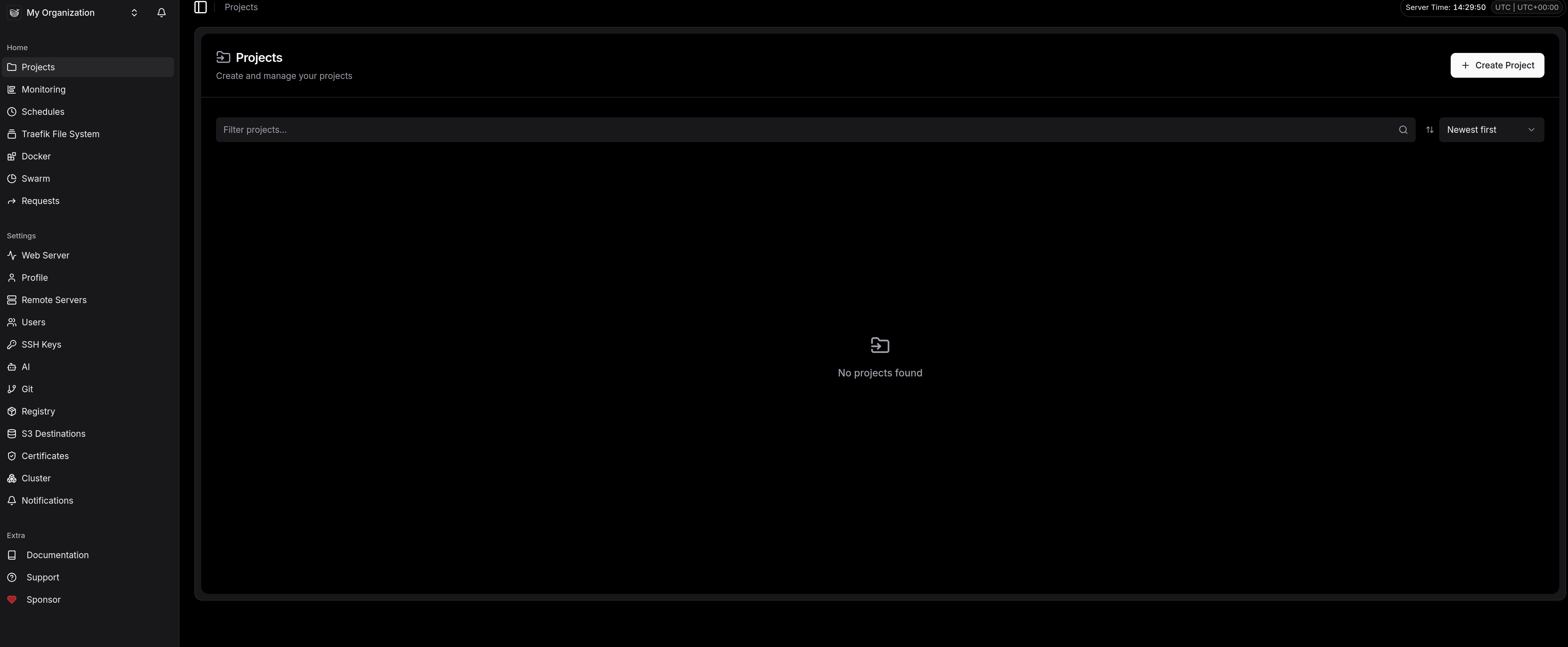
Nous voici sur l'interface d'admin qui me parait fort sympathique. On est loin des usines à gaz surchargées : ici, c'est propre, sombre (le mode Dark par défaut, merci pour nos yeux d'admin) et surtout très structuré.
Voici ce qu'on retrouve dans la barre latérale et qui va devenir notre quotidien :
Le pilotage opérationnel (Home)
C'est ici que l'on gère le "Run".
-
Projects : C'est le cœur du réacteur. On y crée des groupes pour nos apps (par exemple "Prod", "Staging" ou "Blog").
-
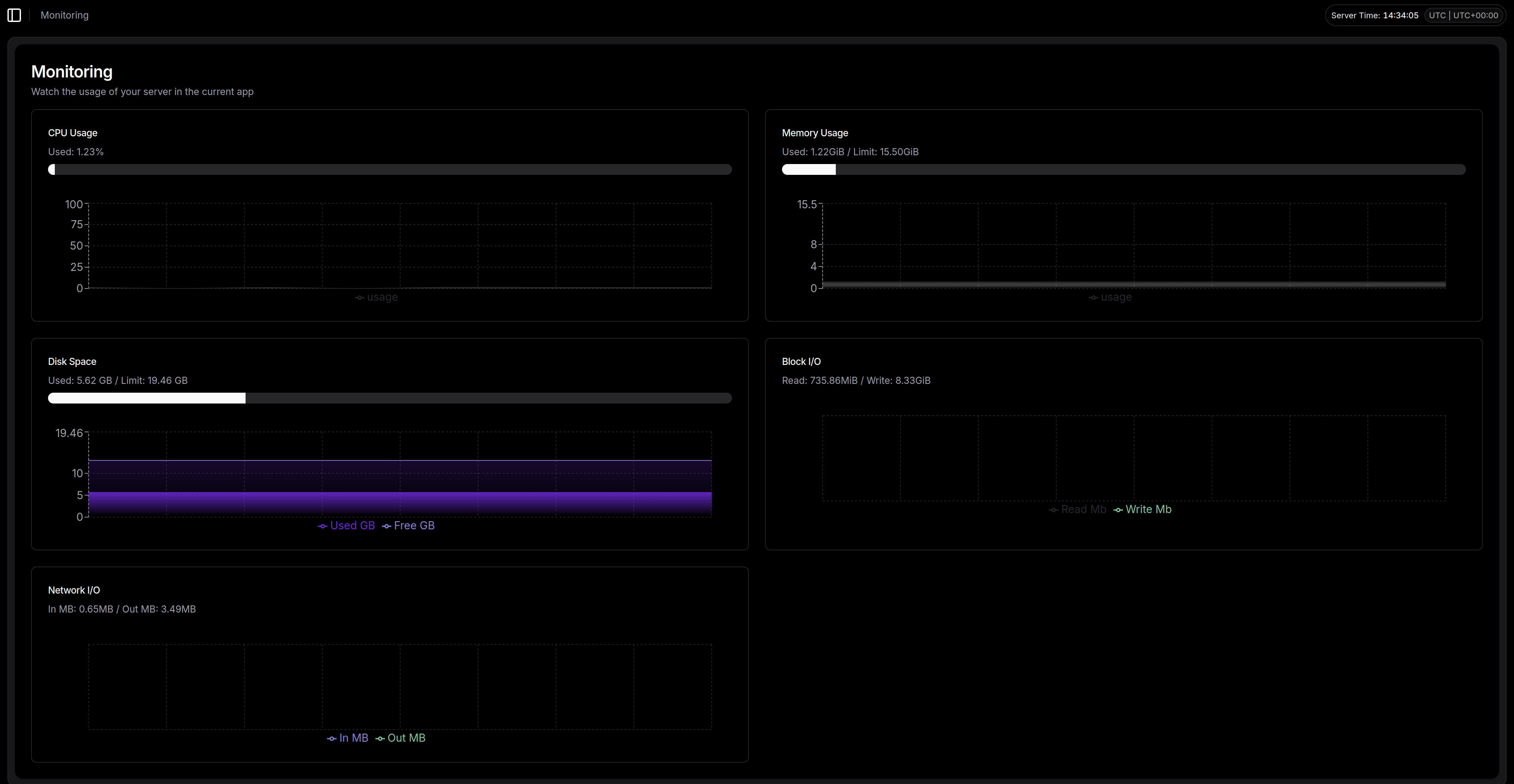
Monitoring & Schedules : Pour garder un œil sur la charge CPU/RAM et gérer les tâches cron sans avoir à éditer la crontab du host à la main.
-
Traefik File System & Docker/Swarm : La partie que j'apprécie particulièrement. Dokploy ne vous cache rien. Vous avez un accès direct aux fichiers de config du reverse proxy et à l'état de votre cluster Swarm. C'est transparent.
-
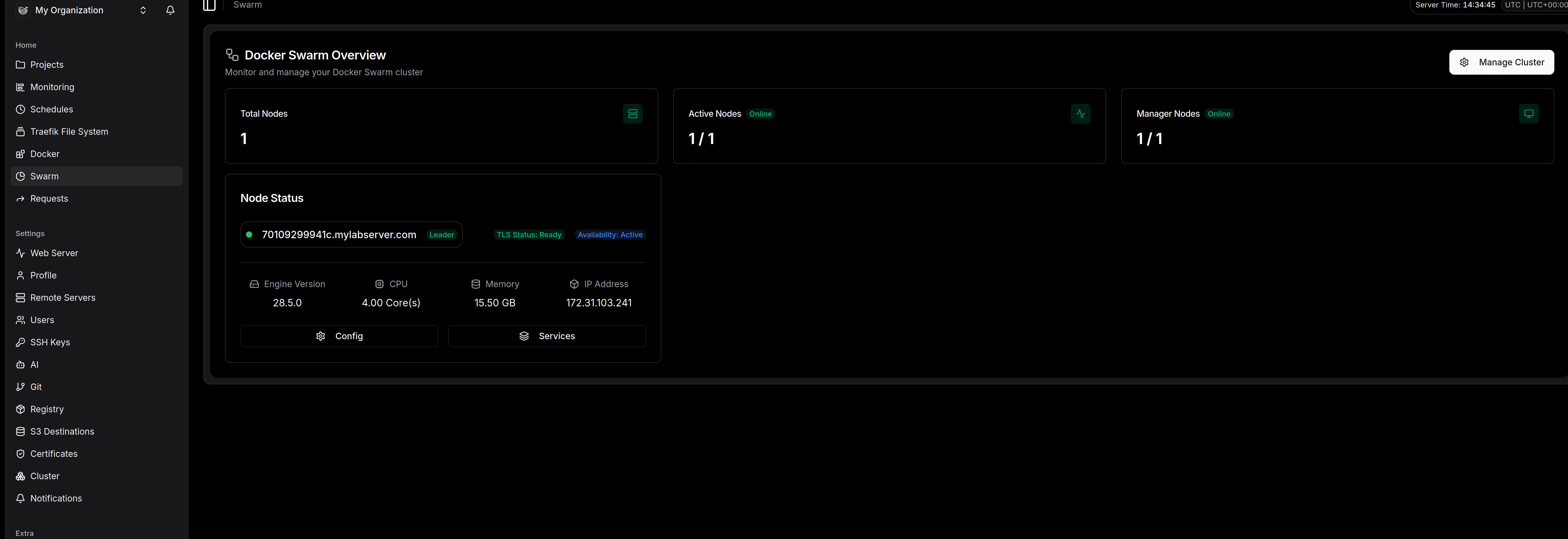
La configuration fine (Settings)
C'est là qu'on sent que l'outil est pensé pour la prod "on-premise" :
-
Remote Servers & Cluster : Dokploy n'est pas limité à un seul nœud. On peut piloter d'autres serveurs et gérer son cluster directement depuis cette interface.
-
Registry & S3 Destinations : Indispensable ! On peut lier son propre registre Docker et surtout configurer ses backups de bases de données vers du S3 (AWS, Minio ou autre).
-
Certificates : La gestion du SSL (Let's Encrypt) est automatisée, mais vous pouvez aussi importer vos propres certificats si vous avez des contraintes de sécurité spécifiques.
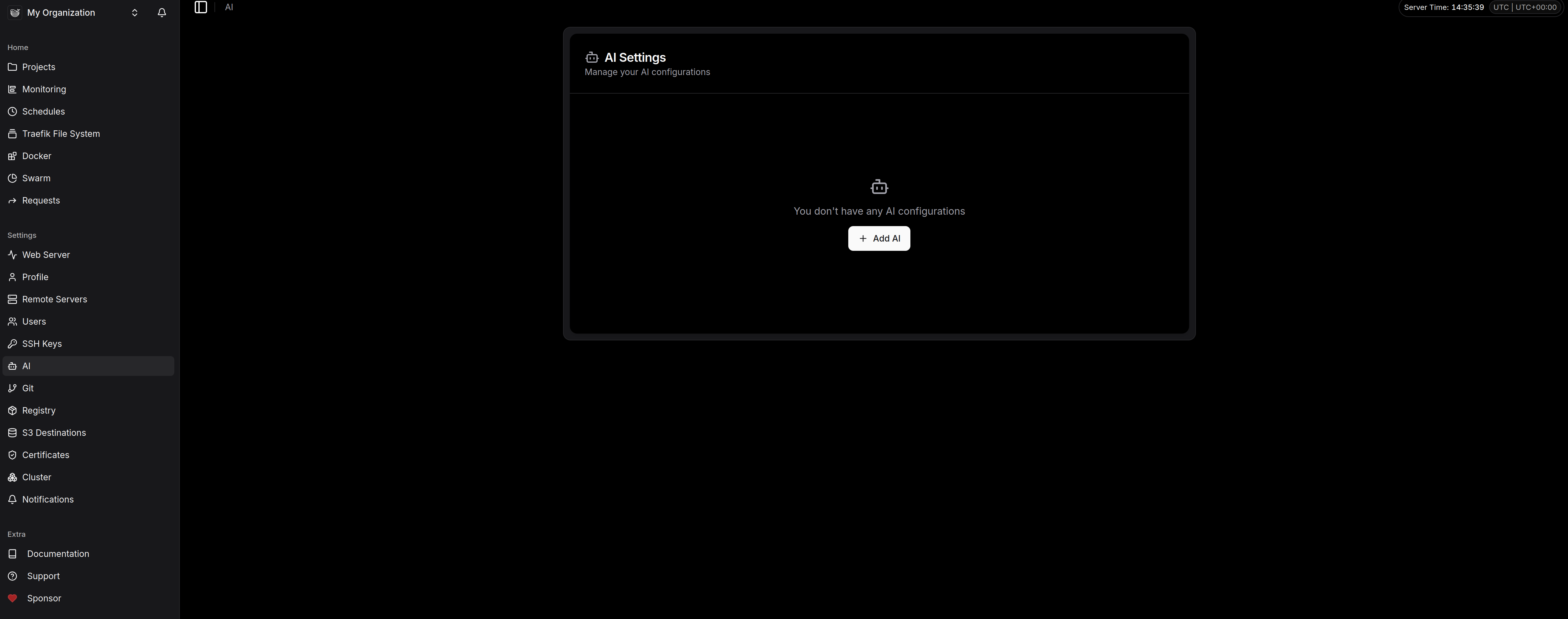
Le petit plus : L'onglet AI
On notera la présence d'un menu AI. À l'heure actuelle, cela permet de configurer un modèle (type OpenAI) pour vous aider à générer des Dockerfiles ou des fichiers de configuration si vous avez un trou de mémoire sur une syntaxe. Gadget pour certains, gain de temps pour d'autres.
3) Déploiement d'un workload.
On va maintenant déployer un site wordpress via Dokploy pour voir comment tout cela fonctionne:
3.1) Déploiement de la base de données
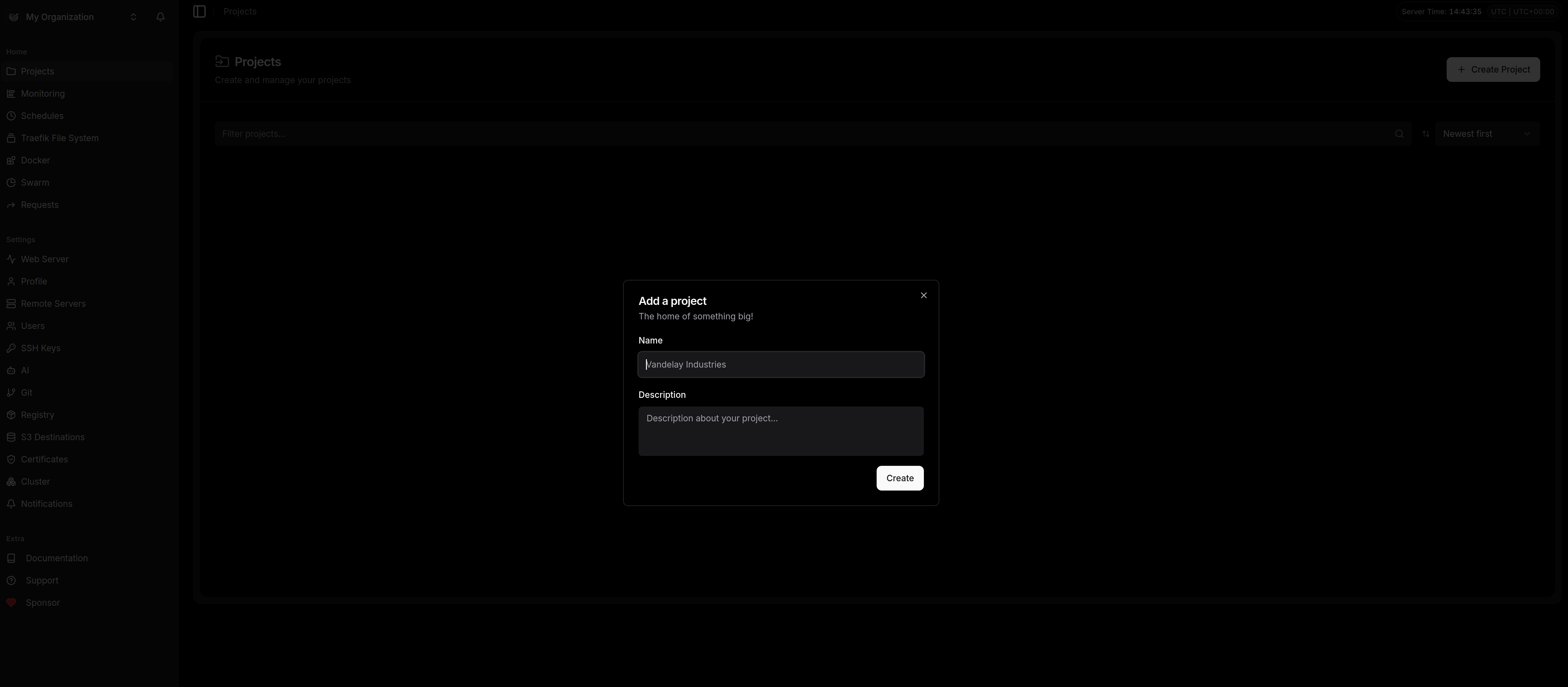
- Créons un projet en cliquant sur "Create Project" depuis l'onglet "Projects":
- Une fois le projet créé, nous allons déployer ce dont nous avons besoin pour faire tourner un site wordpress: une application et une database
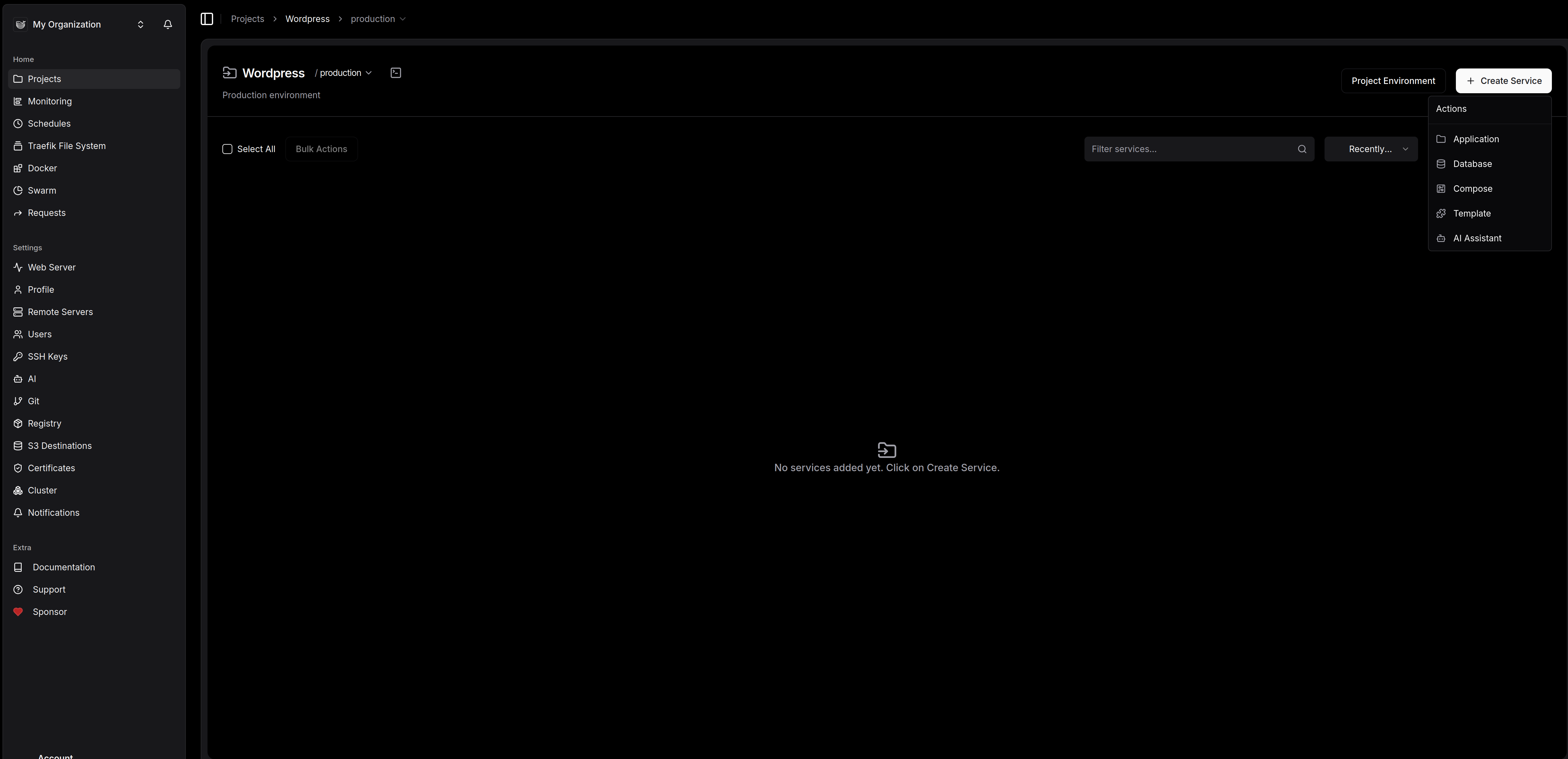
- Commencons pas la base de donnée: cliquez sur "service" et "database."
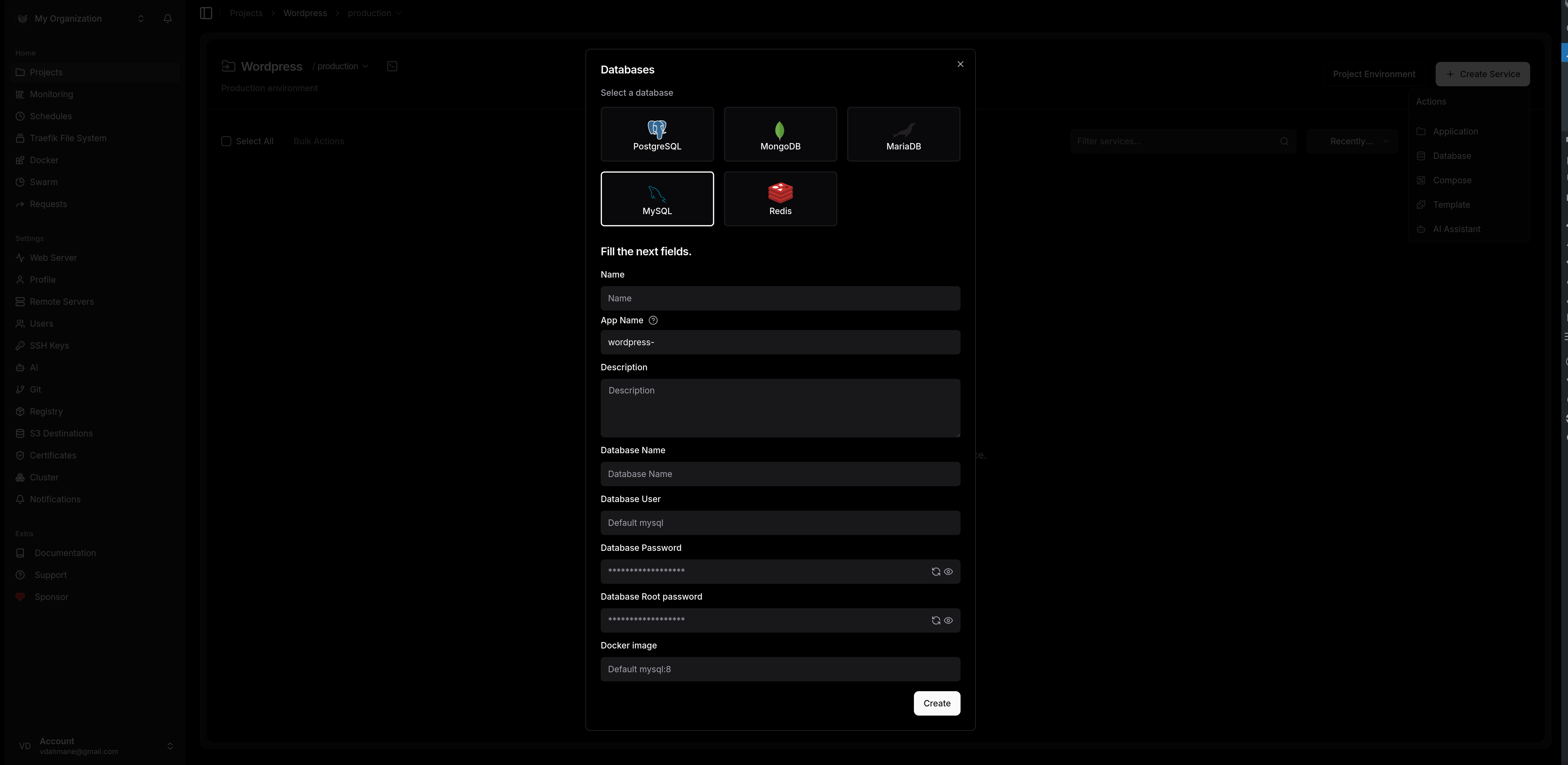
Comme vous pouvez le voir, l'éventail de choix est large ; pour ce tuto, nous partons sur une base MySQL. Remplissez simplement les champs de configuration et validez en cliquant sur "Create".
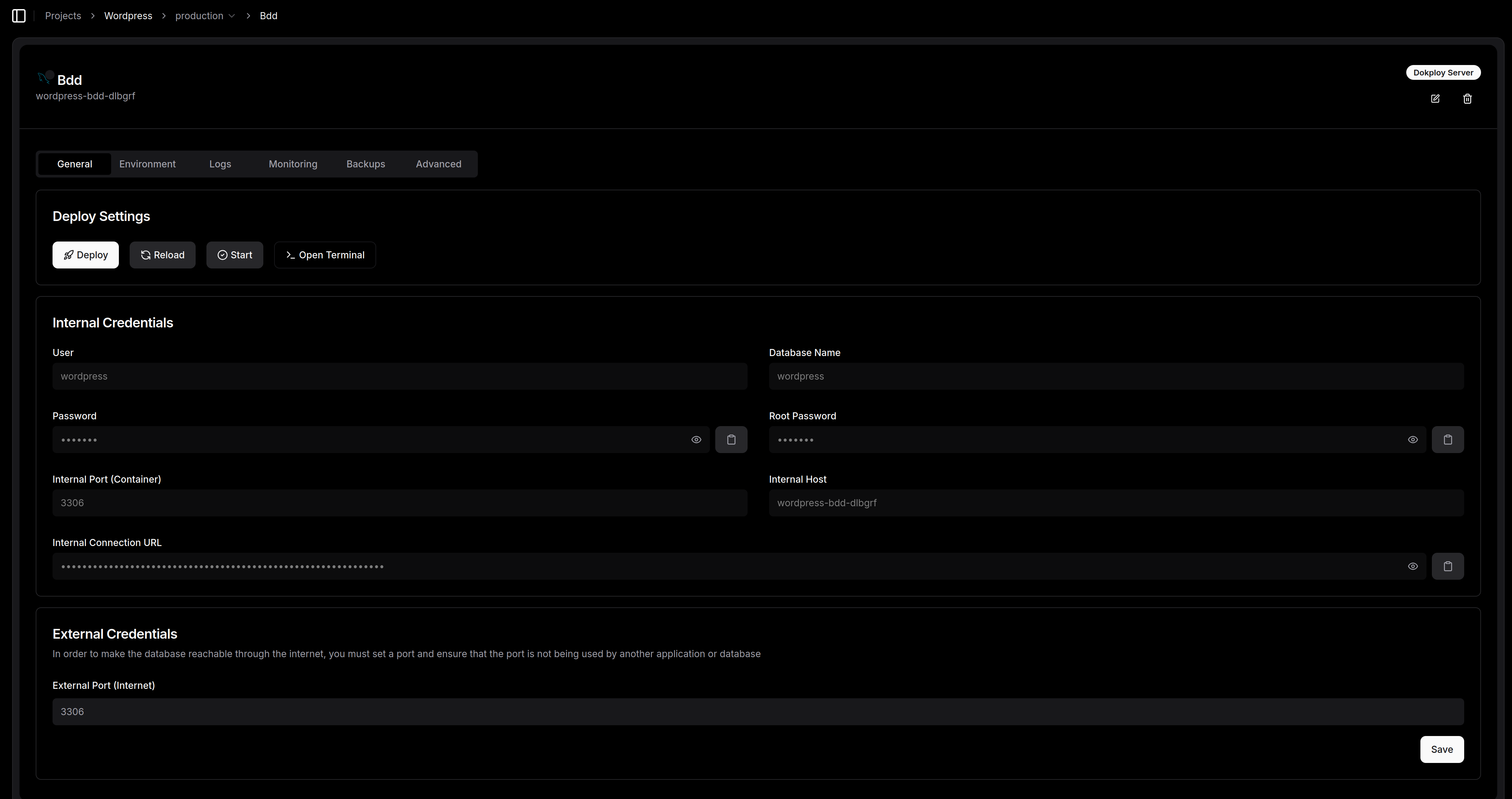
Il ne reste plus qu'à déployer la base de données en cliquant sur le bouton "Deploy"
C'est beau!!
En vérifiant on peut peut voir que le container est bien démarré (1er ligne)

3.) Déploiement de WordPress
Ca repart, on crée un nouveau service de type application que l'on va nommer "website":
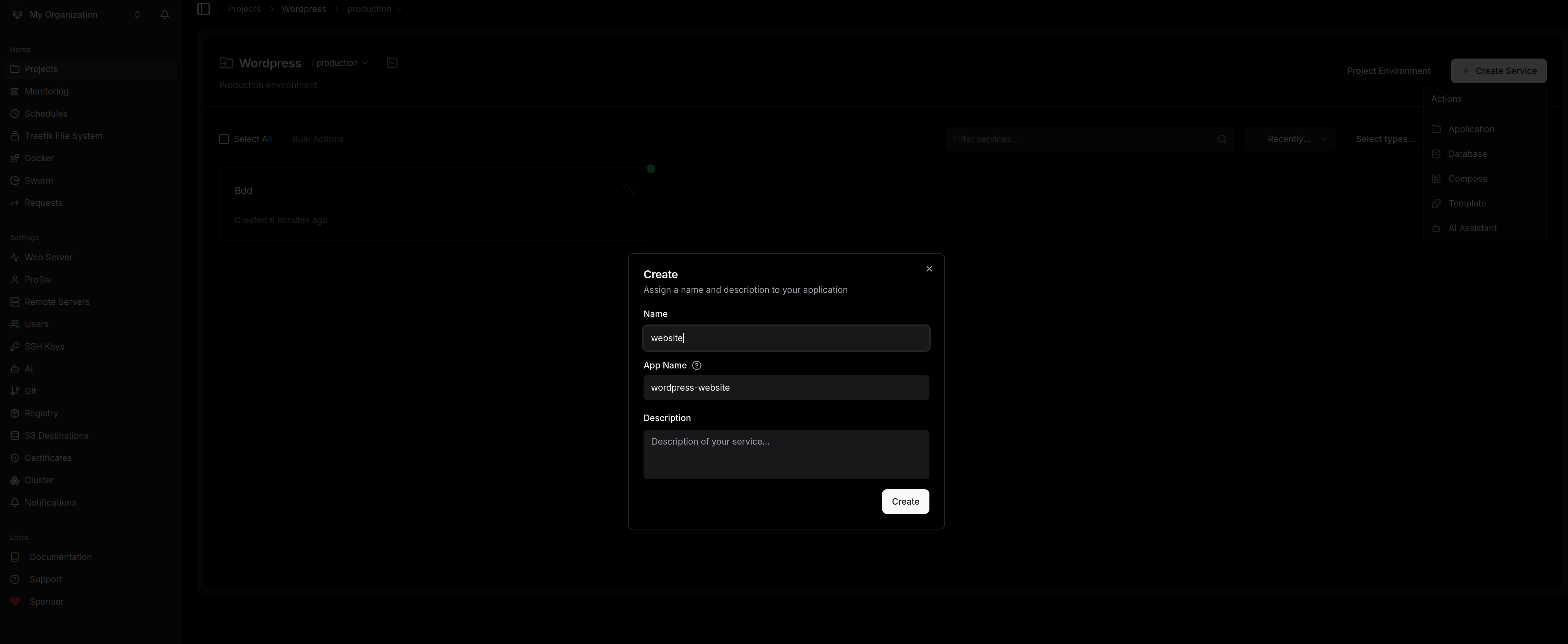
On clique sur le service que l'on vient de créer pour le configurer :
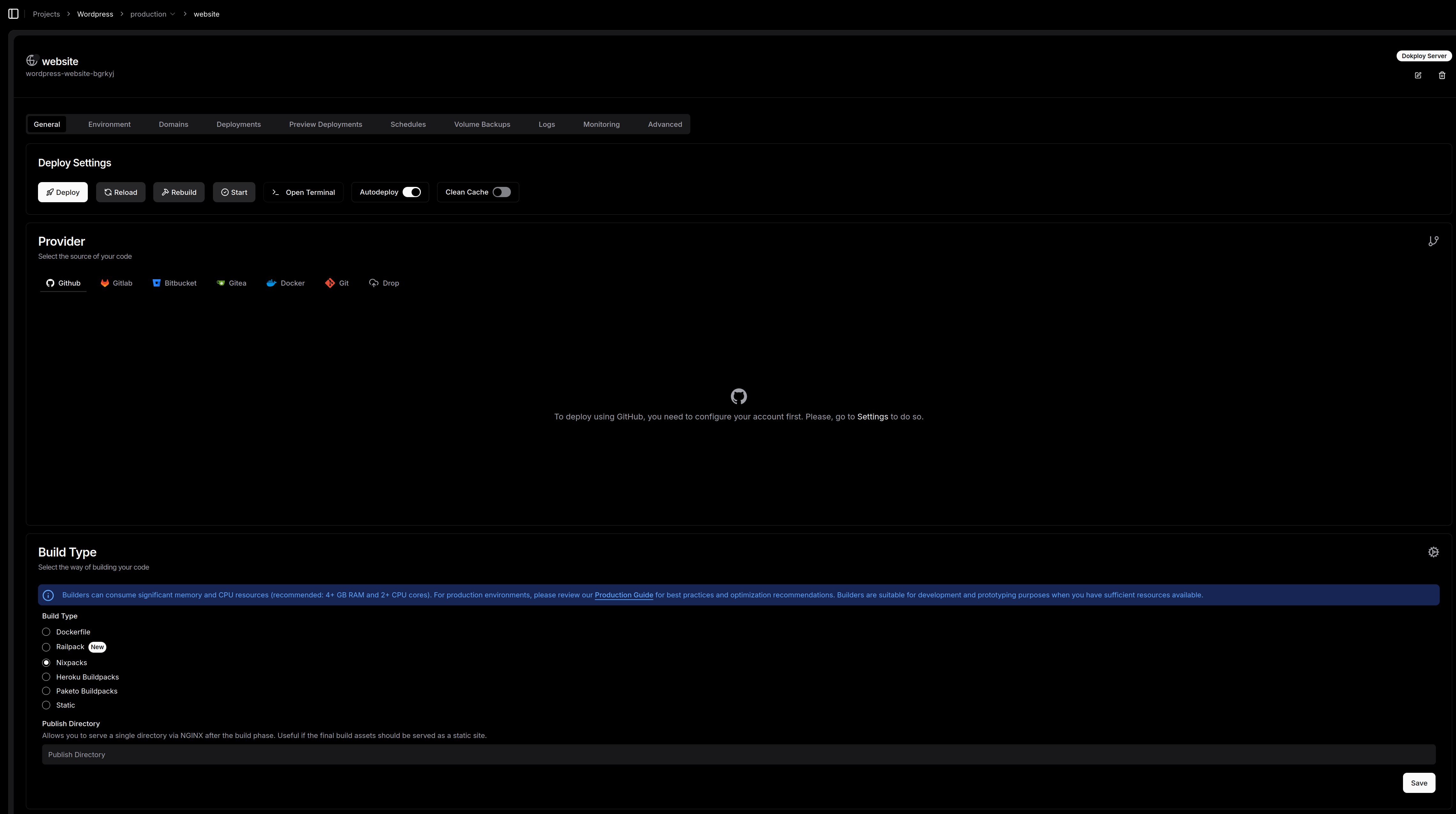
Arrétons nous un instant pour rentrer dans le détail de cette interface de configuration:
C'est ici que la magie du PaaS opère. Une fois votre projet créé (ici je l'ai nommé "Wordpress"), on rentre dans le vif du sujet avec la configuration de notre service. L'interface de déploiement est un modèle du genre : complète mais sans fioritures.
Le pilotage du déploiement
En haut de page, on retrouve nos commandes de vol habituelles : Deploy, Reload, Rebuild ou encore Start. Mention spéciale pour le bouton Open Terminal qui permet de garder un pied dans le conteneur sans quitter son navigateur. On peut aussi activer l'Autodeploy pour que chaque push sur votre branche déclenche la mise à jour, ou forcer un Clean Cache si vous avez des doutes sur votre build.
Le choix de la source (Provider)
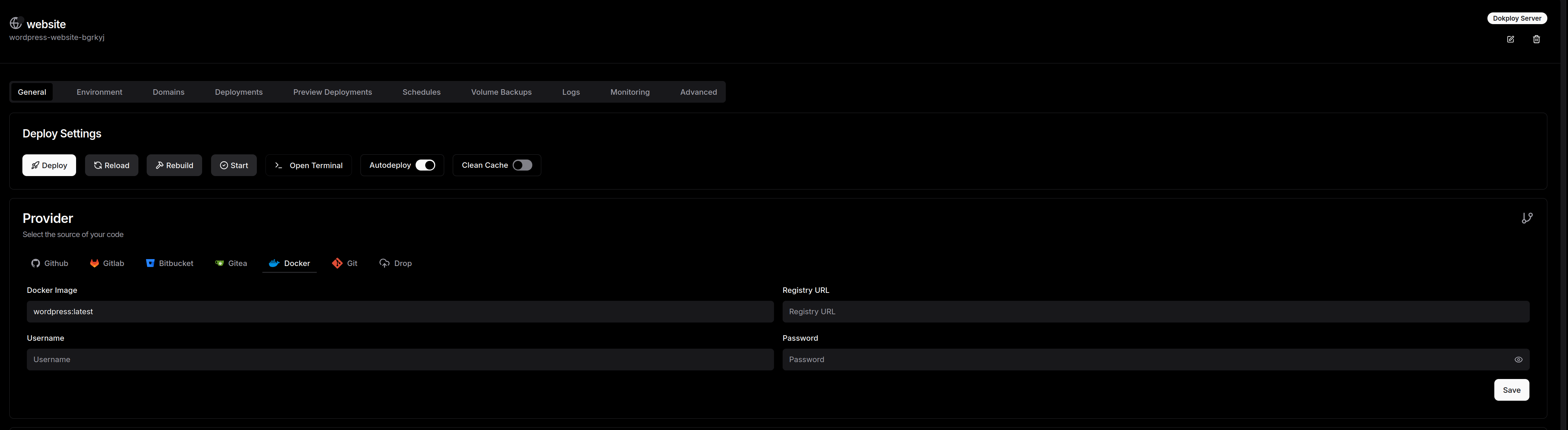
Dokploy est très souple sur l'origine du code :
-
Git pur jus : Intégration directe avec GitHub, GitLab, Bitbucket ou même une instance Gitea auto-hébergée (cohérent avec notre approche souveraine).
-
Docker : Vous pouvez aussi simplement tirer une image depuis un registre Docker.
-
Drop : Pour les plus pressés, on peut même envoyer directement un fichier.
La cuisine interne : Build Type
C'est là que l'admin va pouvoir choisir sa méthode préférée pour transformer le code en conteneur :
-
Dockerfile : Pour ceux qui aiment garder le contrôle total sur leur image.
-
Nixpacks (par défaut) : C’est l'option moderne qui analyse votre code et crée l'image optimale tout seul.
-
Heroku/Paketo Buildpacks : Pour rester compatible avec les standards du marché.
Petit conseil d'admin : Comme indiqué par l'alerte dans l'interface, le build peut être gourmand en ressources (CPU/RAM). Avec mes 16Go de RAM, je suis large, mais gardez un œil sur vos petites instances lors des phases de compilation.
On retrouve également des onglets cruciaux pour la prod : Environment pour vos variables secrètes, Domains pour le mapping DNS avec SSL automatique, et Volume Backups pour ne pas oublier que la donnée, c'est sacré.
Pour notre usecase nous allons déployer une image wordpress depuis le docker hub, pour cela cliquez sur le provider Docker:
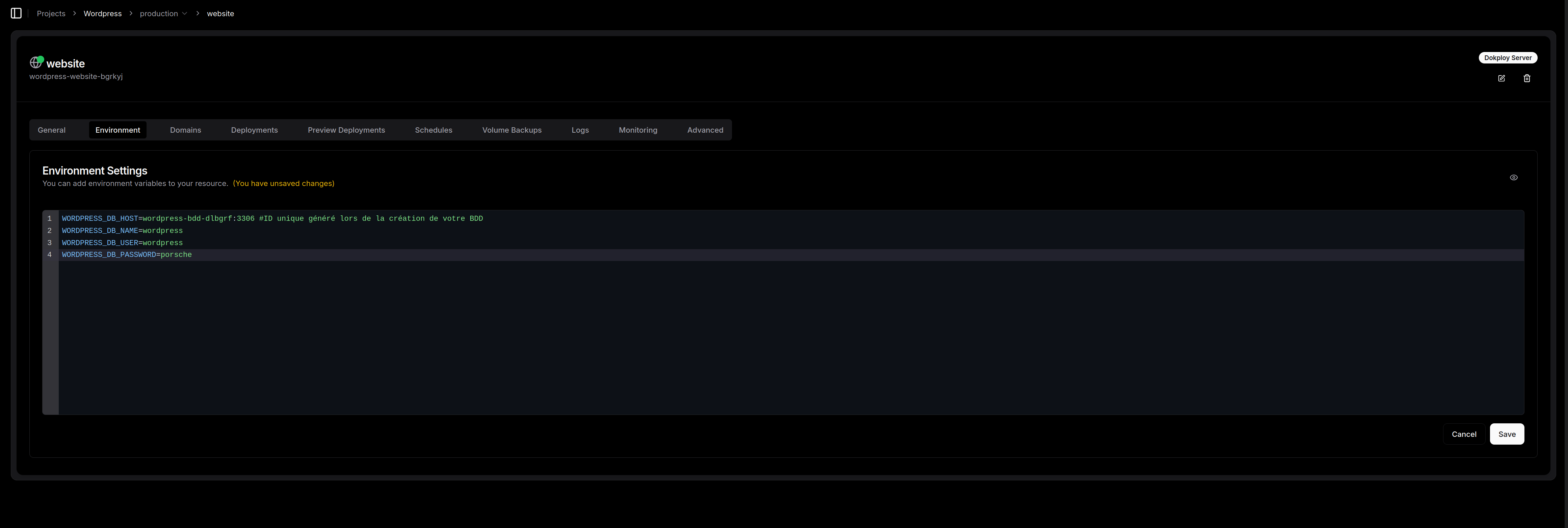
Faisons un petit tour dans l'onglet environnement pour renseigner les informations de connexions à la base de donnée que nous venons de créer juste avant (cliquez sur le petit oeil en haut à droite pour activer le mode édition):
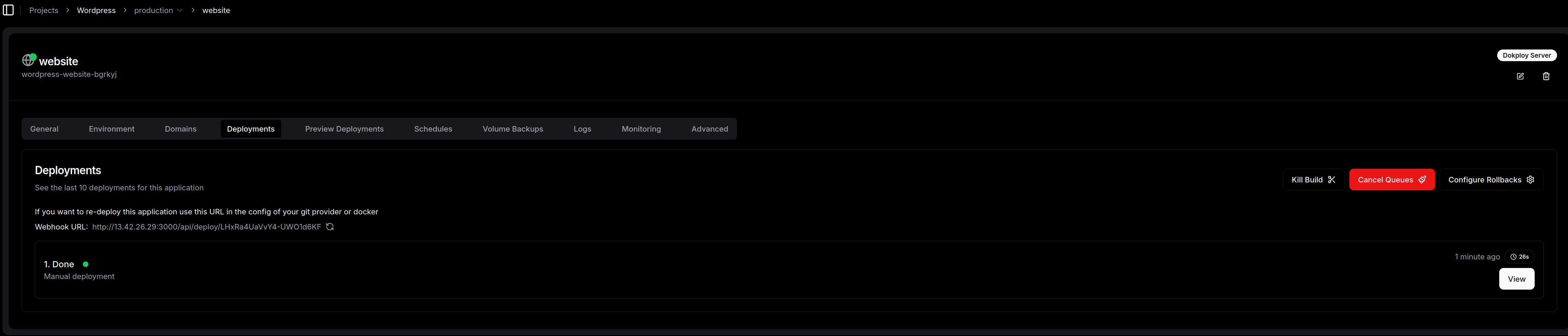
Cliquez sur "save"
L'astuce de sioux : Accéder au site sans DNS avec sslip.io
C’est le moment où l’admin a fini sa conf et veut voir le résultat, mais n’a pas forcément envie d’aller modifier ses zones DNS chez son registrar pour un simple test.
C'est là qu'intervient sslip.io. Pour ceux qui ne connaissent pas, c'est un service de "DNS Wildcard" génial : il résout n'importe quel nom de domaine contenant une adresse IP vers cette même adresse IP.
-
Si vous tapez
13.42.26.29.sslip.io, le service vous renvoie vers13.42.26.29. -
Pas de configuration, pas d'attente de propagation. C'est instantané.
La marche à suivre dans Dokploy :
Cliquez sur domain et "Add Domain"
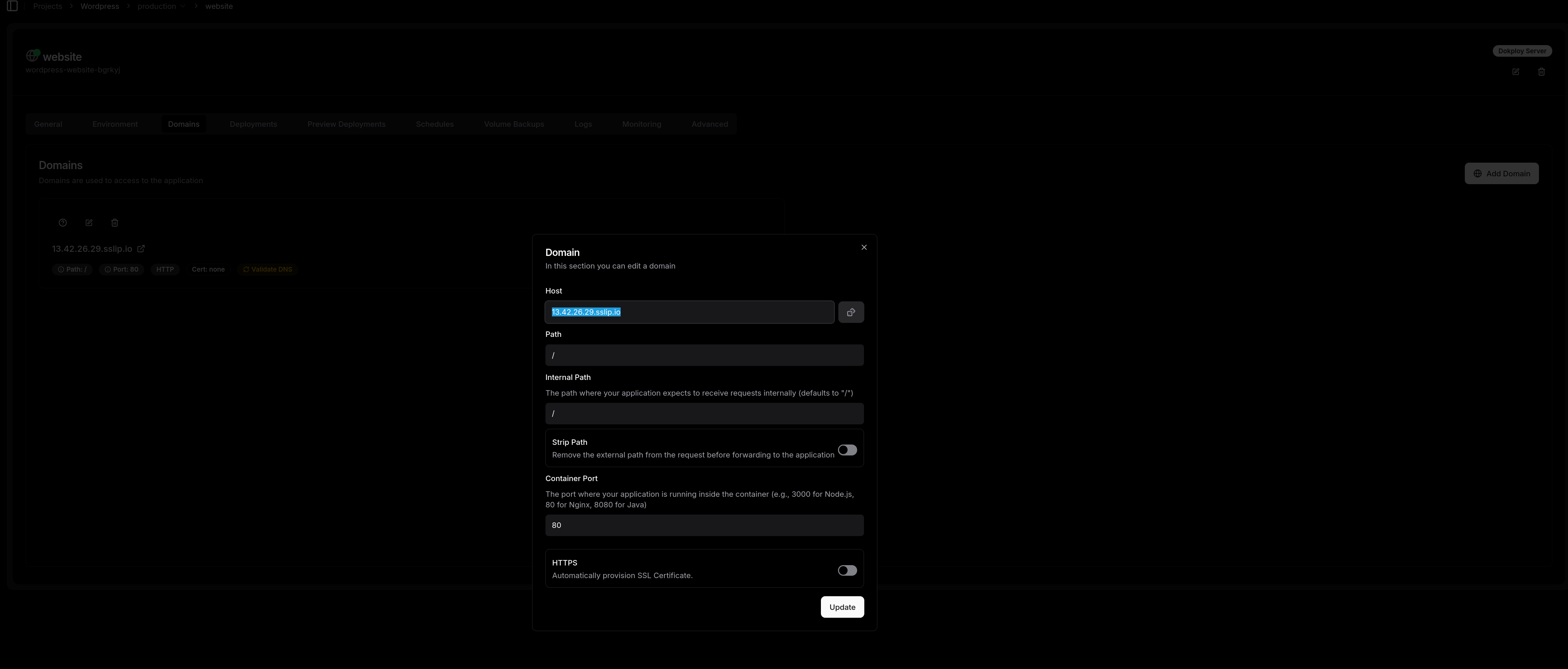
Comme vous le voyez sur ma capture, la configuration est un jeu d'enfant :
-
Host : On renseigne l'IP de notre VM suivie de
.sslip.io(dans mon cas :13.42.26.29.sslip.io). -
Container Port : Attention ici ! C’est le piège classique. Dokploy propose souvent le port 3000 par défaut. Mais notre image WordPress officielle, elle, écoute sur le port 80. Il faut donc impérativement changer cette valeur pour que Traefik sache où envoyer le trafic à l'intérieur du conteneur.
-
HTTPS : Pour un test rapide sur sslip.io, on peut le laisser décoché. Si vous voulez du SSL, Traefik tentera de le générer, mais Let's Encrypt peut parfois tiquer sur les domaines en sslip.io.
Une fois que c'est validé, on retourne dans l'onglet General, on clique sur Deploy, et on laisse la magie opérer.
Maintenant testons l'accès à l'interface de Wordpres:
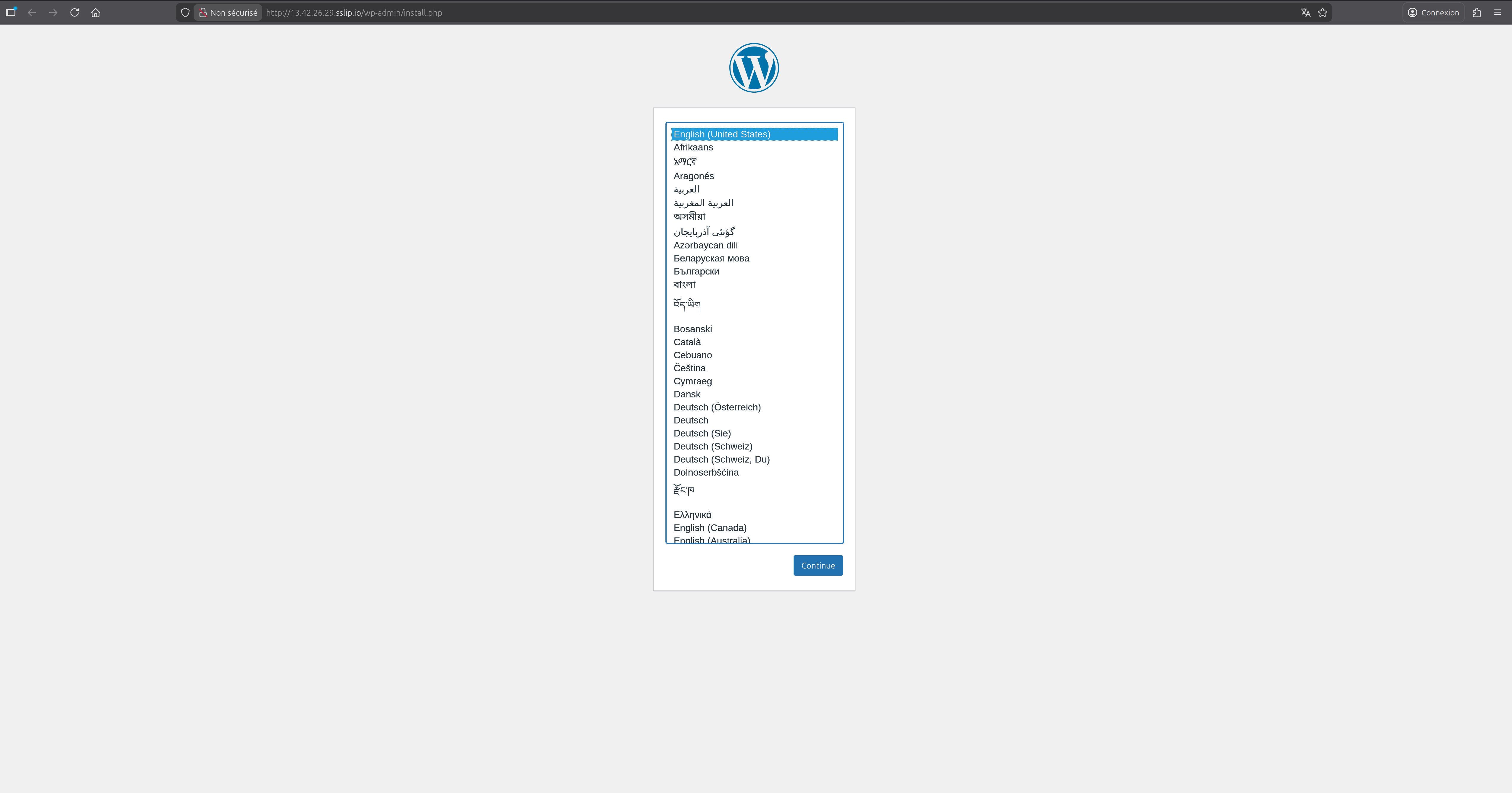
Ca fonctionne!!
4) Le mot de la fin : Dokploy, on valide ou pas ?
Alors, après ce tour d'horizon, quel est le verdict pour un admin habitué à gérer ses propres serveurs ?
Soyons honnêtes : le "tout en ligne de commande", ça a son charme et c’est formateur. Mais à l'heure où l'on doit multiplier les environnements de test, les sites clients ou les outils de monitoring, on ne peut plus se permettre de passer 2 heures à configurer un reverse proxy ou à débugger un certificat SSL récalcitrant.
Dokploy réussit son pari : offrir une expérience PaaS moderne (le fameux "Heroku-like") sans nous enfermer dans un cloud propriétaire. On garde nos données, on garde notre OS (Debian 12 dans mon cas), et surtout, on garde le contrôle sur ce qui tourne.
Ce qu’il faut retenir :
-
C’est rapide : L'installation "One-liner" et le déploiement via sslip.io permettent de voir son projet en ligne en quelques minutes.
-
C'est propre : On s'appuie sur des standards (Docker Swarm, Traefik, Nixpacks) que l'on peut auditer.
-
C'est souverain : Que votre VM soit chez vous, chez un hébergeur local ou sur un gros cloud public, c'est vous qui avez les clés du camion.
Mon conseil : Si vous avez une petite grappe de VPS qui traîne ou un serveur dédié qui ne demande qu'à être optimisé, testez Dokploy. C'est une excellente alternative à Coolify pour ceux qui cherchent une interface peut-être un peu plus légère et réactive.
Le cloud souverain ne se fera pas sans outils simples pour les admins. Dokploy est clairement un pas dans la bonne direction.
Sécuriser Apache2 : Les bonnes pratiques pour protéger votre serveur Web
Article publié le 17 Janvier 2026.
Installer un serveur Apache, c'est l'affaire de deux minutes en apt install. Le rendre prêt pour la production et résistant aux scans automatisés qui pullulent sur le web, c'est une autre histoire.
Aujourd'hui, on fait le tour des configurations indispensables pour durcir (hardener) votre service Apache2 sous Debian/Ubuntu.
1. On cache la version d'Apache et de l'OS
Par défaut, Apache est trop bavard. Il indique sa version et l'OS utilisé dans les signatures d'erreurs. C'est donner des indices précieux à un attaquant.
On modifie le fichier /etc/apache2/conf-enabled/security.conf (ou directement dans apache2.conf) :

2. Désactivation du listing des répertoires
Il n'y a rien de pire que de laisser un attaquant naviguer dans l'arborescence de vos fichiers si vous avez oublié un index.html.
Dans votre configuration de VirtualHost ou dans le répertoire racine :

Note : Le -Indexes désactive le listing, et -FollowSymLinks empêche de suivre des liens symboliques vers l'extérieur du répertoire.
3. Les Headers de sécurité (Le plat de résistance)
C'est ici que l'on gagne des points sur SecurityHeaders.com. Il faut activer le module headers : sudo a2enmod headers
Puis, ajoutez ces lignes dans votre config :
# Protection contre le Clickjacking
Header always set X-Frame-Options "SAMEORIGIN"
# Protection contre le XSS
Header set X-XSS-Protection "1; mode=block"
# Désactivation du sniffing de type MIME
Header set X-Content-Type-Options "nosniff"
# Referrer Policy
Header set Referrer-Policy "no-referrer-when-downgrade"
# HSTS (A n'activer que si vous avez un certificat SSL valide !)
Header always set Strict-Transport-Security "max-age=31536000; includeSubDomains"
4. Désactiver les méthodes HTTP inutiles
La plupart du temps, vous n'avez besoin que de GET, POST et HEAD. Les méthodes TRACE ou TRACK peuvent être utilisées pour des attaques de type Cross-Site Tracing.
TraceEnable Off
<Location "/">
AllowMethods GET POST HEAD
</Location>
5. Utiliser Fail2Ban pour bannir les bruteforcers
Apache génère des logs, autant s'en servir. Si vous ne l'avez pas encore, installez Fail2Ban pour bloquer les IPs qui cherchent des failles via des 404 à répétition.
Dans votre /etc/fail2ban/jail.local :
[apache-noscript]
enabled = true
port = http,https
filter = apache-noscript
logpath = /var/log/apache2/error.log
maxretry = 3
Si vous ne vous souvenez plus comment installer fail2ban n'hésitez pas à jeter un coup d'oeil à mon article 😉 https://journaldunadminlinux.fr/tutoriel-protegez-votre-serveur-avec-fail2ban/
Conclusion
Avec ces quelques modifications, vous réduisez drastiquement la surface d'attaque de votre serveur. N'oubliez pas de tester votre configuration avec un petit apache2ctl configtest avant de redémarrer le service !
Comme toujours, la sécurité est un processus continu. Gardez vos paquets à jour avec un apt update && apt upgrade régulier.
Générez automatiquement vos fichiers docker compose avec docker-autocompose
Article publié le 17 Février 2020.
J'ai découvert aujourd'hui un petit outil fortement sympathique qui pourrait servir à beaucoup de monde: docker-autocompose
Docker-autocompose permet de générer à partir d'un container existant le fichier docker-compose associé ce qui peut faire gagner du temps et s'avérer très pratique.
1) Prérequis
Docker-autocompose est codé en python, de ce fait il est nécessaire d'avoir les modules suivants d'installés:
- pyaml
- docker-py
- setup-tools
Une petite installation via le gestionnaire de paquet de votre distribution ou via pip suffira.
2) Installation
L'adresse du repository git du projet: https://github.com/Red5d/docker-autocompose
- Cloner le repo:
git clone https://github.com/Red5d/docker-autocompose
- Exécutez le script d'installation situé dans le répertoire docker-autocompose:
chmod 700 *.py && sudo python setup.py && sudo cp autocompose.py /usr/local/bin
- Testez votre installation

3) Fonctionnement
Maintenant nous allons tester le fonctionnement de cet outil fort sympathique.
- Nous allons, dans un premier temps, pour alimenter notre test, créer un container nginx:
docker run -d -p 80:80 nginx
- On vérifie que notre container tourne correctement:
docker ps -a
![]()
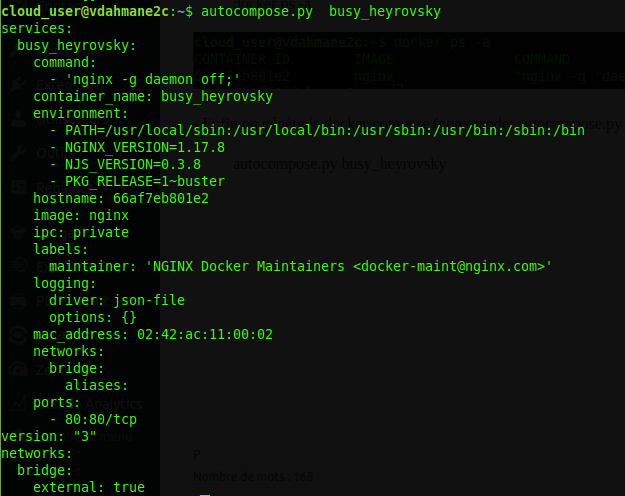
- Enfin on génère le docker-compose (commande: autocompose.py <nom ou id de votre container>):
autocompose.py busy_heyrovsky
Enjoy 😉
Tutoriel | Découverte de Prometheus et Grafana
Article publié le 28 Décembre 2018
Je profite du calme des fêtes de fin d'année pour vous faire partager ma veille techno sur l'outil de supervision Prometheus. Cet outil de supervision est l'un des plus puissants que j'ai pu tester! Dans ce tutoriel, vous trouverez toutes les manipulations que j'ai faites pour tester ce produit. Durant mes tests, je me suis servis de deux machines. L'une hébergeant prometheus et Grafana et la seconde qui hébergera les services à monitorer.
Je vais expliquer dans un premier temps comment installer Prometheus. Ensuite, je vais superviser une machine Linux hébergeant un service Apache et une base de données Mysql.
Enfin, je brancherai un Grafana sur mon prometheus pour avoir de jolies graph!
1) Fonctionnement de Prometheus

Prometheus récupère toutes les metric de ce que vous voulez monitorer grâce à un composant qui s’appelle "Exporter". En gros considérez l'exporter comme un agent de monitoring classique.
Le gros avantage est qu'il existe un exporter pour quasiment tout! Vous pouvez trouver la liste des exporter ci-dessous:
https://prometheus.io/docs/instrumenting/exporters/
2) Installation et configuration de prometheus
- Téléchargez la dernière version des sources de prometheus:
https://prometheus.io/download/
- Décompressez l'archive
tar -xvf prometheus-* && cd prometheus-*
- Éditez le fichier prometheus.yml et remplacez le contenu par la configuration suivante:
global:
scrape_interval: 15s
evaluation_interval: 15srule_files:
# - "first.rules"
# - "second.rules"scrape_configs:
- job_name: prometheus
static_configs:
- targets: ['localhost:9090']
- Lancez Prometheus (en mode crado mais rien ne vous empêche de faire un service systemd propre! 😉 )
./prometheus --config.file=prometheus.yml
- On va ensuite créer un reverse proxy apache afin de pouvoir afficher l'interface Web de prometheus bindé sur le localhost (installez apache2 et activez le mode proxy)
Ci-dessous le contenu du virtualHost (j'ai renseigné mon fichier host pour faire pointer prometheus.local vers l'ip de ma machine)
<VirtualHost *:80>
ServerName prometheus.local
CustomLog ${APACHE_LOG_DIR}/prometheus.local.log combined
ErrorLog ${APACHE_LOG_DIR}/prometheus.local-error.log
LogLevel warnProxyPreserveHost On
ProxyPass / http://localhost:9090/
ProxyPassReverse / http://localhost:9090/</VirtualHost>
- Si tout s'est bien passé vous devriez pouvoir afficher l'interface Web de Prometheus:
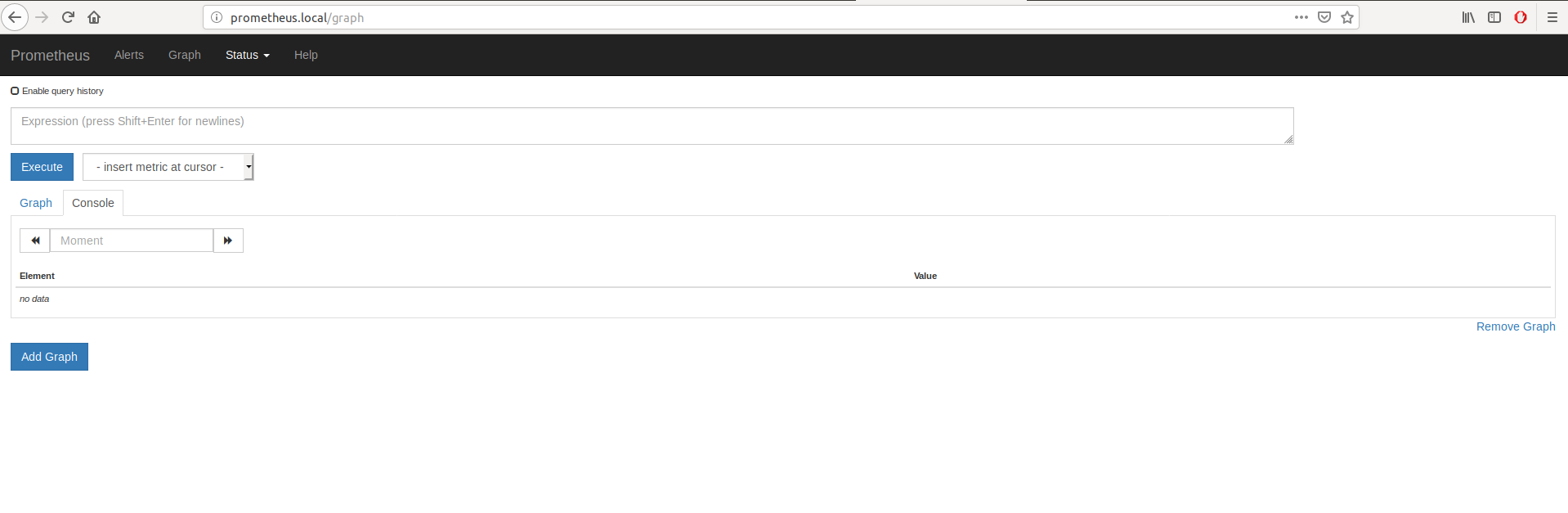
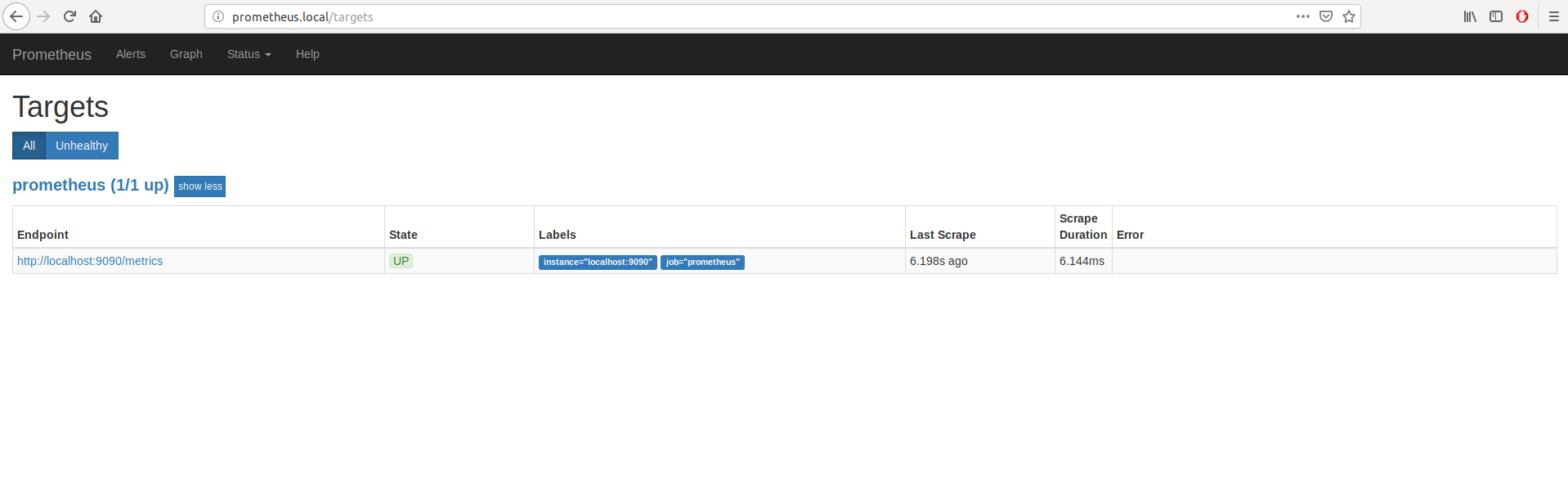
- Cliquez sur l'onglet "Status" puis "Targets" pour voir tout ce qui est monitoré par Prometheus (pas grand chose pour le moment):
3) Configuration des exporters
Comme je l'ai dit précédemment, nous allons monitorer sur notre serveur cible les métrique de l'OS, Apache2 et MySQL.
Pour rappel la liste de tout les exporter est disponible via ce lien: https://prometheus.io/docs/instrumenting/exporters/ (un Exporter est un "agent" à installer sur le serveur à monitorer)
3.1) Monitoring de l'OS (Distribution Linux)
Nous allons pour cela utiliser le "node exporter".
Télécharger la dernière version de go: https://golang.org/dl/
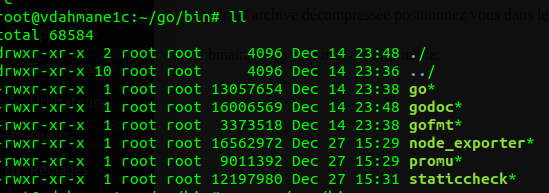
Une fois l'archive décompressée positionnez vous dans le répertoire bin.
Le binaire node_exporter est disponible:
- Lancez-le
./node_exporter &
- Il ne reste plus qu'à modifier le fichier de configuration (sur votre serveur prometheus) prometheus.yml et y rajouter la configuration suivante avant de redémarrer votre service prometheus:
- job_name: LinuxServer
scrape_interval: 5s
static_configs:
- targets: ['<ip de votre machine>:9100']
- Logiquement la target devrait apparaître depuis l'interface web de Prometheus:

3.2) Monitoring d'une instance Apache2
Prérequis: le paquet Golang doit être installé
- Créer un répertoire go dans votre répertoire de travail.
- On alimente le GO PATH:
export GOPATH=<répertoire de travail>/go
- On télécharge apache_exporter
go get github.com/neezgee/apache_exporter
- On lance le apache_exporter
<répertoire de travail>/go/bin/apache_exporter &
- Il ne reste plus qu'à modifier le fichier de configuration (sur votre serveur prometheus) prometheus.yml et y rajouté la configuration suivante avant de redémarrer votre service prometheus:
- job_name: ApacheServer
scrape_interval: 5s
static_configs:
- targets: ['<ip de votre machine>:9117']
- Logiquement la target devrait apparaître depuis l'interface web de Prometheus:

3.3) Monitoring d'une base de donnée MySQL
- Récupérez sur le GITHUB de prometheus la dernière version de l'exporter mysqld: https://github.com/prometheus/mysqld_exporter/releases
- Décompressez l'archive précédemment téléchargée sur votre serveur hébergeant votre base de donnée MySQL
- Connectez-vous sur votre base de donnée et lancez les deux requêtes suivantes:
CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'passwordexporter' WITH MAX_USER_CONNECTIONS 3;
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
FLUSH PRIVILEGES;
- Alimentez la variable d'environnement avec les identifiants du user exporter précédemment créés:
export DATA_SOURCE_NAME='exporter:<motdepasseduuserexporter'@(hostname:3306)/'
- Lancez l'exporter mysqld:
export DATA_SOURCE_NAME='exporter:toto@(hostname:3306)/'
- Il ne reste plus qu'à modifier le fichier de configuration (sur votre serveur prometheus) prometheus.yml et y rajouté la configuration suivante avant de redémarrer votre service prometheus:
- job_name: MySQL
scrape_interval: 5s
static_configs:
- targets: ['<ip de votre machine>:9104']
- Logiquement la target devrait apparaître depuis l'interface web de Prometheus:

4) Grafana
Il ne reste plus qu'à interfacer les metrics récoltées par prometheus via les exporters que nous avons installé sur notre machine cible avec un Grafana.
L'installation de Grafana est très simple et est disponible sur le site officiel:
- Debian/Ubuntu: http://docs.grafana.org/installation/debian/
- Centos/RedHat: http://docs.grafana.org/installation/rpm/
4.1) Configuration du Datasource Prometheus
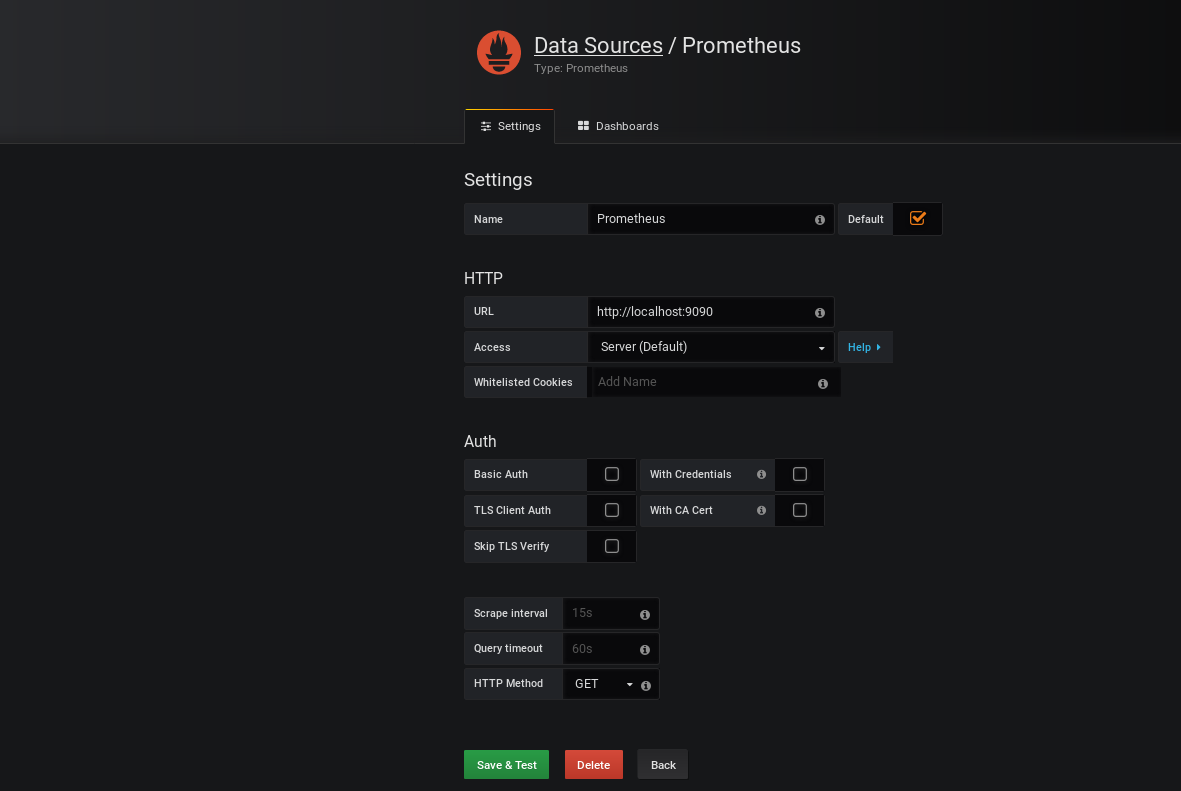
Dans un premier temps, nous allons configurer le datasource prometheus dans Grafana (afin qu'il soit directement connecté avec notre serveur prometheus). Dans ce tuto j'ai installé Grafana sur la même machine que Prometheus.
- Cliquez sur la roue dentée situé dans la bar de menu à gauche:
- Cliquez sur le bouton "Add Data source" puis cliquez sur "Prometheus"
- Renseignez les informations demandées comme l'image ci-dessous puis cliquez sur le bouton "Save & Test"
4.2) Création du Dashboard Node Exporter (les métriques de notre OS)
Pour cela inutile de réinventer la roue. Des dashboard tout prêt sont fournis gracieusement par la communauté Grafana: https://grafana.com/dashboards
En recherchant j'ai trouvé ce dashboard:
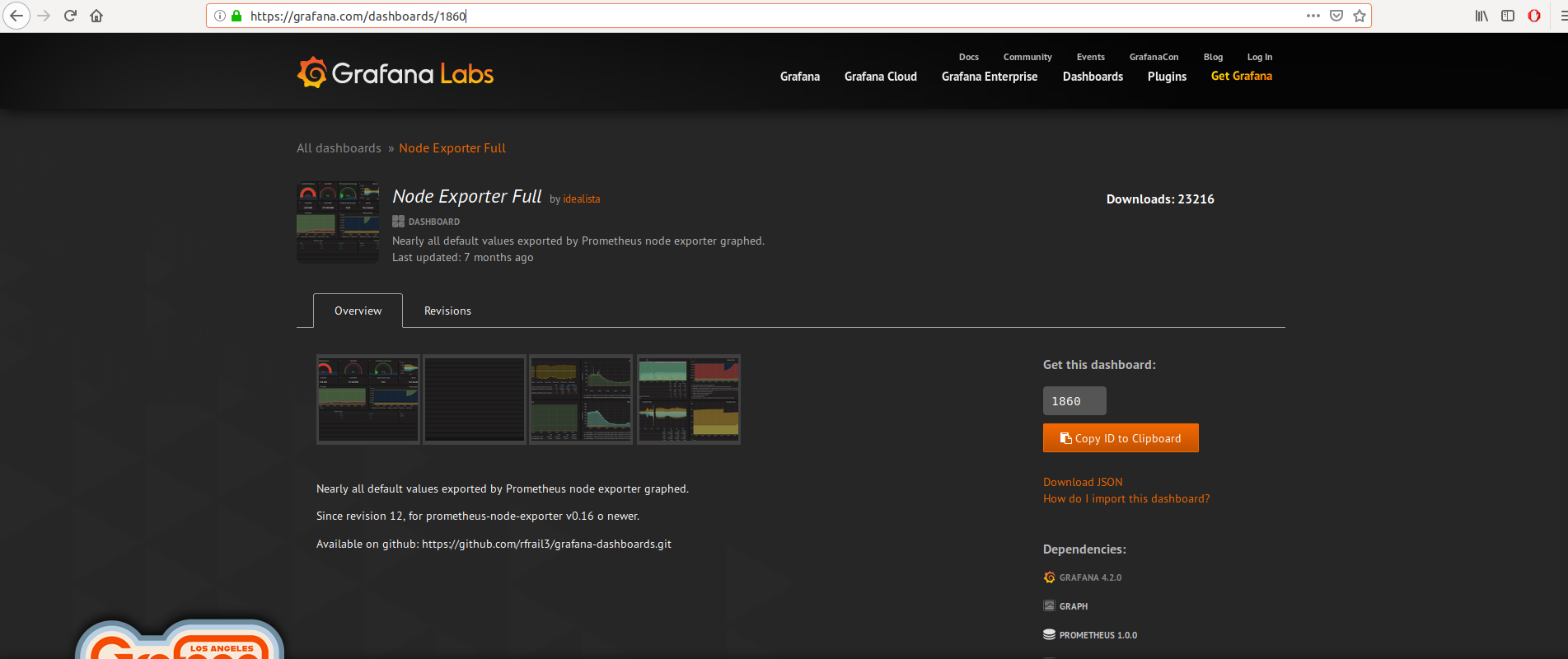
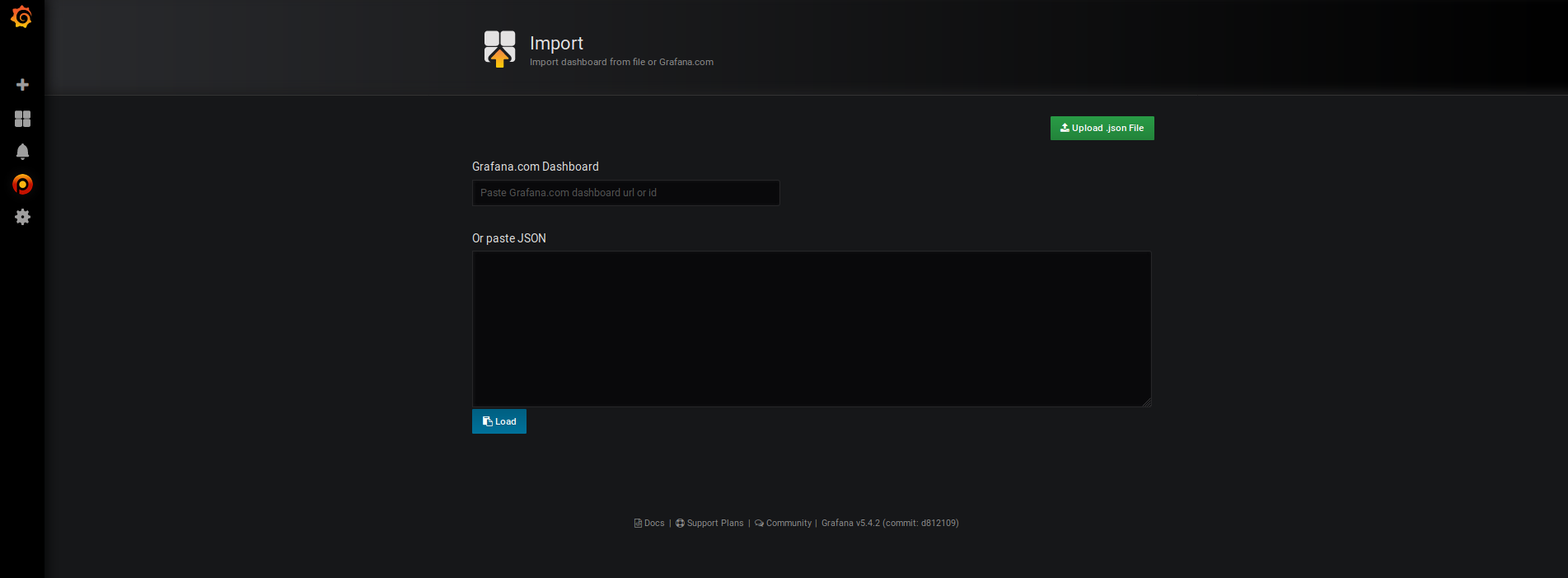
Conservez l'ID du dashboard.
- Cliquez sur le bouton "+" sur la gauche de l'interface puis sur "import"
- Renseignez l'ID du dashboard que l'on a récupéré sur le site de Grafana dans le 1er champ (1860).
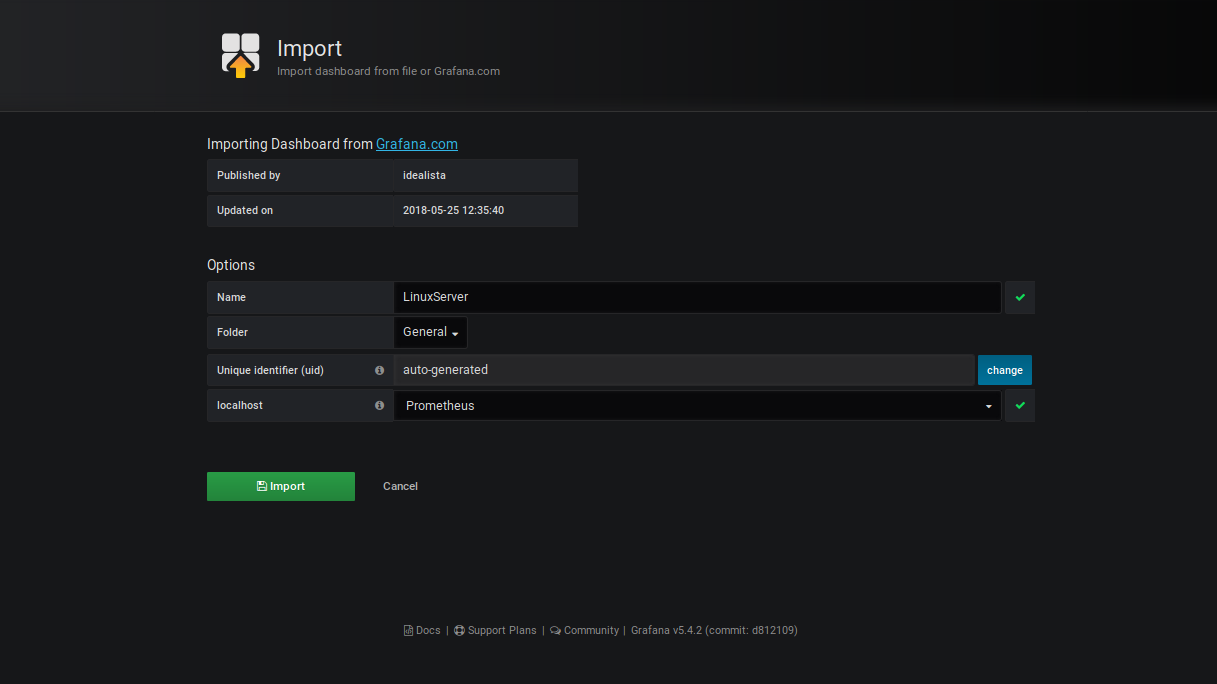
- Renseignez les champs comme la capture ci-dessus puis cliquez sur le bouton "Import"
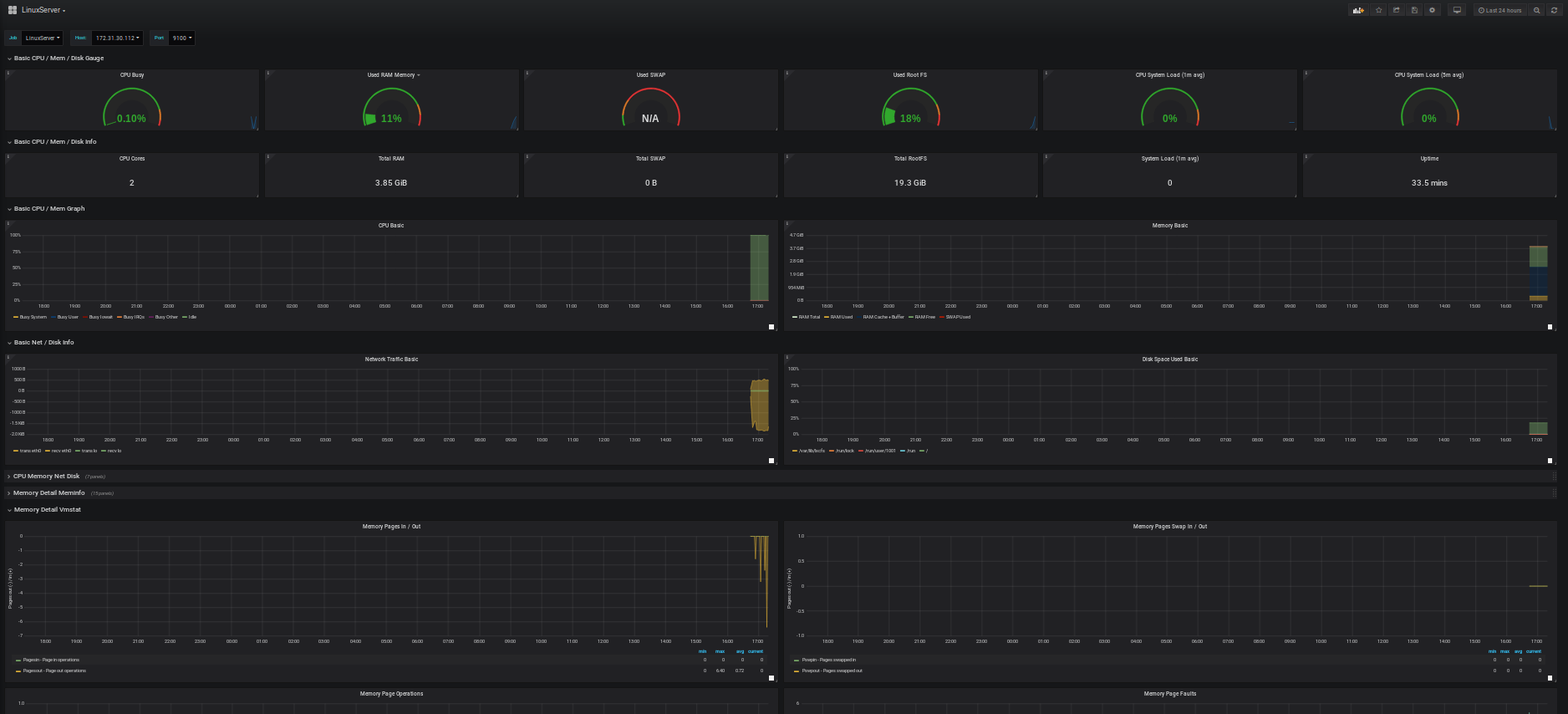
- Il ne reste plus qu'à profiter de vos graph!
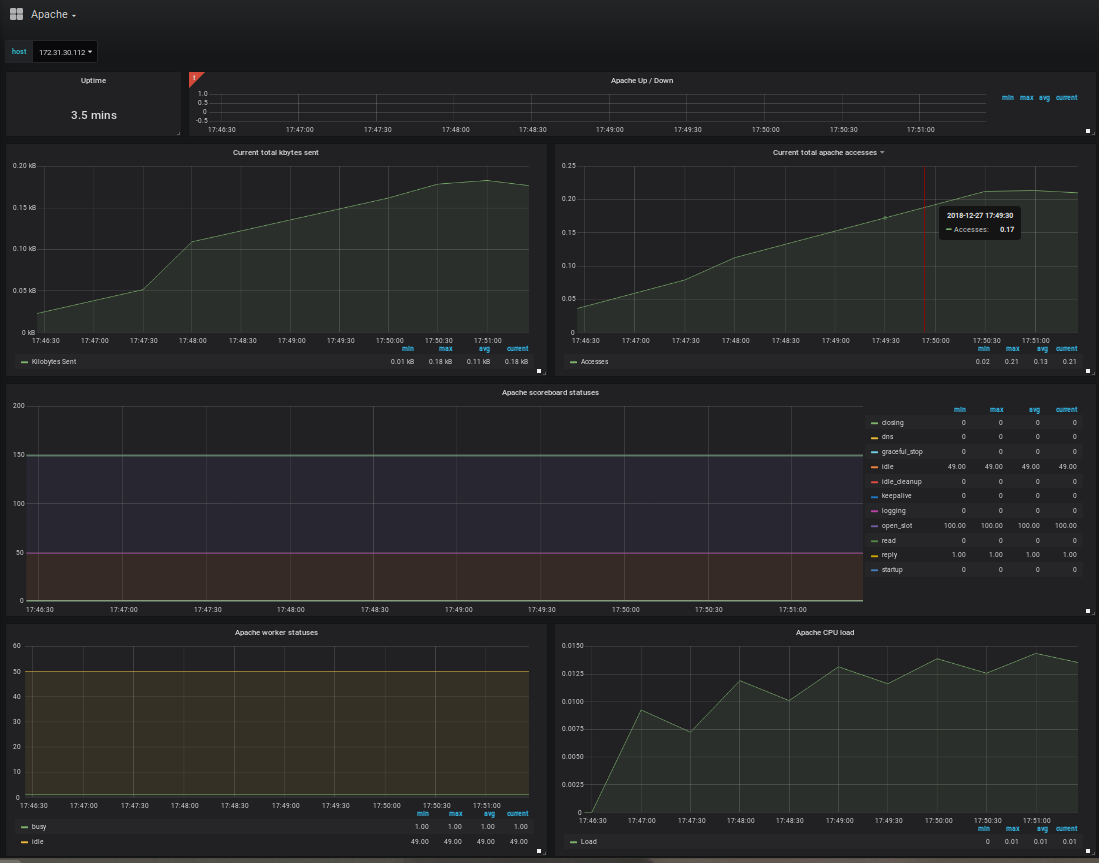
4.3) Création du Dashboard Apache
Même méthode que pour le dashboard node-exporter (partie 4.2 de ce tutoriel), importez le dashboard id 3894.
4.4) Création du Dashboard MySQL
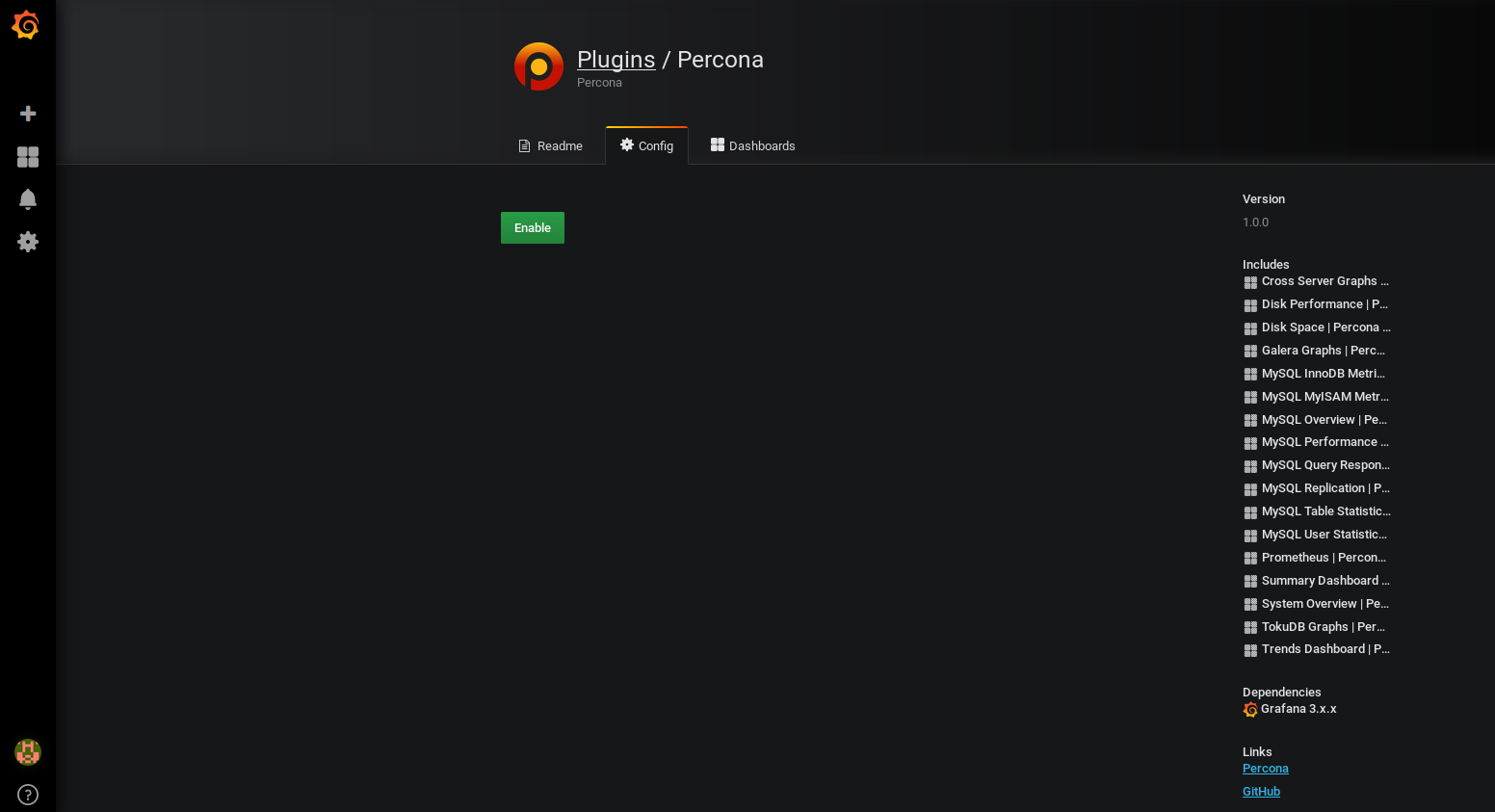
La marche à suivre pour le Dashboard MySQL est un peu différente car nous allons utiliser le plugin grafana Percona qui se sert du datasource Prometheus.
- Cliquez sur la route dentée à gauche puis sur "plugins", puis cliquez sur "Percona"

- Cliquez sur "Enable":
- Cliquez sur ensuite sur l'onglet Dashboard et importez les Dashboard qui seraient susceptible de vous intéresser (sinon importez les tous !)
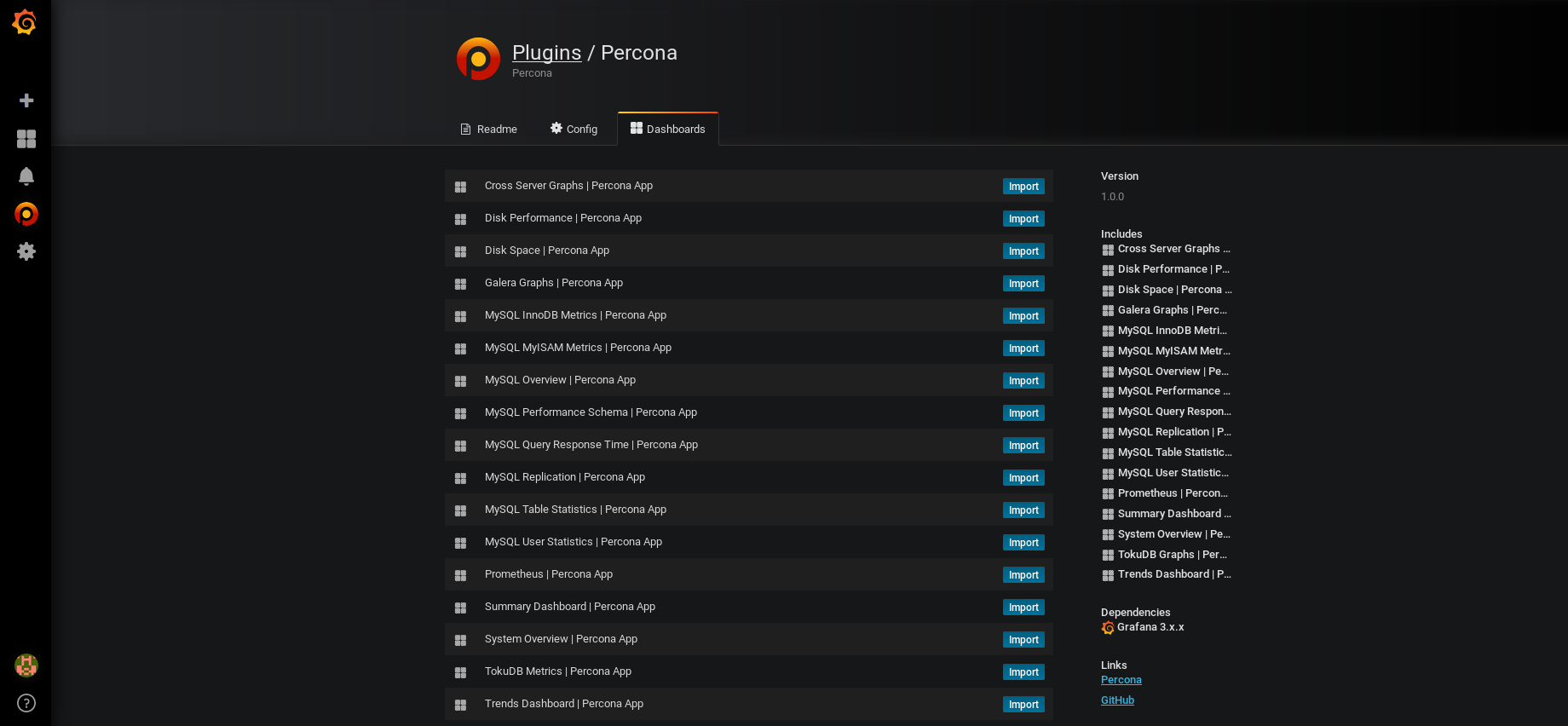
- Normalement, les Dashboard suivants ont été rajoutés automatiquement (où ceux que vous avez spécifiquement séléctionnés):
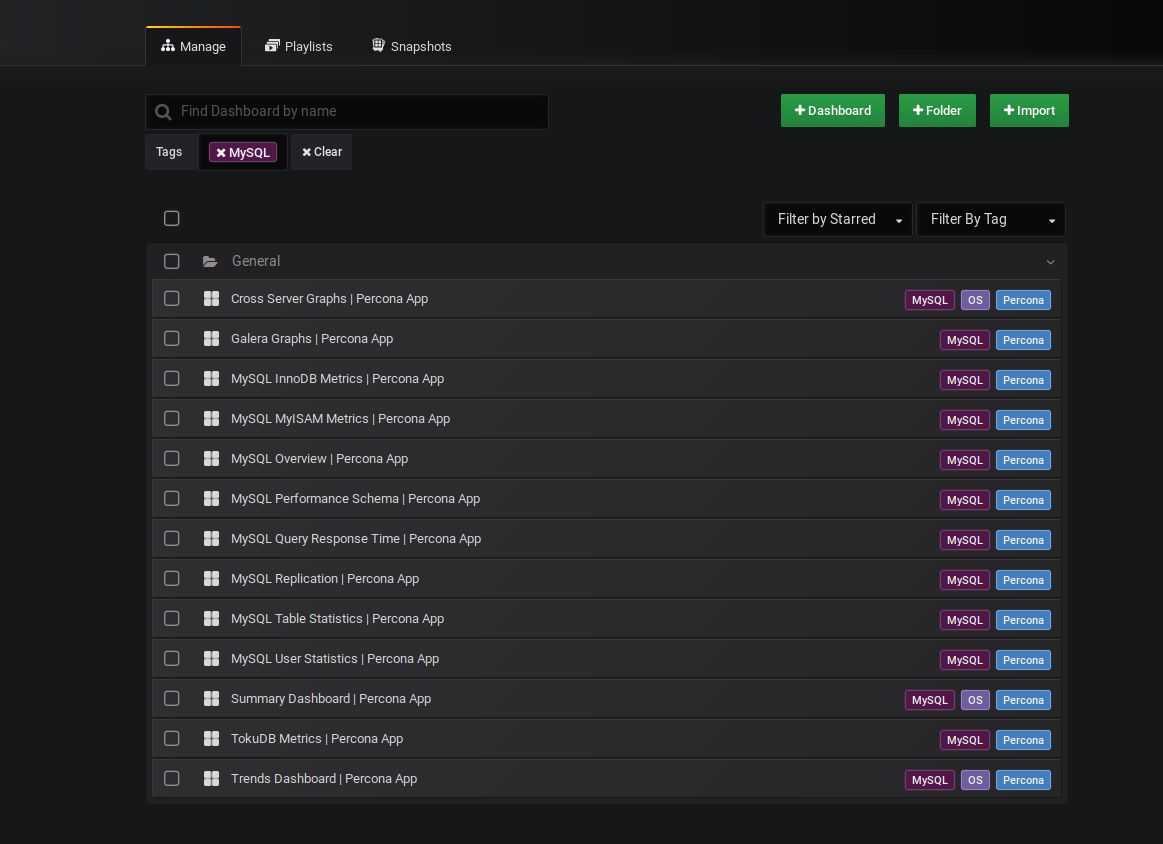
- En cliquant sur l'un d'eux (par exemple MySQL Overview) vous devriez voir apparaître vos Graph:
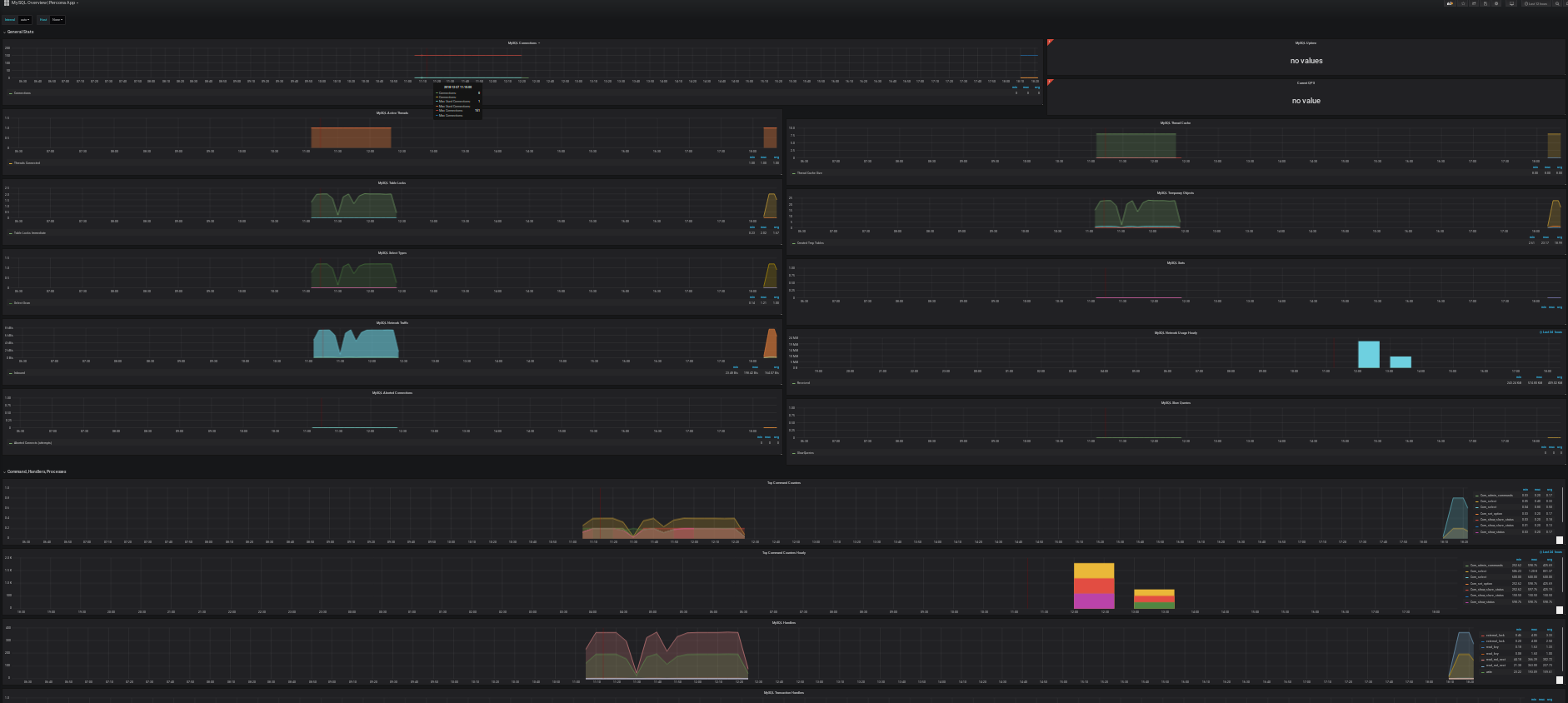
Enjoy!
Tutoriel | Configurer la réplication master/slave d’une instance PostgreSQL
Article publié le 7 Septembre 2018
Un petit tutoriel sur la manière la plus facile de mettre en place une réplication Master/Slave d'une instance PostgreSQL. Une réplication Master/Slave est extrêmement utile. Elle vous permettra d'avoir un failover et donc une continuité de service en cas de perte de votre master mais également de répartir la charge en redirigeant toute les requête read-only (select) sur votre slave.
Dans ce tutoriel, deux instances PostgreSQL seront installées sur deux machines distinctes.
 La version utilisée lors de la rédaction de ce tutoriel est la version 10. Si vous utilisez une version différente de postgresql, ce tutoriel sera toujours valable, seul le chemin du répertoire d'installation de postgresql et certaines commandes changeront légèrement.
La version utilisée lors de la rédaction de ce tutoriel est la version 10. Si vous utilisez une version différente de postgresql, ce tutoriel sera toujours valable, seul le chemin du répertoire d'installation de postgresql et certaines commandes changeront légèrement.
1) Configuration du Master
- Éditez votre fichier postgresql.conf (sa localisation diffère en fonction de la distribution et de la version de PostgreSQL installé) et faites les modifications suivantes:
listen_addresses = '*'
wal_level = hot_standby
max_wal_senders = <nombre de noeuds dans votre cluster> # Logiquement 2 dans notre cas master/slavesynchronous_standby_names = '<hostname du master>'wal_keep_segments = 100
- Créez un user dédié à la réplication via cette requête SQL:
create user replica replication;
- Éditez le fichier pg_hba.conf et rajoutez la ligne suivante (permettant ainsi la connexion de votre slave sur votre master):
host replication replica <ip de votre slave> trust
- Redémarrez enfin votre service PostgreSQL
2) Configuration du Slave
- Arrêtez votre instance PostgreSQL.
- Supprimez tout le contenu du répertoire data situé dans le répertoire d'installation de votre instance PostgreSQL
- Lancez la commande suivante afin d'établir le lien avec votre master:
pg_basebackup -D <pgsql_path>/data -h <ip ou fqdn du master> -U replica
- Éditez ou créez si il n'existe pas déja le fichier recovery.conf situé dans le répertoire data et ajoutez y les lignes suivantes:
standby_mode=ontrigger_file='/tmp/promotedb'primary_conninfo='host=<ip ou fqdn du master> port=5432 user=replica application_name='<valeur de synchronous_standby_name indiqué dans le postgresql.conf du master>'
- Changez le owner du répertoire data (suite à sa précédente suppression celui ci a été recréé avec le user root):
chown -R postgres:postgres <pgsql_path>/data
hot_standby=on
/usr/pgsql/bin/pg_ctl-10 -D /var/lib/pgsql/10/data start
3) Test
Afin de rédiger ce tuto j'ai utilisé 2 machines: vdahmane5 comme master et vdahmane6 comme slave.
Pour tester, j'ai créé une nouvelle base de données sur le master:
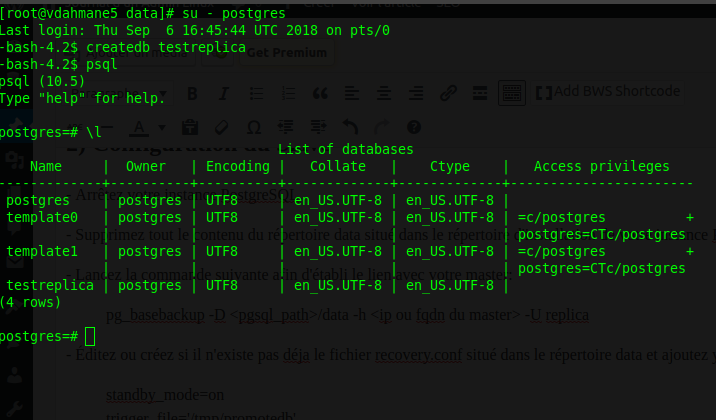
Je me connecte ensuite sur le slave et vérifie que la création de la base "testreplica" a bien faite:
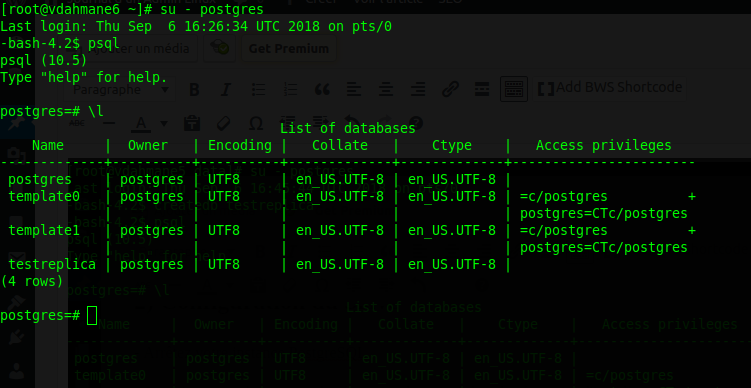
La réplication fonctionne!
Attention toutefois, si jamais des données sont directement insérées dans le slave, votre réplication sera par terre. Il vous faudra la reconstuire.
Tutoriel | Installez facilement un cluster Kubernetes sous Debian ou Centos
Article publié le 20 Août 2018
Aujourd'hui un petit tutoriel sur l'installation d'un Cluster Kubernetes. La procédure ci-dessous vous indiquera la méthode la plus simple pour installer Kubernetes.
Pour exemple et également pour tester ce tutoriel, mon cluster sera composé d'un master et de deux workers.
1) Installation sous Debian/Ubuntu
- Installez la version de Docker supporté par Kubernetes (sur chaque node):
apt-get update
apt-get install -y apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add -
add-apt-repository "deb https://download.docker.com/linux/$(. /etc/os-release; echo "$ID") $(lsb_release -cs) stable"
apt-get update && apt-get install -y docker-ce=$(apt-cache madison docker-ce | grep 17.03 | head -1 | awk '{print $3}')
- Activez le démarrage automatique de Docker (sur chaque nodes) :
systemctl enable docker
- Paramétrez Docker afin qu'il utilise exclusivement systemd, pour cela éditez le fichier /etc/docker/daemon.json et ajoutez le contenu suivant avant de redémarrer le service Docker (sur chaque nodes):
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
- Ajoutez les repo Kubernetes (sur chaque nodes):
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <<EOF >/etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get update
- Désactivez le swap (sur chaque nodes)
swapoff -a
N'oubliez pas de commenter la ligne dans le fstab
- Installez les outils Kubernetes (sur chaque nodes)
apt-get install kubelet kubeadm kubectl
- Initialisez le cluster (sur le master uniquement)
kubeadm init --pod-network-cidr=10.244.0.0/16
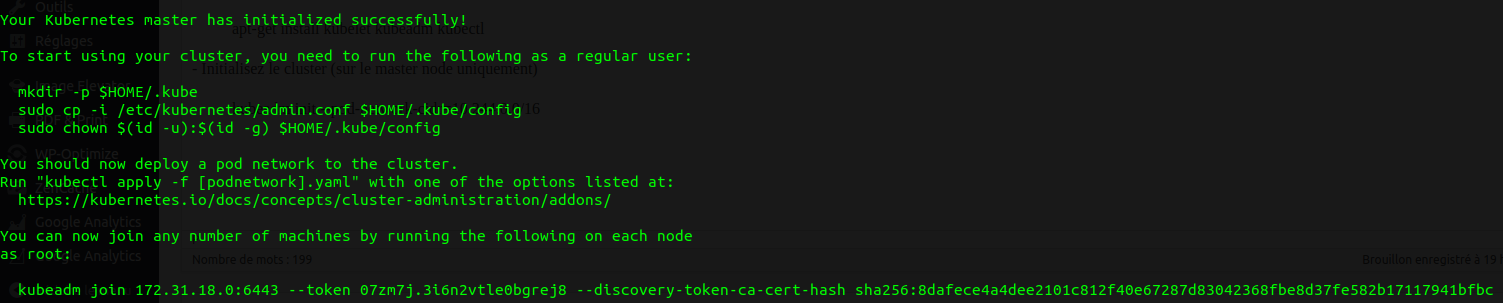
Faites ce qui est indiqué à l'écran et gardez dans un coin la commande "kubeadm join" qui nous permettra plus tard de rattacher des workers à notre Cluster.
- Installez les composants network Kubernetes (sur le master uniquement)
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.9.1/Documentation/kube-flannel.yml
- Vérifiez que l'installation se soit bien passé
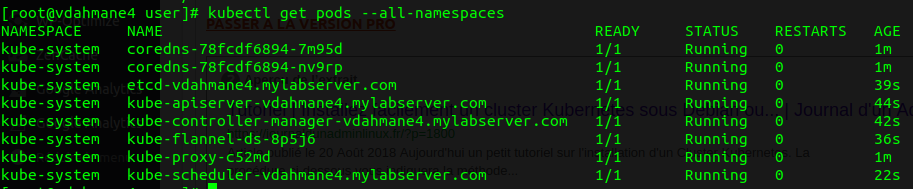
kubectl get pods --all-namespaces
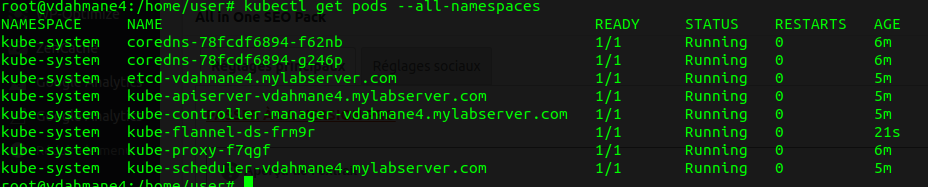
- Sur chaque worker lancez la commande "kubeadm join" que vous avez gardé dans un coin
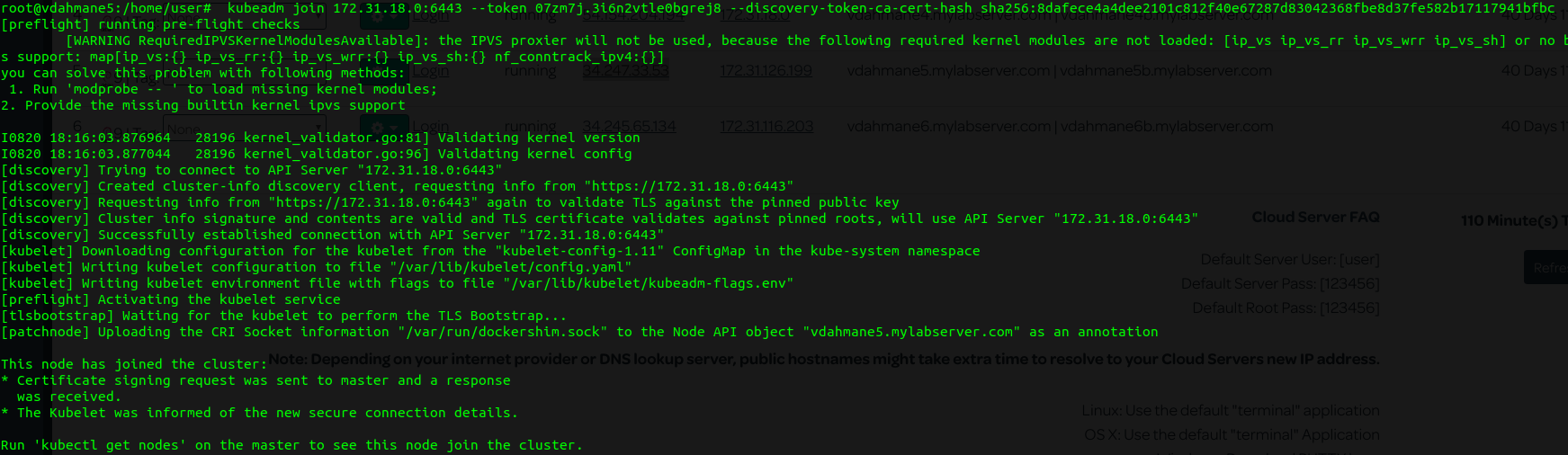
- Depuis le master lancez la commande suivante afin de vérifier que vos nodes ont bien rejoins le cluster
kubectl get nodes

2) Installation sous Centos/RedHat
- Appliquez les dernière mises à jour de l'OS (sur chaque nodes):
yum update -y
- Désactiver SeLinux durant l'installation (sur chaque nodes):
setenforce 0
- Installez Docker
yum install -y docker
- Activez le démarrage automatique de Docker (sur chaque nodes) :
systemctl enable docker
- Ajoutez le repository Kubernetes (sur chaque nodes):
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kube*
EOF
- Installez Kubernetes (sur chaque nodes):
yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
- Ajoutez les paramètres sysctl suivant (sur chaque nodes):
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
- Désactivez le swap (sur chaque nodes)
swapoff -a
N'oubliez pas de commenter la ligne dans le fstab
- Initialisez le cluster Kubernetes(sur le master uniquement) :
kubeadm init --pod-network-cidr=10.244.0.0/16
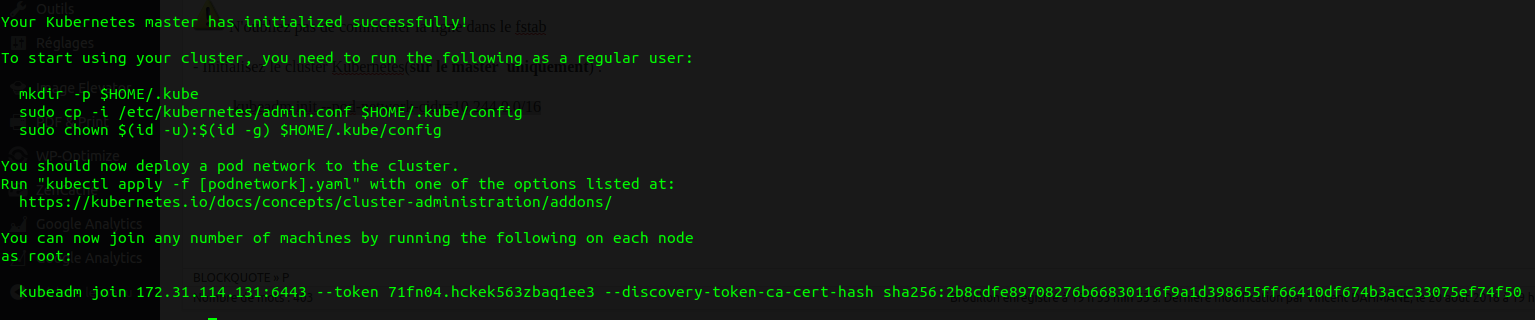
Faites ce qui est indiqué à l'écran et gardez dans un coin la commande "kubeadm join" qui nous permettra plus tard de rattacher des workers à notre Cluster.
- Installez les composants network Kubernetes (sur le master uniquement)
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.9.1/Documentation/kube-flannel.yml
- Vérifiez que l'installation se soit bien passé
kubectl get pods --all-namespaces
- Sur chaque worker lancez la commande "kubeadm join" que vous avez gardé dans un coin
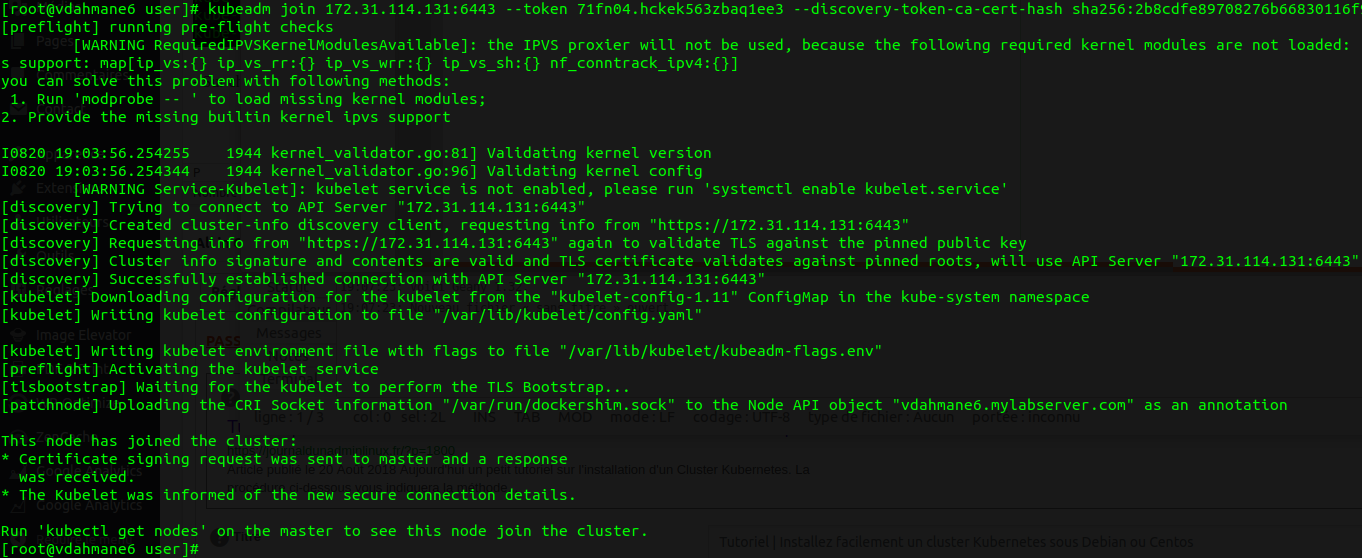
- Depuis le master lancez la commande suivante afin de vérifier que vos nodes ont bien rejoins le cluster
kubectl get nodes

Enjoy! 😉
Tutoriel | Installer et utiliser DockerSwarm
Article publié le 15 Août 2018
Docker Swarm est un outil conçu par Docker permettant de gérer un cluster de Container très facilement. En plus d'être simple à implémenter, Docker Swarm est extrêmement performant. Il peut supporter mille noeuds et cinquante mille container sans aucune dégradation de performance.
Ci-dessous un tutoriel complet sur comment installer et utiliser DockerSwarm.
1) Prérequis
Pour ce tutoriel, je vais utiliser 3 machines (la distribution importe peu)
Docker 1.13 ou supérieur doit-être installé sur chaque machine. Pour rappel, un tutoriel sur l'installation de Docker est disponible ici.
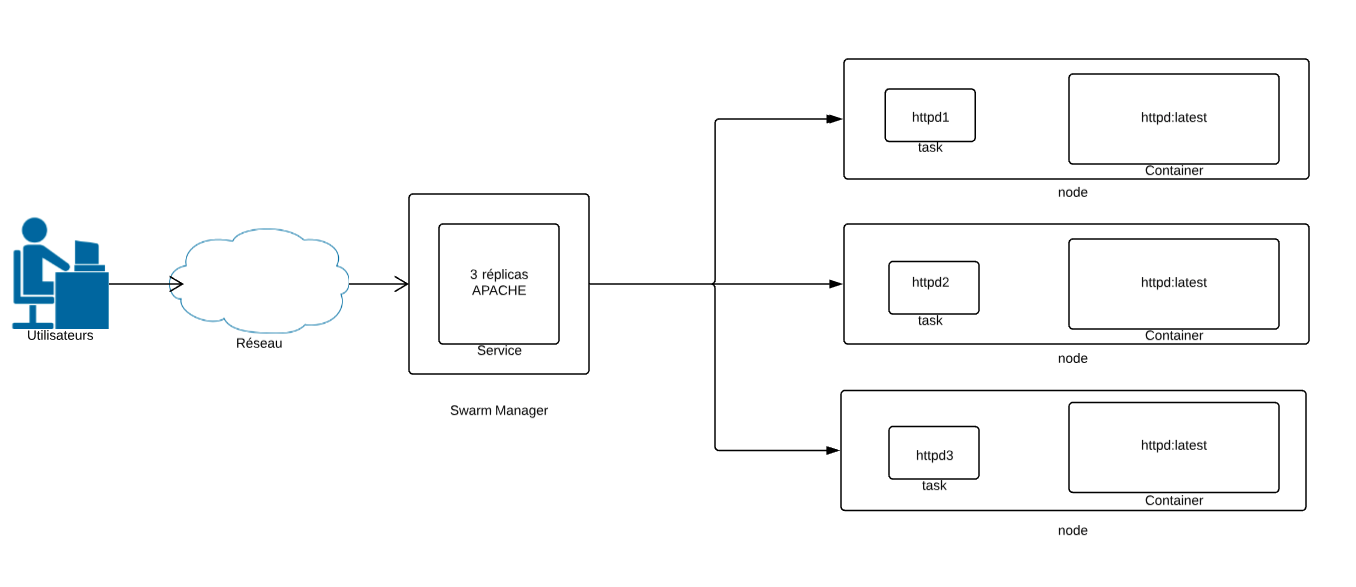
2) Schéma
Ci-dessous un petit schéma qui résume très simplement le concept de Swarm et de ce que l'on va mettre en place avec ce tuto:
3) Création du Cluster Swarm
Un cluster swarm est composé de Managers chargés de l'orchestration du cluster et des Workers qui exécutent vos containers.
- Initialisation du cluster Swarm (la machine ou le cluster swarm sera initialisé deviendra Manager):
docker swarm init --advertise-addr <ip du host>
La commande devrait vous renvoyer quelque chose comme ci-dessous:

- Suivez les instructions en faisant un copier-coller de la commande sur chaque node (host) qui servira de worker:
![]()
- Vous pouvez vérifier l'état de votre cluster Swarm grâce à cette commande (à exécuter depuis le manager):
docker node ls

4) Création d'un service
Avec swarm nous allons beaucoup parler de service. Un service est, pour ainsi dire, le point d'entré de votre application. Un service est composé de 1-N container et apporte une dimension de clustering, de fault tolérance et de haute disponibilité à votre environnement docker.
- Dans l'exemple ci-dessous, nous allons créer un service httpd (apache) nommé "monserveurweb":
docker service create --name monserveurweb --publish 80:80 httpd
- Vérifiez ensuite l'état de votre service:
docker service ls
Au final, vous devriez avoir un truc comme ceci:
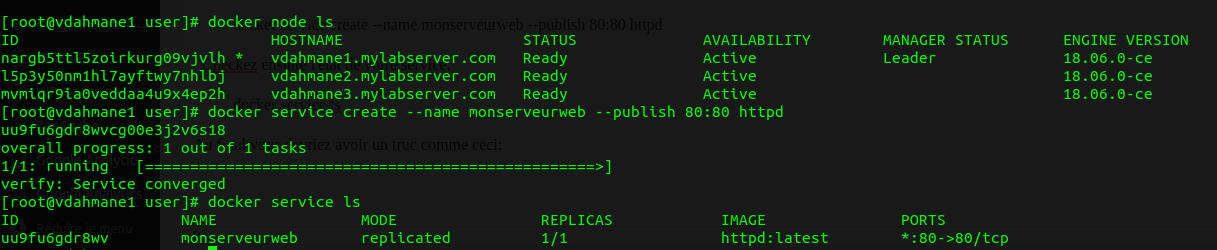
Vous pourrez constater que si vous tapez http://<ip de votre manager ou d'un node> depuis votre navigateur que le serveur apache hébergé dans le container répond bien!

4.2) Scalabilité
En faisant un docker service ls, vous pouvez voir que le nombre de replica est à 1. Cela signifie qu'un seul container a été provisionné et déployé dans votre cluster. Il est possible d'augmenter le nombre de replica via cette commande:
docker service update --replicas <nombre de replica> <nom de votre service>
ou
docker service scale <nom de votre service>=<nombre de replicas> (l'avantage avec cette commande est que vous pouvez modifier plusieurs service d'un seul coup)
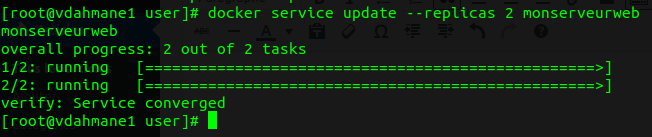
Si l'on refait un "docker service ls" on pourra voir que le nombre de replicas a augmenté:
![]()
Pour rappel, votre manager fera lui même le loadbalancing entre chacun de vos replicas.
Vous pouvez avoir une vue détaillé de l’endroit où sont hébergés chacun de vos replicas grâce à cette commande
docker service ps <id de votre service>
Exemple:
![]()
4.3) Ajouter un manager
Vous l'aurez compris, le manager est un élément critique de votre cluster Swarm. Il est très fortement conseillé d'en avoir plusieurs afin de limiter au maximum le risque d'incidents critiques.
Pour créer un nouveau manager (qui sera un manager en standby):
- Récupérez le token:
docker swarm join-token manager

- Copiez-collez la commande qui vous est indiquée sur le host qui vous servira de manager
![]()
- En faisant un "docker node ls" vous pouvez voir votre nouveau node avec le statut "reachable". Ce qui voudra dire qu'il prendra le relais en cas de perte du manager.

Attention toutefois: afin que l'algorithme raft fonctionne bien (ce qui permet l’élection d'un nouveau manager en cas de perte de celui-ci), il est préconisé que le nombre de manager désigné soit impair !
5) Autres fonctionnalités
Ci-dessous quelques fonctionnalités qui pourront vous être fort utile:
- Exemple de commande pour fixer des quota de ressources:
docker service update --limit-cpu=.5 --reserve-cpu=.75 --limit-memory=128m --reserve-memory=256 monserveurweb
- Les labels:
Cette fonctionnalité vous permettra de "tagger" vos nodes et vos services. Cela vous sera très utile; par exemple, si vous voulez que certains services se déploient sur certain nodes:
- Affecter un label à un node
docker node update --label-add nodelabel=<nom du label> <id de votre node>
- Créer un service qui sera déployé sur un node en fonction de son label:
docker service create --name <nom du service> --constraints 'node.labels.nodelabel=='<nom du label>' <nom de l'image>
- Supprimer un node:
- Sur votre node tapez la commande suivante:
docker swarm leave
- Depuis le manager tapez la commande suivante:
docker node rm <id de votre node>
- Swarm et docker-compose
- Il est possible de créer un service depuis un yaml docker-compose grâce à cette commande:
docker stack deploy --compose-file <fichiercompose.yml> <nom service>
Tutoriel | Installation, configuration et utilisation d’un Docker Registry
Article publié le 13 Août 2018
Ce tutoriel complet expliquera comment installer, configurer, et utiliser un Docker Registry.
Pour suivre ce tutoriel, Docker doit-être installé sur votre machine. Un tutoriel vous expliquant comment installer Docker est disponible ici.
Nous allons travailler dans le répertoire /srv/myrepo.com et pour servir d'exemple l'adresse de notre repository sera myrepo.com. Le fichier host sera renseigné de tel manière à ce que l'IP de ma machine soit associé au nom myrepo.com.
- Dans notre répertoire de travail, nous allons créer deux répertoires:
mkdir -p /srv/myrepo.com/certs
mkdir -p /srv/myrepo.com/auth
- Nous allons ensuite généré dans le répertoire /srv/myrepo.com/certs un certificat TLS:
cd /srv/myrepo.com/certs && openssl req -x509 -newkey rsa:4096 -nodes -keyout myrepo.com.key -out myrepo.com.crt -days 365 -subj /CN=myrepo.com
- En faisans un "ls" vous devriez voir la clé privée plus le certificat:

- Copiez ensuite le crt dans le répertoire /etc/docker/certs.d/myrepo.com (pour rappel myrepo.com correspond au nom de votre repo)
sudo mkdir -p /etc/docker/certs.d/myrepo.com:5000 && cp /srv/myrepo.com/certs/myrepo.com.crt /etc/docker/certs.d/myrepo.com\:5000/
- Faites un pull de l'image Docker registry:
docker pull registry:2
- Générez ensuite un fichier htpasswd contenant le login et le mot de passe qui permettra de vous authentifier:
docker run --entrypoint htpasswd registry:2 -Bbn votrelogin votrepassword > /srv/myrepo.com/auth/htpasswd
- Lancez le container Docker Registry:
docker run -d -p 5000:5000 -v /srv/myrepo.com/certs:/certs -e REGISTRY_HTTP_TLS_CERTIFICATE=/certs/myrepo.com.crt -e REGISTRY_HTTP_TLS_KEY=/certs/myrepo.com.key -v /srv/myrepo.com/auth:/auth -e REGISTRY_AUTH_HTPASSWD_REALM="Registry Realm" -e REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd registry:2
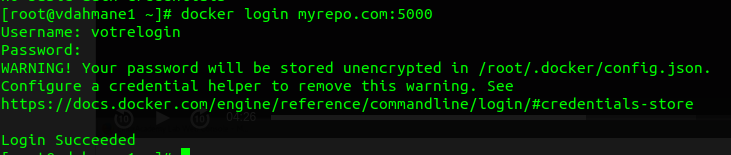
- Authentifiez-vous sur votre registry
docker login
Si l’authentification se déroule bien vous devriez avoir quelque chose comme ceci:
- Testez que votre repository fonctionne correctement.
- Pour cela, on va faire un pull d'une image (busybox):
docker pull busybox
- Taggez ensuite l'image pour la faire pointer vers votre registry
docker tag busybox myrepo.com:5000/testimage
- Pushez l'image vers votre registry
docker push busybox myrepo.com:5000/testimage
Dans ce tuto, le certificat utilisé est un certificat auto-signé. Si vous voulez utiliser votre registry depuis un autre serveur (ce qui, je pense, sera forcément le cas) il sera nécessaire de copier le répertoire /etc/docker/certs.d/myrepo.com\:5000/ sur chaque machine qui devra se connecter à votre registry et redémarrer le service Docker. Si vous ne faites pas cela, vous risquez d'avoir un vilain message d'erreur vous indiquant que votre certificat TLS n'est pas bon...
Lister les images de votre repository:
Pour lister et connaître le contenu de votre repository, utiliser la commande curl suivante:
curl --insecure -u "login password" <URL de votre repository>
--insecure à utiliser si vous utilisez un certificat auto-signé
vim: Impossible de copier coller dans Debian Stretch
Article publié le 17 Avril 2018
Certains l'auront remarqué, depuis debian 9 (stretch), il est par défaut impossible de faire un copier coller depuis un terminal en utilisant vim.
Afin de résoudre ce petit désagrément, il suffit d'éditer le fichier /usr/share/vim/vim80/defaults.vim et de modifier la ligne suivante:
if has ('mouse')
set mouse=a
endif
par:
if has ('mouse')
set mouse=r
endif
Monitorer en temps réél vos machine Linux avec Netdata
Article publié le 9 Avril 2018
Netdata est un outil de monitoring très puissant. Il vous permet d'avoir un dashboard complet et en temps réel de l'état de votre machine. L'interface graphique est très belle et très pratique.
1) Installation
Cette méthode d'installation est adaptée pour toutes les distributions récentes:
- Lancez la commande suivante:
bash <(curl -Ss https://my-netdata.io/kickstart.sh)
Le script va vérifier les prérequis et les installer pour vous:
Le script d'installation compilera et installera tous les modules nécessaires au fonctionnement de Netdata.
Une fois l'installation terminée, vous devriez avoir ceci:
2) Utilisation
Connectez vous à l'interface via l'adresse <ip ou dns de votre machine>:19999
Quelques screenshot pour vous montrer à quoi ressemble le dashboard de monitoring:
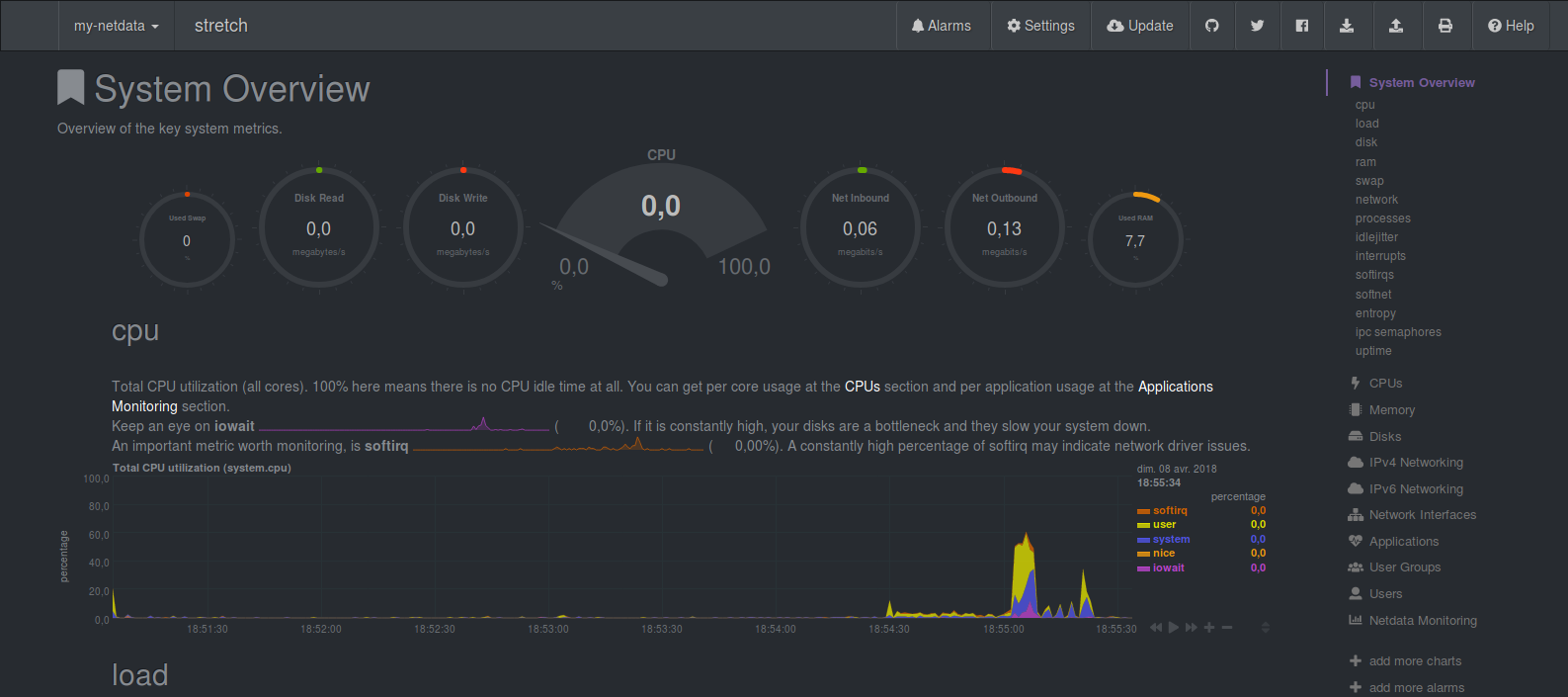
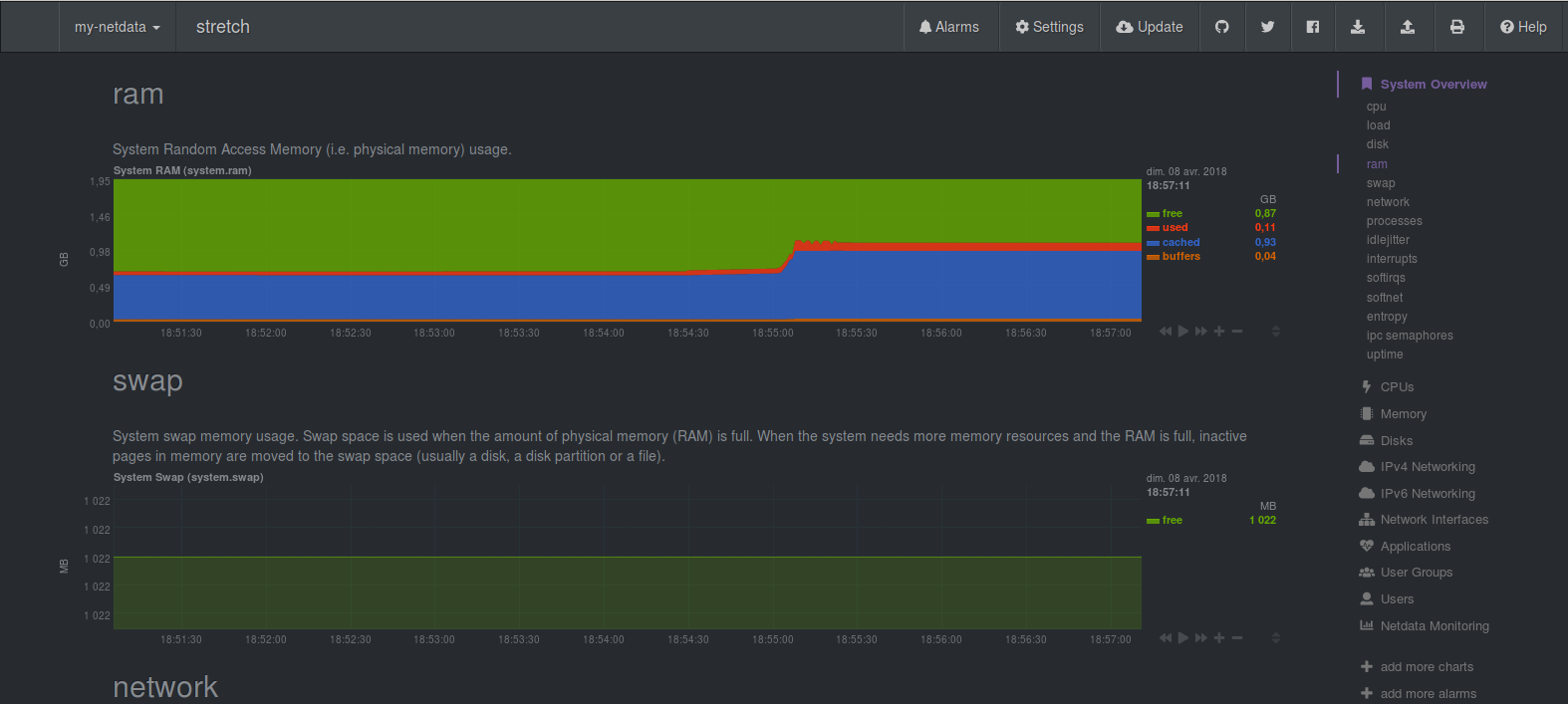
Enfin, Netdata est capable de faire le monitoring de la plupart des services installés sur votre machine (MySQL, Apache2, etc...):
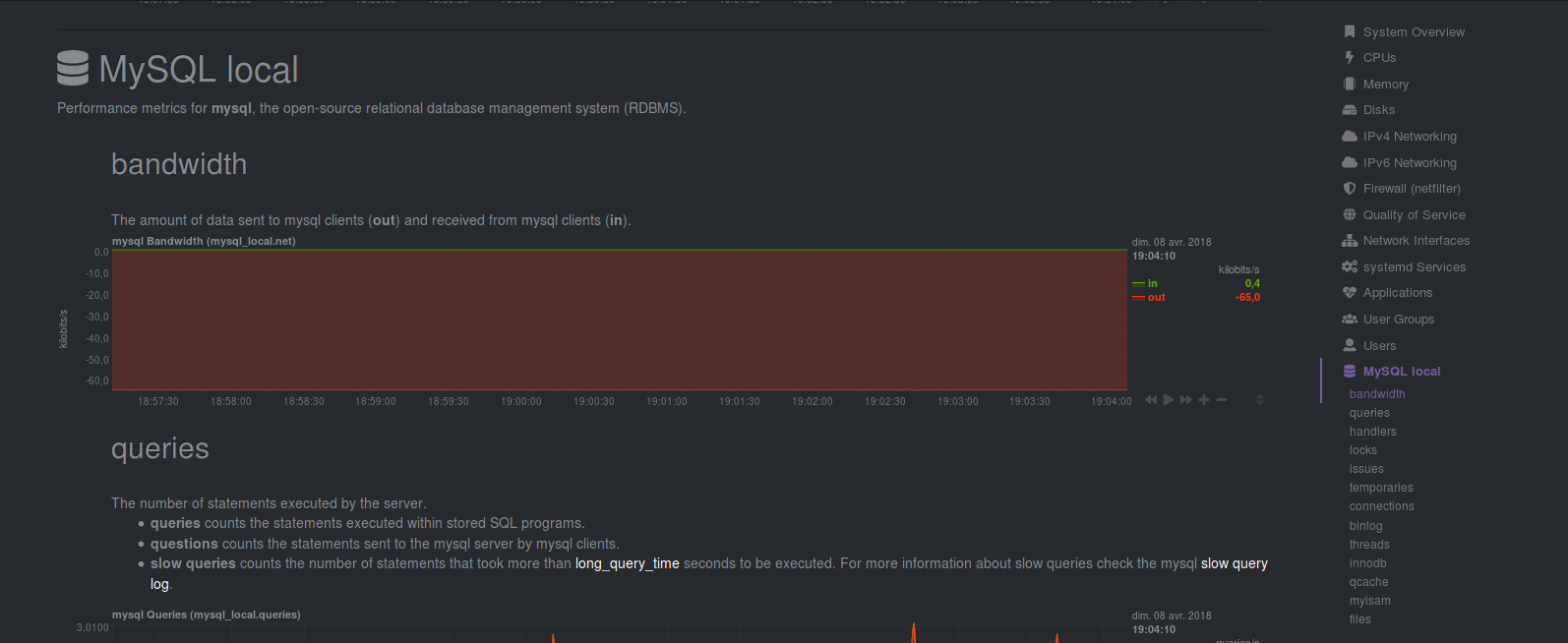
- Pour monitorer un service il vous suffit de paramétrer les fichiers de configuration situé dans le répertoire /etc/netdata/python.d:

Enjoy 😉
Analysez les logs de vos serveurs web en temps réel avec GoAccess
Article publiée le 6 Avril 2018
J'ai découvert par hasard un petit outil fort sympathique nommé GoAccess. GoAccess vous permet d'analyser en temps réel les logs de votre serveur Web (Apache, Nginx ou autre) et d'avoir des statistiques détaillées (via votre terminal ou export au format HTML, CSV).
1) Installation
Sous Debian/Ubuntu:
- Ajoutez les dépôts officiels GoAccess:
echo "deb http://deb.goaccess.io/ $(lsb_release -cs) main" | sudo tee -a /etc/apt/sources.list.d/goaccess.list
- Ajoutez la clé GPG:
wget -O - https://deb.goaccess.io/gnugpg.key | sudo apt-key add -
- Installez le package
sudo apt-get update && sudo apt-get install goaccess
Sous RedHat/Centos:
- Installez directement GOAcess depuis les dépots de la distribution
yum install goaccess
2) Utilisation
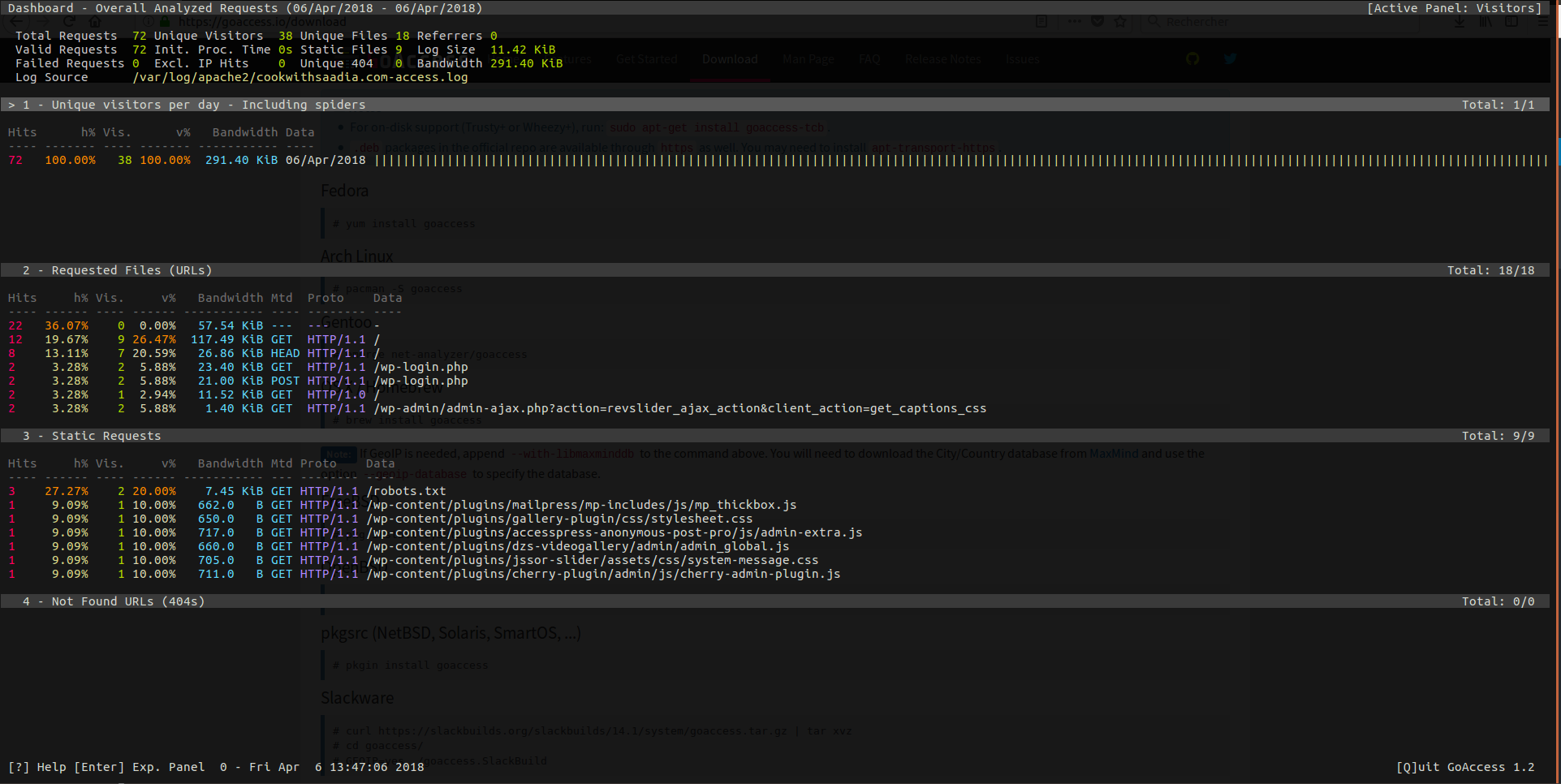
Pour générer un rapport:
goaccess -f <la log access de votre serveur web> #A adapter selon votre serveur Web
Exemple de rapport:
Vous pouvez également générer un rapport sous forme de page HTML
Éditez le fichier /etc/goaccess est décommentez les lignes "date-format" et "time-format" en fonction du serveur web dont vous voulez analyser les logs. Dans mon exemple, c'est un serveur apache:
- Lancez la commande suivante:
goaccess -f <la log access de votre serveur web> -a > /tmp/rapport.html #A adapter selon votre serveur Web
- Un rapport de ce type vous sera généré:
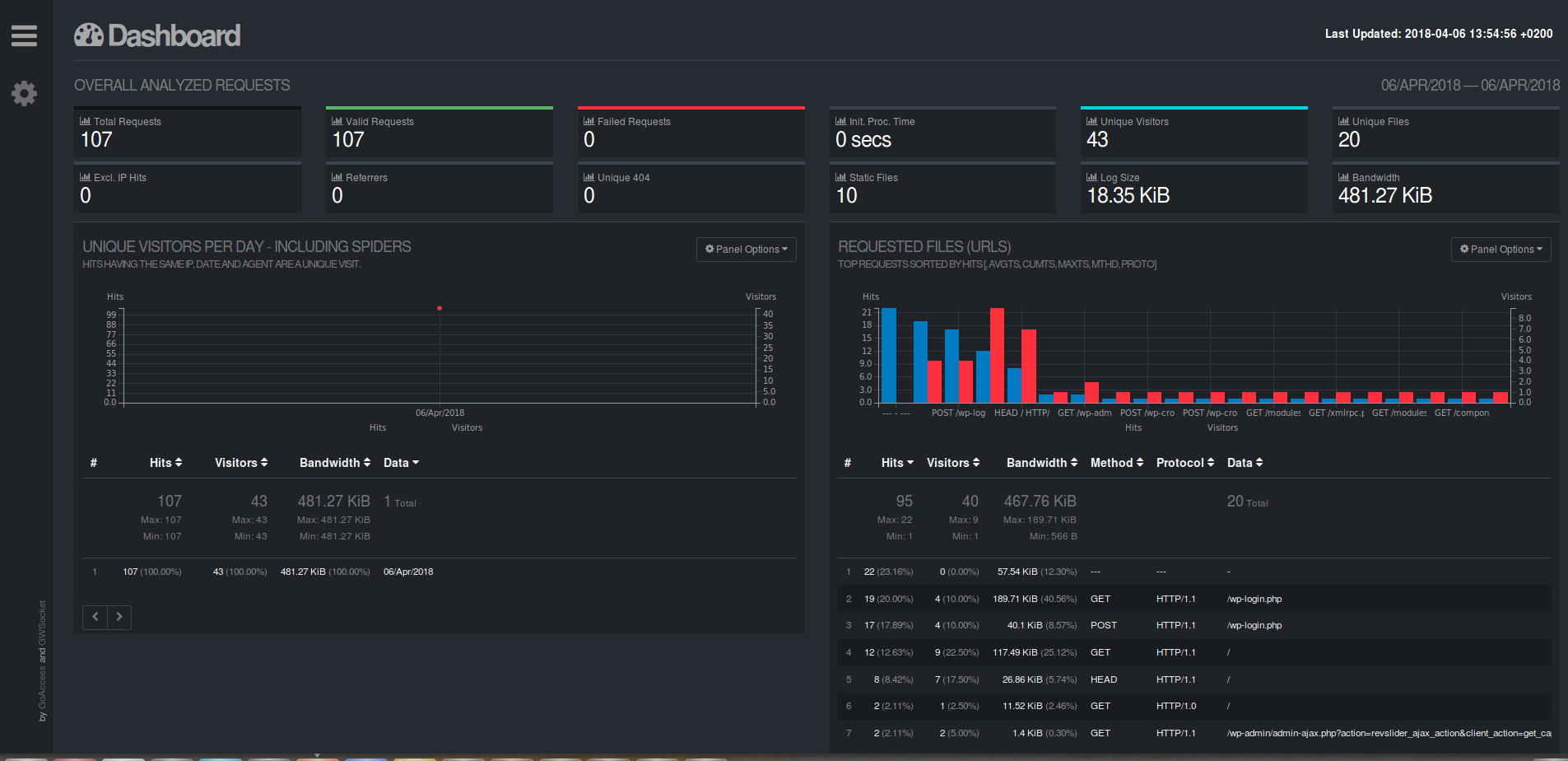
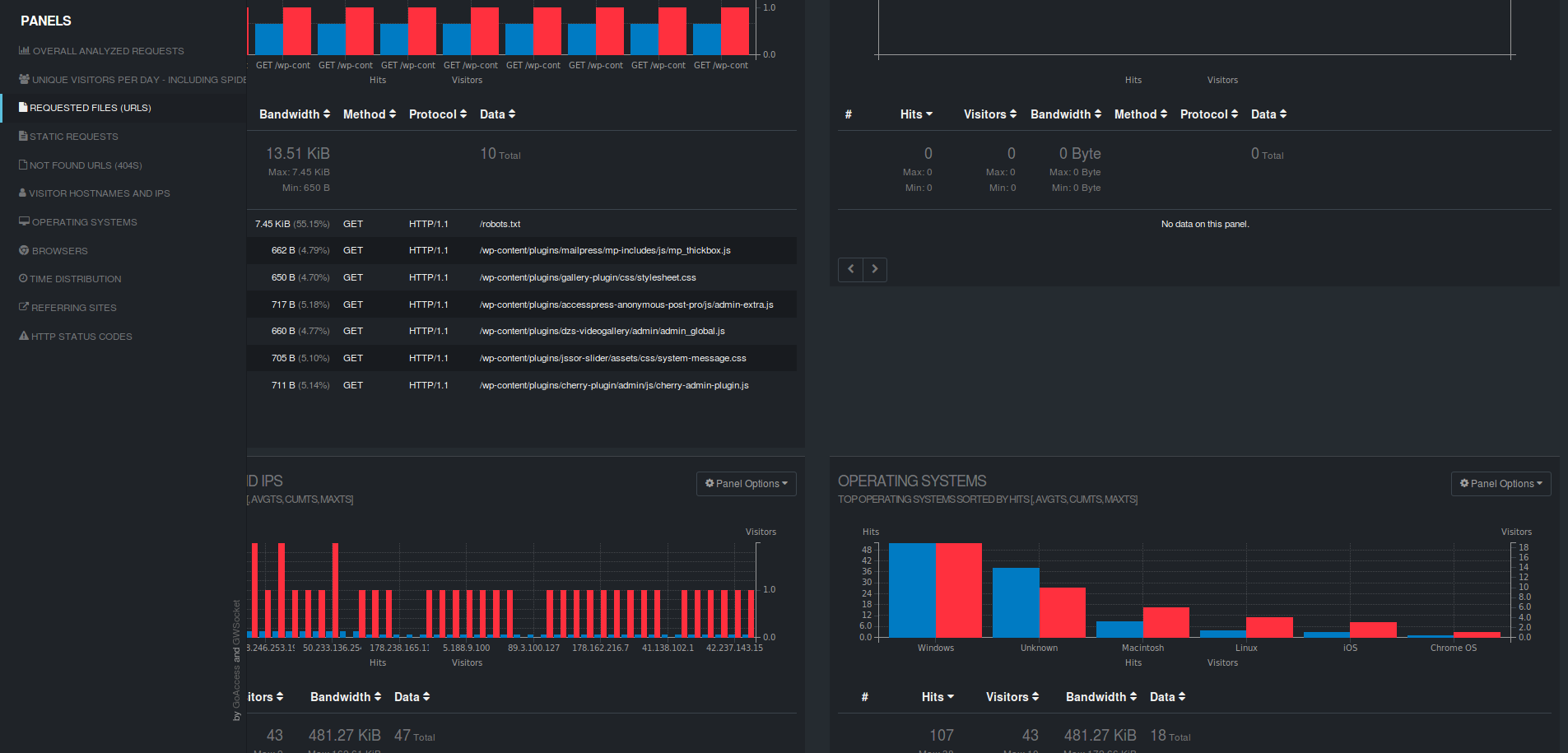
Si vous voulez des graphs en temps réel (ou presque), il vous suffira d'exécuter la commande de génération du rapport en format HTML via un CRON et de le publier via un serveur web.
Tutoriel | Installation d’un cluster ElasticSearch
Article publié le 28 Mars 2018
Un petit tutoriel qui pourra être utile à ceux qui, comme moi, ont souffert de la prise en main d'ElasticSearch ;-).
Ce tutoriel expliquera la marche à suivre pour monter un cluster ElasticSearch.
Dans l'exemple ci-dessous, je vais monter un cluster ElasticSearch composé de trois nœuds.
1) Installation
Installez ElasticSearch sur chaque machine (au moment où ce tutoriel a été rédigé, la version courante d'ElasticSearch est la 6.2)
Installation sous Debian:
Téléchargez et installez la clé GPG:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Ajoutez le répo elasticsearch (à adapter en fonction de la version courante du moment):
echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
Enfin, Installez ElasticSearch
sudo apt-get update && sudo apt-get install elasticsearch
Installation sous RedHat:
Téléchargez et installez la clé GPG:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Ajoutez le répo (à adapter en fonction de la version courante du moment):
[elasticsearch-6.x]
name=Elasticsearch repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
Enfin, installez ElasticSearch
sudo yum install elasticsearch
2) Configuration
Chaque machine doit être joignable via le hostname (enregistrement DNS ou fichier host impératif)
- Une fois les noeuds ElasticSearch installés, éditez le fichier /etc/elasticsearch/elasticsearch.yml et remplacez la conf par celle ci-dessous sur chaque nœuds de votre cluster elasticsearch:
cluster.name: moncluster
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch#A sécuriser si nécessaire
network.host: 0.0.0.0
http.port: 9200# Nombre de noeuds sans compter cette machine
discovery.zen.minimum_master_nodes: 2
discovery.zen.ping.unicast.hosts: [ "<nom dns du noeud 1>", "<nom dns du noeud 2>", "<nom dns du noeud 3>" ]# Nombre total de nœuds composant votre cluster
gateway.expected_nodes: 3
#Nombre de nœuds sans compter cette machine
gateway.recover_after_nodes: 2
node.name: <nom du noeud>action.destructive_requires_name: true
bootstrap.memory_lock: true
- Éditez le fichier de configuration systemd /usr/lib/systemd/system/elasticsearch.service et rajoutez à la fin de ce fichier la ligne suivante:
LimitMEMLOCK=infinity
- Éditez le fichier /etc/security/limits.conf et rajoutez à la fin du fichier les lignes suivantes:
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
elasticsearch - nofile 65536
elasticsearch - nproc 2048
- Désactivez le Swap
swapoff -a
- Les paramètres java sont configurable directement via le ficher de configuration /etc/elasticsearch/jvm.options (notamment les paramètres mémoires)
Une fois les nœuds paramétrés, redémarrez le service elasticsearch sur chacune de vos machines
service elasticsearch restart
3) Vérification du cluster
Avant toute chose, vous pouvez vérifier dans les logs elasticsearch si vos machines communiquent bien entre elles (/var/log/elasticsearch.log) et avoir quelque chose de similaire à la log ci-dessous:
[2018-03-28T13:17:54,213][INFO ][o.e.n.Node ] [els02] starting ...
[2018-03-28T13:17:54,379][INFO ][o.e.t.TransportService ] [els02] publish_address {192.168.2.91:9300}, bound_addresses {[::]:9300}
[2018-03-28T13:17:54,390][INFO ][o.e.b.BootstrapChecks ] [els02] bound or publishing to a non-loopback address, enforcing bootstrap checks
[2018-03-28T13:17:57,508][INFO ][o.e.c.s.MasterService ] [els02] zen-disco-elected-as-master ([1] nodes joined)[{els01}{swDhGGuVTfCeRVp79KFpzQ}{NZvRF3JyT72OyoshFARfMw}{192.168.2.29}{192.168.2.29:9300}], reason: new_master {els02}{h-Q4N-ytQ_6G8JWolSklMg}{axcVvf6BTqOfCPM4CPg3-g}{192.168.2.91}{192.168.2.91:9300}, added {{els01}{swDhGGuVTfCeRVp79KFpzQ}{NZvRF3JyT72OyoshFARfMw}{192.168.2.29}{192.168.2.29:9300},}
[2018-03-28T13:17:57,594][INFO ][o.e.c.s.ClusterApplierService] [els02] new_master {els02}{h-Q4N-ytQ_6G8JWolSklMg}{axcVvf6BTqOfCPM4CPg3-g}{192.168.2.91}{192.168.2.91:9300}, added {{els01}{swDhGGuVTfCeRVp79KFpzQ}{NZvRF3JyT72OyoshFARfMw}{192.168.2.29}{192.168.2.29:9300},}, reason: apply cluster state (from master [master {els02}{h-Q4N-ytQ_6G8JWolSklMg}{axcVvf6BTqOfCPM4CPg3-g}{192.168.2.91}{192.168.2.91:9300} committed version [1] source [zen-disco-elected-as-master ([1] nodes joined)[{els01}{swDhGGuVTfCeRVp79KFpzQ}{NZvRF3JyT72OyoshFARfMw}{192.168.2.29}{192.168.2.29:9300}]]])
[2018-03-28T13:17:57,601][INFO ][o.e.g.GatewayService ] [els02] delaying initial state recovery for [5m]. expecting [3] nodes, but only have [2]
[2018-03-28T13:17:57,632][INFO ][o.e.h.n.Netty4HttpServerTransport] [els02] publish_address {192.168.2.91:9200}, bound_addresses {[::]:9200}
[2018-03-28T13:17:57,632][INFO ][o.e.n.Node ] [els02] started
[2018-03-28T13:18:21,135][INFO ][o.e.c.s.MasterService ] [els02] zen-disco-node-join[{els03}{I9Kd4QJ1SZGuHPppMwdS0A}{NSdfQfdfRhCD4_YfhQ18vA}{192.168.2.76}{192.168.2.76:9300}], reason: added {{els03}{I9Kd4QJ1SZGuHPppMwdS0A}{NSdfQfdfRhCD4_YfhQ18vA}{192.168.2.76}{192.168.2.76:9300},}
[2018-03-28T13:18:21,279][INFO ][o.e.c.s.ClusterApplierService] [els02] added {{els03}{I9Kd4QJ1SZGuHPppMwdS0A}{NSdfQfdfRhCD4_YfhQ18vA}{192.168.2.76}{192.168.2.76:9300},}, reason: apply cluster state (from master [master {els02}{h-Q4N-ytQ_6G8JWolSklMg}{axcVvf6BTqOfCPM4CPg3-g}{192.168.2.91}{192.168.2.91:9300} committed version [2] source [zen-disco-node-join[{els03}{I9Kd4QJ1SZGuHPppMwdS0A}{NSdfQfdfRhCD4_YfhQ18vA}{192.168.2.76}{192.168.2.76:9300}]]])
[2018-03-28T13:18:21,372][INFO ][o.e.g.GatewayService ] [els02] recovered [0] indices into cluster_state
Enfin, il existe un plugin Chrome très utiles permettant d'avoir un statut en temps réel de votre cluster elasticsearch: ElasticSearch Head:
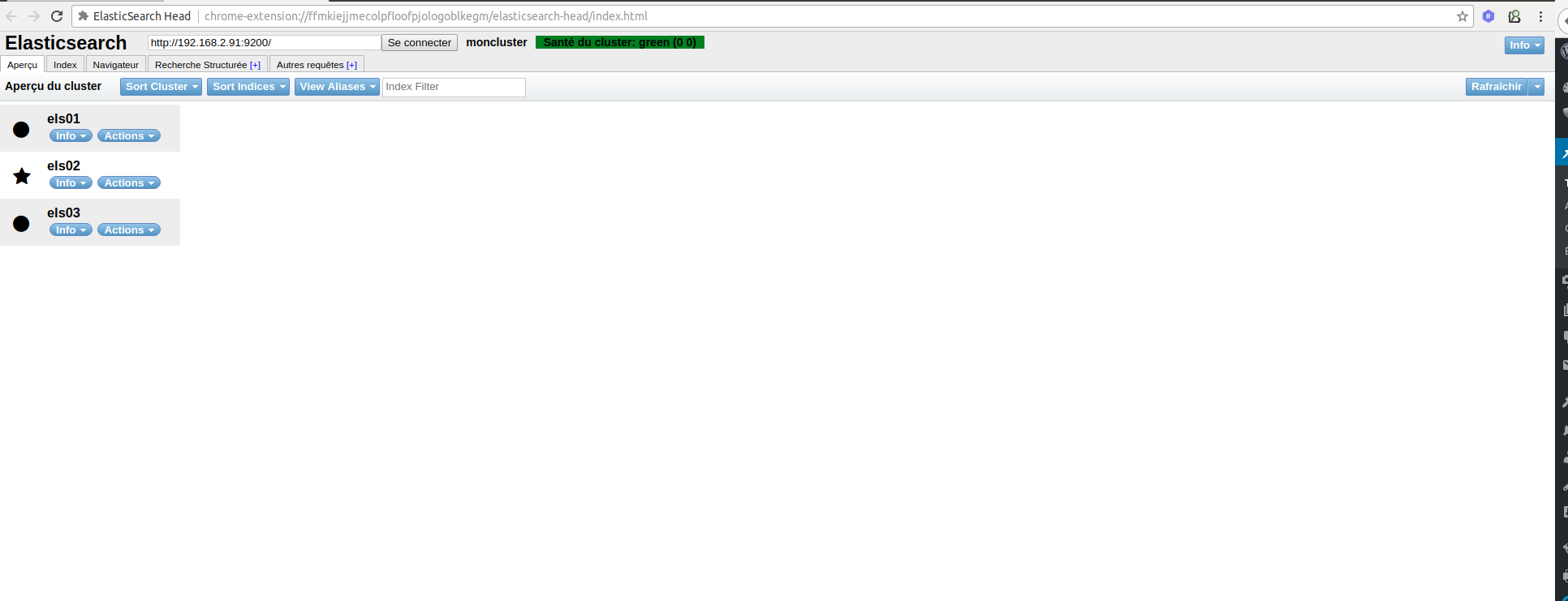
enjoy !
Faites un audit de votre système avec Lynis
Article publié le 19 Février 2018
Je suis tombé par hasard sur un petit outil fort sympathique nommé Lynis. Lynis vous permet de faire un audit complet de votre système Linux/Unix. J'ai été très impressionné par sa précision, Lynis va auditer jusqu'au moindre recoin de votre machine et vous faire un gros résumé de toutes les préconisations pour améliorer la sécurité et les performances de celle-ci. De plus Lynis détecte automatiquement les services installés et en fait l'audit (Apache2, Squid, etc).
1) Installation
Sous Debian/Ubuntu:
- Installez la clé:
sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys C80E383C3DE9F082E01391A0366C67DE91CA5D5F
- Ajoutez le repo:
echo "deb https://packages.cisofy.com/community/lynis/deb/ <votre distrib> main" | sudo tee /etc/apt/sources.list.d/cisofy-lynis.list
- Installez le paquet:
apt-get update && apt-get install lynis
Sous Centos/RedHat:
- Ajoutez le repo créez un fichier /etc/yum.repos.d/cisofy-lynis.repo:
[lynis]
name=CISOfy Software - Lynis package
baseurl=https://packages.cisofy.com/community/lynis/rpm/
enabled=1
gpgkey=https://packages.cisofy.com/keys/cisofy-software-rpms-public.key
gpgcheck=1
- Installez le package:
yum install lynis
2) Utilisation
Pour lancez un audit, il suffit de taper la commande suivante (avec le user roor ou en sudo):
lynis audit system
Pour l'exemple voici le résultat de l'audit d'une petite VM Vagrant:
ubuntu@ubuntu-xenial:~$ sudo lynis audit system
[ Lynis 2.6.2 ]
################################################################################
Lynis comes with ABSOLUTELY NO WARRANTY. This is free software, and you are
welcome to redistribute it under the terms of the GNU General Public License.
See the LICENSE file for details about using this software.2007-2018, CISOfy - https://cisofy.com/lynis/
Enterprise support available (compliance, plugins, interface and tools)
################################################################################[+] Initializing program
------------------------------------
- Detecting OS... [ DONE ]
- Checking profiles... [ DONE ]---------------------------------------------------
Program version: 2.6.2
Operating system: Linux
Operating system name: Ubuntu Linux
Operating system version: 16.04
Kernel version: 4.4.0
Hardware platform: x86_64
Hostname: ubuntu-xenial
---------------------------------------------------
Profiles: /etc/lynis/default.prf
Log file: /var/log/lynis.log
Report file: /var/log/lynis-report.dat
Report version: 1.0
Plugin directory: /usr/share/lynis/plugins
---------------------------------------------------
Auditor: [Not Specified]
Language: en
Test category: all
Test group: all
---------------------------------------------------
- Program update status... [ NO UPDATE ][+] System Tools
------------------------------------
- Scanning available tools...
- Checking system binaries...[+] Plugins (phase 1)
------------------------------------
Note: plugins have more extensive tests and may take several minutes to complete- Plugins enabled [ NONE ]
[+] Boot and services
------------------------------------
- Service Manager [ systemd ]
- Checking UEFI boot [ DISABLED ]
- Checking presence GRUB [ OK ]
- Checking presence GRUB2 [ FOUND ]
- Checking for password protection [ WARNING ]
- Check running services (systemctl) [ DONE ]
Result: found 22 running services
- Check enabled services at boot (systemctl) [ DONE ]
Result: found 32 enabled services
- Check startup files (permissions) [ OK ][+] Kernel
------------------------------------
- Checking default run level [ RUNLEVEL 5 ]
- Checking CPU support (NX/PAE)
CPU support: PAE and/or NoeXecute supported [ FOUND ]
- Checking kernel version and release [ DONE ]
- Checking kernel type [ DONE ]
- Checking loaded kernel modules [ DONE ]
Found 56 active modules
- Checking Linux kernel configuration file [ FOUND ]
- Checking default I/O kernel scheduler [ FOUND ]
- Checking for available kernel update [ OK ]
- Checking core dumps configuration [ DISABLED ]
- Checking setuid core dumps configuration [ PROTECTED ]
- Check if reboot is needed [ YES ][+] Memory and Processes
------------------------------------
- Checking /proc/meminfo [ FOUND ]
- Searching for dead/zombie processes [ OK ]
- Searching for IO waiting processes [ OK ][+] Users, Groups and Authentication
------------------------------------
- Administrator accounts [ OK ]
- Unique UIDs [ OK ]
- Consistency of group files (grpck) [ OK ]
- Unique group IDs [ OK ]
- Unique group names [ OK ]
- Password file consistency [ OK ]
- Query system users (non daemons) [ DONE ]
- NIS+ authentication support [ NOT ENABLED ]
- NIS authentication support [ NOT ENABLED ]
- sudoers file [ FOUND ]
- Check sudoers file permissions [ OK ]
- PAM password strength tools [ SUGGESTION ]
- PAM configuration files (pam.conf) [ FOUND ]
- PAM configuration files (pam.d) [ FOUND ]
- PAM modules [ FOUND ]
- LDAP module in PAM [ NOT FOUND ]
- Accounts without expire date [ OK ]
- Accounts without password [ OK ]
- Checking user password aging (minimum) [ DISABLED ]
- User password aging (maximum) [ DISABLED ]
- Checking expired passwords [ OK ]
- Checking Linux single user mode authentication [ OK ]
- Determining default umask
- umask (/etc/profile) [ NOT FOUND ]
- umask (/etc/login.defs) [ SUGGESTION ]
- umask (/etc/init.d/rc) [ SUGGESTION ]
- LDAP authentication support [ NOT ENABLED ]
- Logging failed login attempts [ ENABLED ][+] Shells
------------------------------------
- Checking shells from /etc/shells
Result: found 6 shells (valid shells: 6).
- Session timeout settings/tools [ NONE ]
- Checking default umask values
- Checking default umask in /etc/bash.bashrc [ NONE ]
- Checking default umask in /etc/profile [ NONE ][+] File systems
------------------------------------
- Checking mount points
- Checking /home mount point [ SUGGESTION ]
- Checking /tmp mount point [ SUGGESTION ]
- Checking /var mount point [ SUGGESTION ]
- Query swap partitions (fstab) [ NONE ]
- Testing swap partitions [ OK ]
- Testing /proc mount (hidepid) [ SUGGESTION ]
- Checking for old files in /tmp [ OK ]
- Checking /tmp sticky bit [ OK ]
- Checking /var/tmp sticky bit [ OK ]
- ACL support root file system [ ENABLED ]
- Mount options of / [ OK ]
- Checking Locate database [ FOUND ]
- Disable kernel support of some filesystems
- Discovered kernel modules: udf[+] USB Devices
------------------------------------
- Checking usb-storage driver (modprobe config) [ NOT DISABLED ]
- Checking USB devices authorization [ DISABLED ]
- Checking USBGuard [ NOT FOUND ][+] Storage
------------------------------------
- Checking firewire ohci driver (modprobe config) [ DISABLED ][+] NFS
------------------------------------
- Check running NFS daemon [ NOT FOUND ][+] Name services
------------------------------------
- Checking search domains [ FOUND ]
- Searching DNS domain name [ UNKNOWN ]
- Checking /etc/hosts
- Checking /etc/hosts (duplicates) [ OK ]
- Checking /etc/hosts (hostname) [ OK ]
- Checking /etc/hosts (localhost) [ OK ]
- Checking /etc/hosts (localhost to IP) [ OK ][+] Ports and packages
------------------------------------
- Searching package managers
- Searching dpkg package manager [ FOUND ]
- Querying package manager
- Query unpurged packages [ NONE ]
- Checking security repository in sources.list file [ OK ]
- Checking APT package database [ OK ]
- Checking vulnerable packages [ WARNING ]
- Checking upgradeable packages [ SKIPPED ]
- Checking package audit tool [ INSTALLED ]
Found: apt-check[+] Networking
------------------------------------
- Checking IPv6 configuration [ ENABLED ]
Configuration method [ AUTO ]
IPv6 only [ NO ]
- Checking configured nameservers
- Testing nameservers
Nameserver: 10.0.2.3 [ OK ]
- Minimal of 2 responsive nameservers [ WARNING ]
- Checking default gateway [ DONE ]
- Getting listening ports (TCP/UDP) [ DONE ]
* Found 3 ports
- Checking promiscuous interfaces [ OK ]
- Checking waiting connections [ OK ]
- Checking status DHCP client [ RUNNING ]
- Checking for ARP monitoring software [ NOT FOUND ][+] Printers and Spools
------------------------------------
- Checking cups daemon [ NOT FOUND ]
- Checking lp daemon [ NOT RUNNING ][+] Software: e-mail and messaging
------------------------------------[+] Software: firewalls
------------------------------------
- Checking iptables kernel module [ NOT FOUND ]
- Checking host based firewall [ NOT ACTIVE ][+] Software: webserver
------------------------------------
- Checking Apache [ NOT FOUND ]
- Checking nginx [ NOT FOUND ][+] SSH Support
------------------------------------
- Checking running SSH daemon [ FOUND ]
- Searching SSH configuration [ FOUND ]
- SSH option: AllowTcpForwarding [ SUGGESTION ]
- SSH option: ClientAliveCountMax [ SUGGESTION ]
- SSH option: ClientAliveInterval [ OK ]
- SSH option: Compression [ SUGGESTION ]
- SSH option: FingerprintHash [ OK ]
- SSH option: GatewayPorts [ OK ]
- SSH option: IgnoreRhosts [ OK ]
- SSH option: LoginGraceTime [ OK ]
- SSH option: LogLevel [ SUGGESTION ]
- SSH option: MaxAuthTries [ SUGGESTION ]
- SSH option: MaxSessions [ SUGGESTION ]
- SSH option: PermitRootLogin [ SUGGESTION ]
- SSH option: PermitUserEnvironment [ OK ]
- SSH option: PermitTunnel [ OK ]
- SSH option: Port [ SUGGESTION ]
- SSH option: PrintLastLog [ OK ]
- SSH option: Protocol [ OK ]
- SSH option: StrictModes [ OK ]
- SSH option: TCPKeepAlive [ SUGGESTION ]
- SSH option: UseDNS [ OK ]
- SSH option: UsePrivilegeSeparation [ SUGGESTION ]
- SSH option: VerifyReverseMapping [ NOT FOUND ]
- SSH option: X11Forwarding [ SUGGESTION ]
- SSH option: AllowAgentForwarding [ SUGGESTION ]
- SSH option: AllowUsers [ NOT FOUND ]
- SSH option: AllowGroups [ NOT FOUND ][+] SNMP Support
------------------------------------
- Checking running SNMP daemon [ NOT FOUND ][+] Databases
------------------------------------
No database engines found[+] LDAP Services
------------------------------------
- Checking OpenLDAP instance [ NOT FOUND ][+] PHP
------------------------------------
- Checking PHP [ NOT FOUND ][+] Squid Support
------------------------------------
- Checking running Squid daemon [ NOT FOUND ][+] Logging and files
------------------------------------
- Checking for a running log daemon [ OK ]
- Checking Syslog-NG status [ NOT FOUND ]
- Checking systemd journal status [ FOUND ]
- Checking Metalog status [ NOT FOUND ]
- Checking RSyslog status [ FOUND ]
- Checking RFC 3195 daemon status [ NOT FOUND ]
- Checking minilogd instances [ NOT FOUND ]
- Checking logrotate presence [ OK ]
- Checking log directories (static list) [ DONE ]
- Checking open log files [ DONE ]
- Checking deleted files in use [ FILES FOUND ][+] Insecure services
------------------------------------
- Checking inetd status [ NOT ACTIVE ][+] Banners and identification
------------------------------------
- /etc/issue [ FOUND ]
- /etc/issue contents [ WEAK ]
- /etc/issue.net [ FOUND ]
- /etc/issue.net contents [ WEAK ][+] Scheduled tasks
------------------------------------
- Checking crontab/cronjob [ DONE ]
- Checking atd status [ RUNNING ]
- Checking at users [ DONE ]
- Checking at jobs [ NONE ][+] Accounting
------------------------------------
- Checking accounting information [ NOT FOUND ]
- Checking sysstat accounting data [ NOT FOUND ]
- Checking auditd [ NOT FOUND ][+] Time and Synchronization
------------------------------------[+] Cryptography
------------------------------------
- Checking for expired SSL certificates [0/1] [ NONE ][+] Virtualization
------------------------------------[+] Containers
------------------------------------[+] Security frameworks
------------------------------------
- Checking presence AppArmor [ FOUND ]
- Checking AppArmor status [ ENABLED ]
- Checking presence SELinux [ NOT FOUND ]
- Checking presence grsecurity [ NOT FOUND ]
- Checking for implemented MAC framework [ OK ][+] Software: file integrity
------------------------------------
- Checking file integrity tools
- Checking presence integrity tool [ NOT FOUND ][+] Software: System tooling
------------------------------------
- Checking automation tooling
- Automation tooling [ NOT FOUND ]
- Checking for IDS/IPS tooling [ NONE ][+] Software: Malware
------------------------------------[+] File Permissions
------------------------------------
- Starting file permissions check
/root/.ssh [ OK ][+] Home directories
------------------------------------
- Checking shell history files [ OK ][+] Kernel Hardening
------------------------------------
- Comparing sysctl key pairs with scan profile
- fs.protected_hardlinks (exp: 1) [ OK ]
- fs.protected_symlinks (exp: 1) [ OK ]
- fs.suid_dumpable (exp: 0) [ DIFFERENT ]
- kernel.core_uses_pid (exp: 1) [ DIFFERENT ]
- kernel.ctrl-alt-del (exp: 0) [ OK ]
- kernel.dmesg_restrict (exp: 1) [ DIFFERENT ]
- kernel.kptr_restrict (exp: 2) [ DIFFERENT ]
- kernel.randomize_va_space (exp: 2) [ OK ]
- kernel.sysrq (exp: 0) [ DIFFERENT ]
- kernel.yama.ptrace_scope (exp: 1 2 3) [ OK ]
- net.ipv4.conf.all.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.all.accept_source_route (exp: 0) [ OK ]
- net.ipv4.conf.all.bootp_relay (exp: 0) [ OK ]
- net.ipv4.conf.all.forwarding (exp: 0) [ OK ]
- net.ipv4.conf.all.log_martians (exp: 1) [ DIFFERENT ]
- net.ipv4.conf.all.mc_forwarding (exp: 0) [ OK ]
- net.ipv4.conf.all.proxy_arp (exp: 0) [ OK ]
- net.ipv4.conf.all.rp_filter (exp: 1) [ OK ]
- net.ipv4.conf.all.send_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.default.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.default.accept_source_route (exp: 0) [ DIFFERENT ]
- net.ipv4.conf.default.log_martians (exp: 1) [ DIFFERENT ]
- net.ipv4.icmp_echo_ignore_broadcasts (exp: 1) [ OK ]
- net.ipv4.icmp_ignore_bogus_error_responses (exp: 1) [ OK ]
- net.ipv4.tcp_syncookies (exp: 1) [ OK ]
- net.ipv4.tcp_timestamps (exp: 0 1) [ OK ]
- net.ipv6.conf.all.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv6.conf.all.accept_source_route (exp: 0) [ OK ]
- net.ipv6.conf.default.accept_redirects (exp: 0) [ DIFFERENT ]
- net.ipv6.conf.default.accept_source_route (exp: 0) [ OK ][+] Hardening
------------------------------------
- Installed compiler(s) [ NOT FOUND ]
- Installed malware scanner [ NOT FOUND ][+] Custom Tests
------------------------------------
- Running custom tests... [ NONE ][+] Plugins (phase 2)
------------------------------------================================================================================
-[ Lynis 2.6.2 Results ]-
Warnings (3):
----------------------------
! Reboot of system is most likely needed [KRNL-5830]
- Solution : reboot
https://cisofy.com/controls/KRNL-5830/! Found one or more vulnerable packages. [PKGS-7392]
https://cisofy.com/controls/PKGS-7392/! Couldn't find 2 responsive nameservers [NETW-2705]
https://cisofy.com/controls/NETW-2705/Suggestions (39):
----------------------------
* Set a password on GRUB bootloader to prevent altering boot configuration (e.g. boot in single user mode without password) [BOOT-5122]
https://cisofy.com/controls/BOOT-5122/* Install a PAM module for password strength testing like pam_cracklib or pam_passwdqc [AUTH-9262]
https://cisofy.com/controls/AUTH-9262/* Configure minimum password age in /etc/login.defs [AUTH-9286]
https://cisofy.com/controls/AUTH-9286/* Configure maximum password age in /etc/login.defs [AUTH-9286]
https://cisofy.com/controls/AUTH-9286/* Default umask in /etc/login.defs could be more strict like 027 [AUTH-9328]
https://cisofy.com/controls/AUTH-9328/* Default umask in /etc/init.d/rc could be more strict like 027 [AUTH-9328]
https://cisofy.com/controls/AUTH-9328/* To decrease the impact of a full /home file system, place /home on a separated partition [FILE-6310]
https://cisofy.com/controls/FILE-6310/* To decrease the impact of a full /tmp file system, place /tmp on a separated partition [FILE-6310]
https://cisofy.com/controls/FILE-6310/* To decrease the impact of a full /var file system, place /var on a separated partition [FILE-6310]
https://cisofy.com/controls/FILE-6310/* Disable drivers like USB storage when not used, to prevent unauthorized storage or data theft [STRG-1840]
https://cisofy.com/controls/STRG-1840/* Check DNS configuration for the dns domain name [NAME-4028]
https://cisofy.com/controls/NAME-4028/* Install debsums utility for the verification of packages with known good database. [PKGS-7370]
https://cisofy.com/controls/PKGS-7370/* Update your system with apt-get update, apt-get upgrade, apt-get dist-upgrade and/or unattended-upgrades [PKGS-7392]
https://cisofy.com/controls/PKGS-7392/* Install package apt-show-versions for patch management purposes [PKGS-7394]
https://cisofy.com/controls/PKGS-7394/* Check your resolv.conf file and fill in a backup nameserver if possible [NETW-2705]
https://cisofy.com/controls/NETW-2705/* Consider running ARP monitoring software (arpwatch,arpon) [NETW-3032]
https://cisofy.com/controls/NETW-3032/* Configure a firewall/packet filter to filter incoming and outgoing traffic [FIRE-4590]
https://cisofy.com/controls/FIRE-4590/* Consider hardening SSH configuration [SSH-7408]
- Details : AllowTcpForwarding (YES --> NO)
https://cisofy.com/controls/SSH-7408/* Consider hardening SSH configuration [SSH-7408]
- Details : ClientAliveCountMax (3 --> 2)
https://cisofy.com/controls/SSH-7408/* Consider hardening SSH configuration [SSH-7408]
- Details : Compression (YES --> (DELAYED|NO))
https://cisofy.com/controls/SSH-7408/* Consider hardening SSH configuration [SSH-7408]
- Details : LogLevel (INFO --> VERBOSE)
https://cisofy.com/controls/SSH-7408/* Consider hardening SSH configuration [SSH-7408]
- Details : MaxAuthTries (6 --> 2)
https://cisofy.com/controls/SSH-7408/* Consider hardening SSH configuration [SSH-7408]
- Details : MaxSessions (10 --> 2)
https://cisofy.com/controls/SSH-7408/* Consider hardening SSH configuration [SSH-7408]
- Details : PermitRootLogin (WITHOUT-PASSWORD --> NO)
https://cisofy.com/controls/SSH-7408/* Consider hardening SSH configuration [SSH-7408]
- Details : Port (22 --> )
https://cisofy.com/controls/SSH-7408/* Consider hardening SSH configuration [SSH-7408]
- Details : TCPKeepAlive (YES --> NO)
https://cisofy.com/controls/SSH-7408/* Consider hardening SSH configuration [SSH-7408]
- Details : UsePrivilegeSeparation (YES --> SANDBOX)
https://cisofy.com/controls/SSH-7408/* Consider hardening SSH configuration [SSH-7408]
- Details : X11Forwarding (YES --> NO)
https://cisofy.com/controls/SSH-7408/* Consider hardening SSH configuration [SSH-7408]
- Details : AllowAgentForwarding (YES --> NO)
https://cisofy.com/controls/SSH-7408/* Check what deleted files are still in use and why. [LOGG-2190]
https://cisofy.com/controls/LOGG-2190/* Add a legal banner to /etc/issue, to warn unauthorized users [BANN-7126]
https://cisofy.com/controls/BANN-7126/* Add legal banner to /etc/issue.net, to warn unauthorized users [BANN-7130]
https://cisofy.com/controls/BANN-7130/* Enable process accounting [ACCT-9622]
https://cisofy.com/controls/ACCT-9622/* Enable sysstat to collect accounting (no results) [ACCT-9626]
https://cisofy.com/controls/ACCT-9626/* Enable auditd to collect audit information [ACCT-9628]
https://cisofy.com/controls/ACCT-9628/* Install a file integrity tool to monitor changes to critical and sensitive files [FINT-4350]
https://cisofy.com/controls/FINT-4350/* Determine if automation tools are present for system management [TOOL-5002]
https://cisofy.com/controls/TOOL-5002/* One or more sysctl values differ from the scan profile and could be tweaked [KRNL-6000]
- Solution : Change sysctl value or disable test (skip-test=KRNL-6000:<sysctl-key>)
https://cisofy.com/controls/KRNL-6000/* Harden the system by installing at least one malware scanner, to perform periodic file system scans [HRDN-7230]
- Solution : Install a tool like rkhunter, chkrootkit, OSSEC
https://cisofy.com/controls/HRDN-7230/Follow-up:
----------------------------
- Show details of a test (lynis show details TEST-ID)
- Check the logfile for all details (less /var/log/lynis.log)
- Read security controls texts (https://cisofy.com)
- Use --upload to upload data to central system (Lynis Enterprise users)================================================================================
Lynis security scan details:
Hardening index : 56 [########### ]
Tests performed : 206
Plugins enabled : 0Components:
- Firewall [X]
- Malware scanner [X]Lynis Modules:
- Compliance Status [?]
- Security Audit [V]
- Vulnerability Scan [V]Files:
- Test and debug information : /var/log/lynis.log
- Report data : /var/log/lynis-report.dat================================================================================
Lynis 2.6.2
Auditing, system hardening, and compliance for UNIX-based systems
(Linux, macOS, BSD, and others)2007-2018, CISOfy - https://cisofy.com/lynis/
Enterprise support available (compliance, plugins, interface and tools)================================================================================
[TIP]: Enhance Lynis audits by adding your settings to custom.prf (see /etc/lynis/default.prf for all settings)
Pour plus d'information n'hésitez pas à visiter la page officielle du projet:
Migrer vos fichier docker compose vers kubernetes avec Kompose
Article publié le 24 Janvier 2018
Mini article rapide pour vous parler de Kompose, un outil fort bien pratique pour convertir vos fichiers docker-compose.yml en yaml Kubernetes. Ceci est fortement appréciable notamment pour ceux qui débutent avec l'écosystème Kubernetes.
Installation
Lancez la commande suivante (n'oubliez pas de checker le numéro de version dans le lien qui peut évoluer dans le temps depuis l'écriture de cet article):
curl -L https://github.com/kubernetes/kompose/releases/download/v1.7.0/kompose-linux-amd64 -o kompose && mv kompose /usr/local/bin && chmod 755 /usr/local/bin/kompose
Utilisation
Dans l'exemple ci-dessous, je vais convertir le docker-compose de jenkins.
Contenu du docker-compose.yml:
version: "2"
volumes:
data-jenkins:
driver: "local"
services:
jenkins:
image: "jenkins:2.60.3"
ports:
- "8080:8080"
restart: "always"
volumes:
- "/srv/jenkins:/var/jenkins"
Convertissez votre fichier docker-compose avec la commande suivante:
kompose convert -f docker-compose.yml
Dans mon exemple cela donne ceci:

Kompose a créé les fichiers Kubernetes.
Nous allons ensuite tester les fichiers yaml généré en créant un pod Kubernetes avec le service associé:

Nous allons vérifier que tout est déployé correctement:
![]()

enjoy 😉
Script | Purger les logs d’exécution Rundeck
Article publié le 16 Janvier 2018
Avec le temps, les performances de Rundeck peuvent fortement diminuer suite à l'accumulation de logs d’exécution stockée en base et générant en parallèle d'innombrables petits fichiers.
Il vous faudra donc mettre rapidement en place une solution afin de purger les logs d’exécution de Rundeck.
J'ai trouvé et modifié un petit script faisant très bien le boulot (utilisable si votre Rundeck utilise MySQL):
#!/bin/bash
#Nombre de jours de rétention des logs
KEEP=90
# A modifier si votre instance MySQL est hébergé sur une autre machine
HOST=localhost
PORT=3306
USERNAME=<user de votre base de donnée MySQL>
PASSWORD="<le mot de passe du user de votre base MySQL"
DB=<nom de la base de donnée MySQL Rundeck>cd /var/lib/rundeck/logs/rundeck
JOBS=`find . -maxdepth 3 -path "*/job/*" -type d`
for j in $JOBS ; do
echo "Processing job $j"
ids=`find $j -iname "*.rdlog" | sed -e "s/.*\/\([0-9]*\)\.rdlog/\1/" | sort -n -r`
declare -a JOBIDS=($ids)if [ ${#JOBIDS[@]} -gt $KEEP ]; then
for job in ${JOBIDS[@]:$KEEP};do
echo " * Deleting job: $job"
echo " rm -rf $j/logs/$job.*"
rm -rf $j/logs/$job.*
workflowid=`mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -s -N -e "select workflow_id from execution where id=$job" $DB`
workflowstepids=`mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -s -N -e "select workflow_step_id from workflow_workflow_step where workflow_commands_id=$workflowid" $DB`
declare -a WSIDS=($workflowstepids)
for workflowstepid in $WSIDS ; do
echo " mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -e 'delete from workflow_workflow_step where workflow_step_id=$workflowstepid' $DB"
mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -e "delete from workflow_workflow_step where workflow_step_id=$workflowstepid" $DB
echo " mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -e 'delete from workflow_step where id=$workflowstepid' $DB"
mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -e "delete from workflow_step where id=$workflowstepid" $DB
done
echo " mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -e 'delete from execution where id=$job' $DB"
mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -e "delete from execution where id=$job" $DB
echo " mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -e 'delete from base_report where jc_exec_id=$job' $DB"
mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -e "delete from base_report where jc_exec_id=$job" $DB
echo " mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -e 'delete from workflow where id=$workflowid' $DB"
mysql -h $HOST -P $PORT -u$USERNAME -p$PASSWORD -e "delete from workflow where id=$workflowid" $DB
done
fi
done
Tutoriel | Déployez facilement un cluster Kubernetes avec Rancher
Article publiée le 13 Janvier 2018
Article mis à jour le 21 Août 2018
Kubernetes est un orchestrateur de container docker extrêmement puissant mais également très fastidieux à déployer. Il existe pourtant un moyen très simple pour déployer Kubernetes en utilisant Rancher.
Rancher est un outil permettant de gérer vos environnements Docker de manière intuitive via une interface graphique (site de Rancher: https://rancher.com/)
Pour ce tuto je vais utiliser trois machines sous Debian 9 avec docker installé. Pour ceux qui ne connaissent pas Docker, je leurs suggère de lire le tutoriel ci-dessous:
Pour info un tutoriel rédigé le 20 Août 2018 explique comment installer Kubernetes from scratch (à la mano!) sur Debian ou Centos . Ce tuto est disponible ici
1) Installation de Rancher
Installer Rancher est très facile, il suffit de déployer le container fournit par l'éditeur:

Au moment de la rédaction de cet article, la version stable de Rancher est la version 1.6. La version 2.0 est une version Alpha en cours de développement (très instable).
Nous allons installer Rancher sur notre première machine:
docker run -d --restart=unless-stopped -p 8080:8080 rancher/server:stable
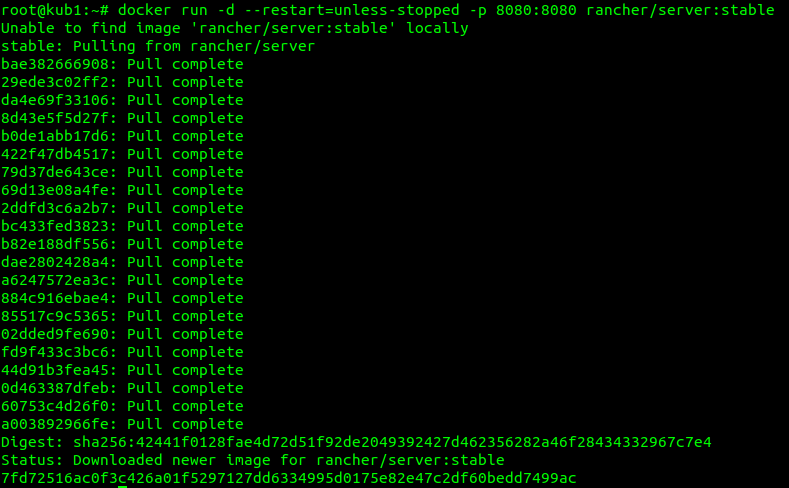
Une fois le container installé, connectez vous à l'interface Web: <ip de votre machine>:8080
Rancher est installé et opérationnel!
Petite parenthèse, si vous allez dans l'onglet "CATALOG" vous verrez que Rancher peut déployer un large panel d'outils:

2) Kubernetes
Revenons en à nos moutons, nous allons maintenant déployer Kubernetes via Rancher.
Dans un premier temps cliquez sur l'onglet "infrastructure" puis "Hosts"
Puis cliquez sur le bouton "Add Host":
Contentez vous de copier la ligne de commande au paragraphe 5 et de la coller sur toutes les machines Linux qui serviront de nœud à votre infra kubernetes (dans mon cas les 3 machines sous Debian que j'ai créées).
Cette commande va déployer un container contenant un agent Rancher qui va gérer chacune de vos machines!
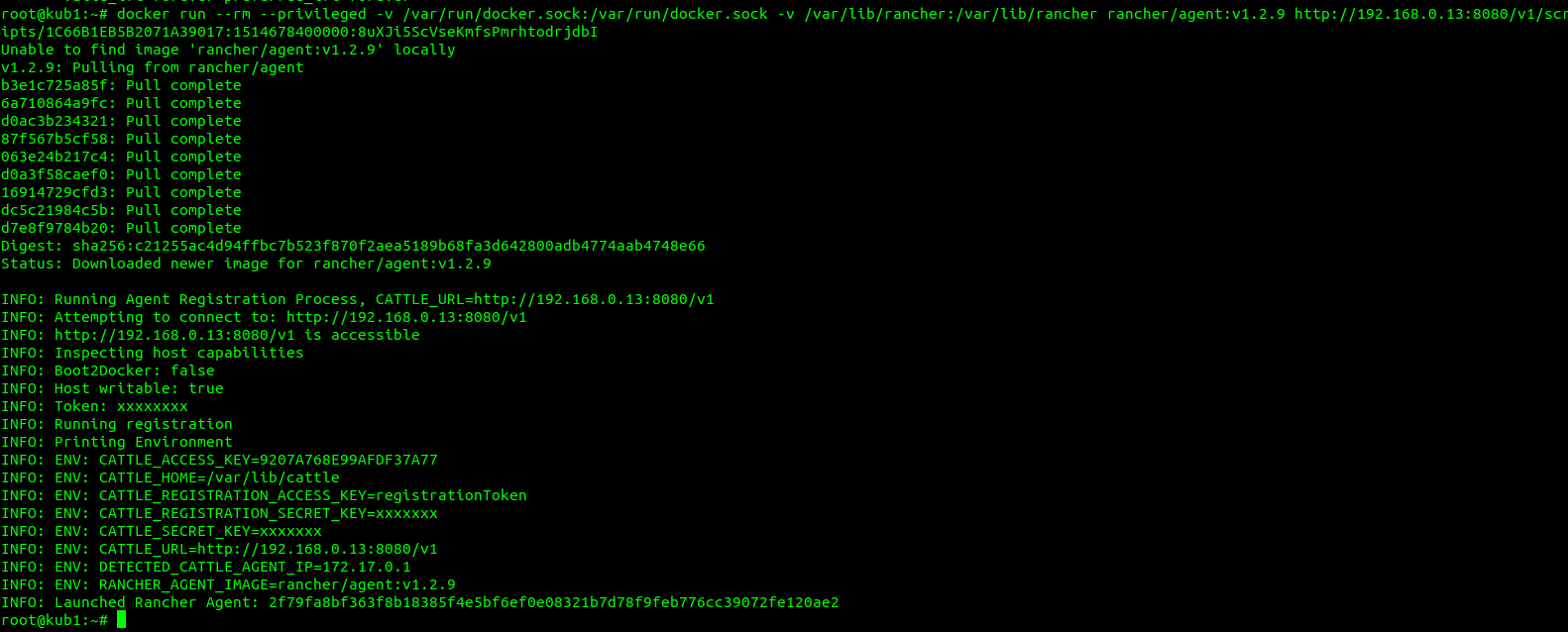
Retournez dans l'onglet "infrastructure"/"Hosts" pour vérifier que vos machines sont bien remontées:
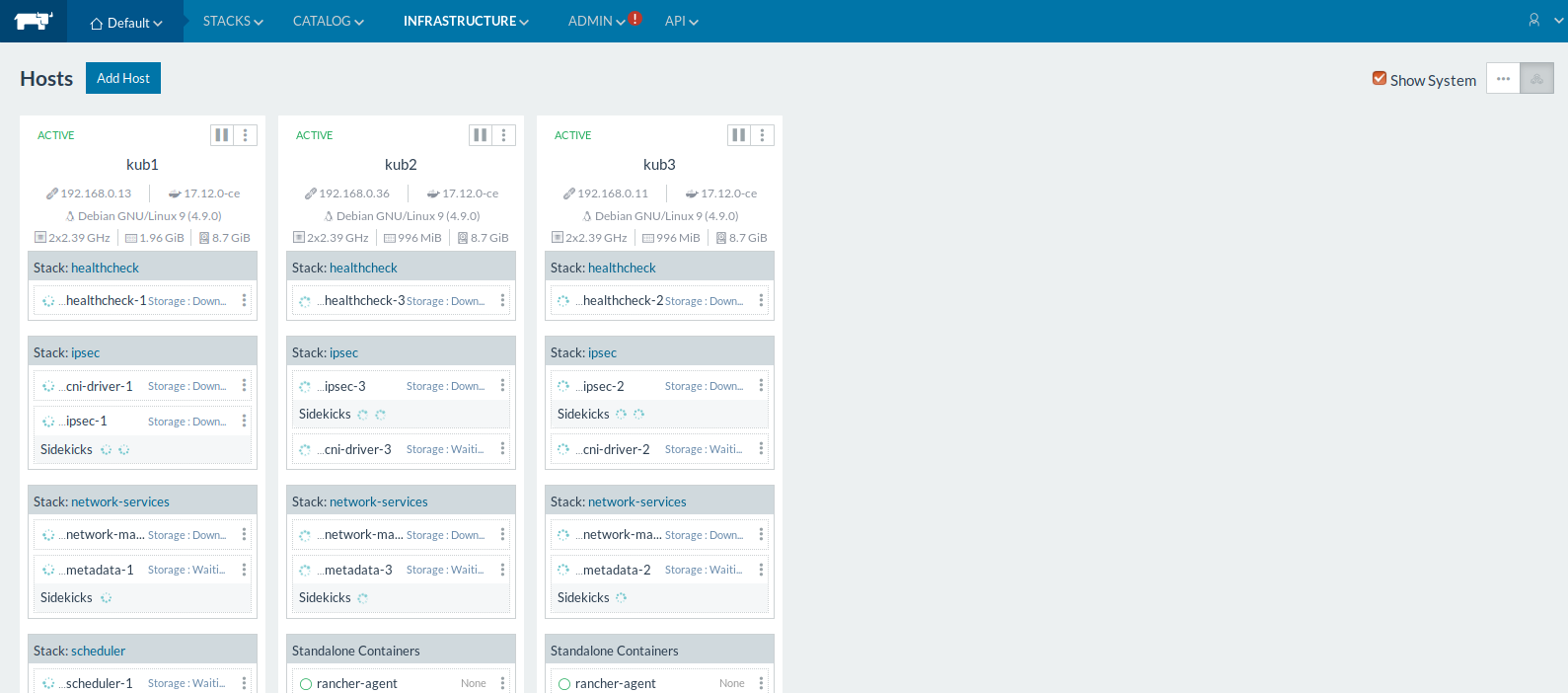
Cliquez ensuite sur "Catalog" puis cherchez "Kubernetes" et cliquez sur "View details":

Laissez tout par défaut et validez en cliquant sur le bouton tout en bas de la page.
Un nouvel onglet "Kubernetes devrait apparaître. En cliquant dessous, vous pourrez suivre l'avancement de l'installation:
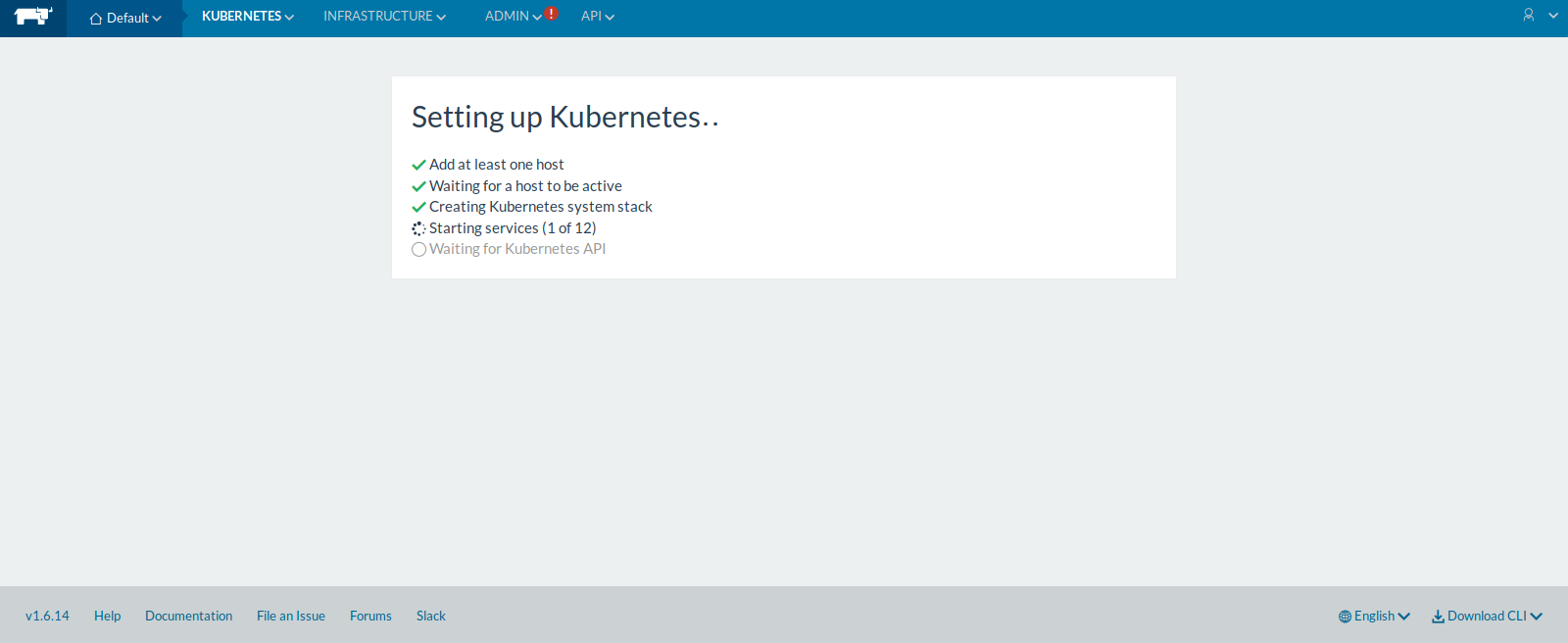
Vous pouvez suivre avec plus de détails l'installation de chaque composant Kubernetes en cliquant sur l'onglet "Kubernetes" puis "Infrastructure Stacks":
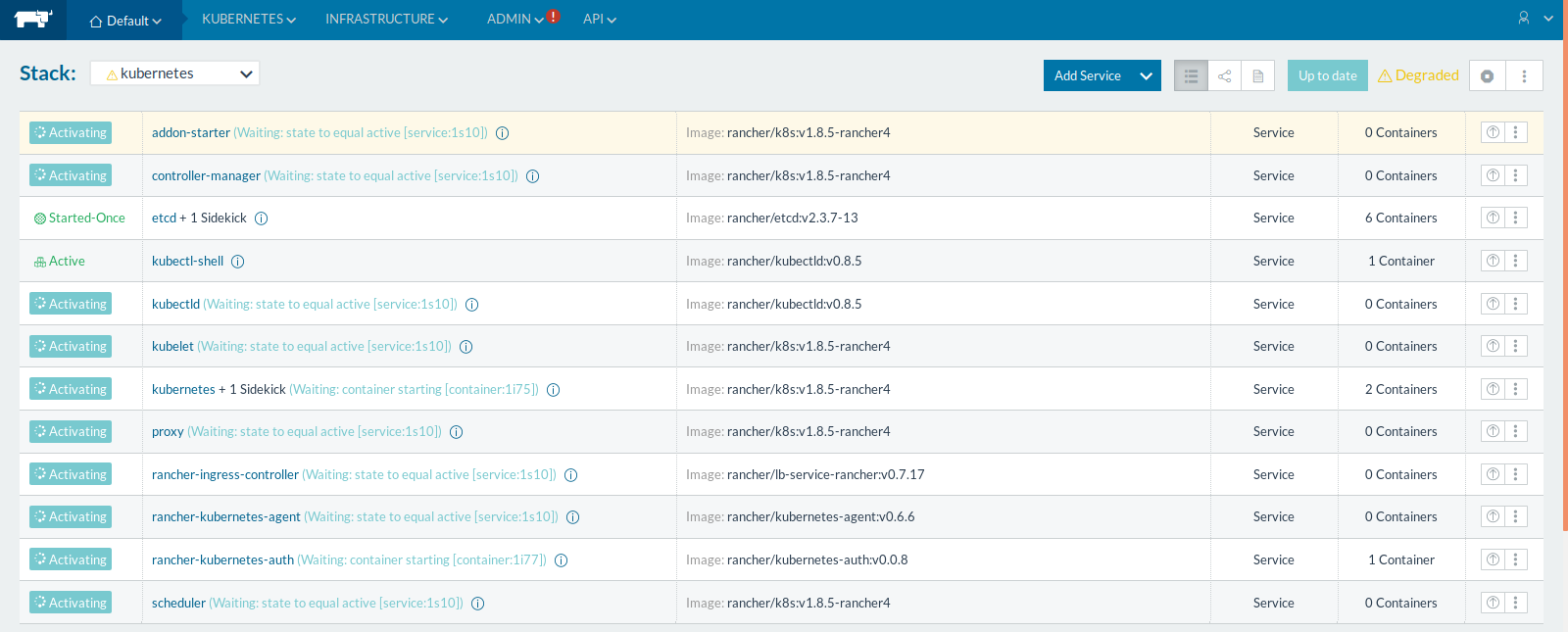
Une fois que tous les statuts seront à "Active", les composants Kubernetes seront installés:
Vous pouvez maintenant vous connectez à l'interface Kubernetes en cliquant sur l'onglet "Kubernetes" puis "Dashboard":
Cliquez sur "Kubernetes UI":
Vous voila connecté à l'interface Kubernetes.
Pour les personnes ayant plus de connaissances, une interface en ligne de commande est également disponible depuis l'interface de Rancher via l'onglet "Kubernetes"/"_Cli":
3) Déploiement d'un container
Pour vous prouver que je ne me moque pas de vous et que tout fonctionne, je vais déployer un container apache répliqué sur 2 deux nœuds:
Cliquez sur le bouton "CREATE" en haut à droite et remplissez les champs requis:
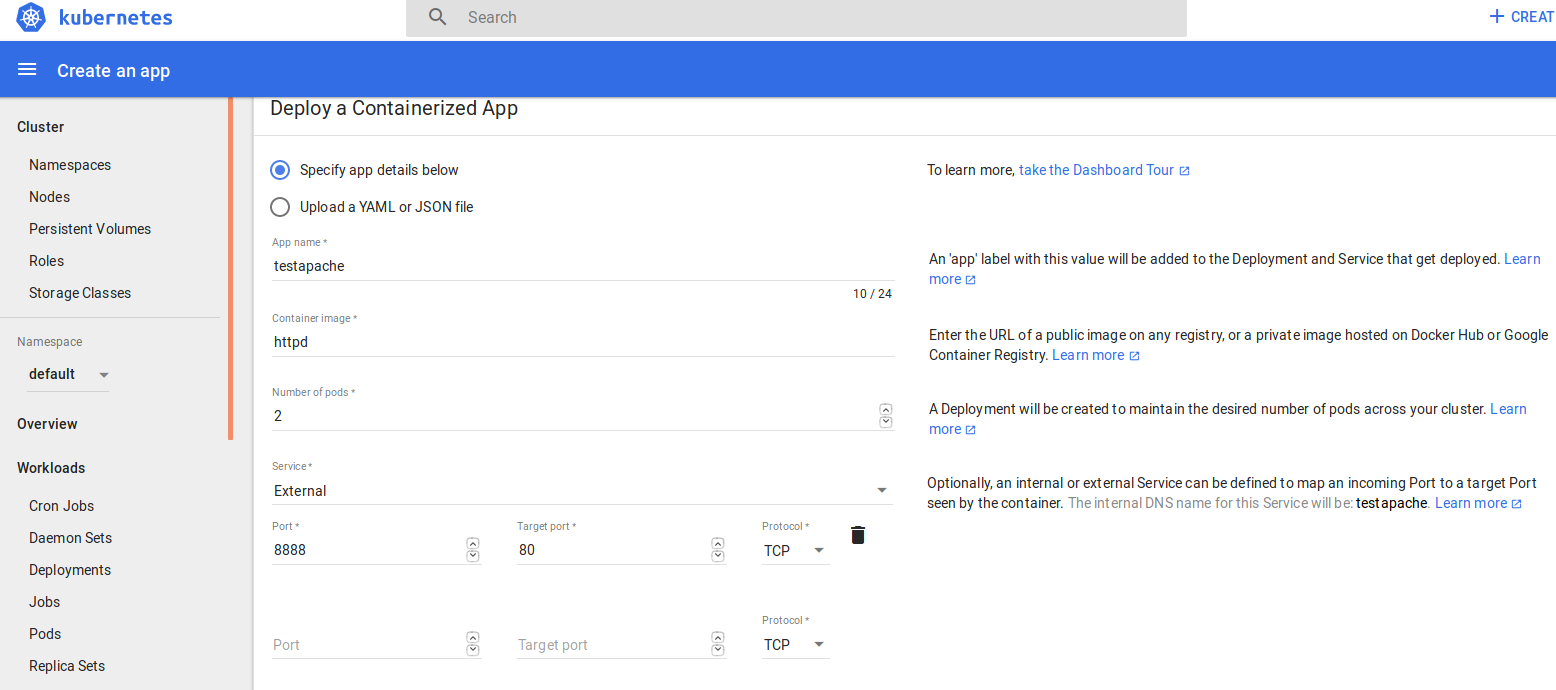
Deux container apache ont été déployés sur deux différents nœuds (très pratique pour la tolérance de panne ;-)):
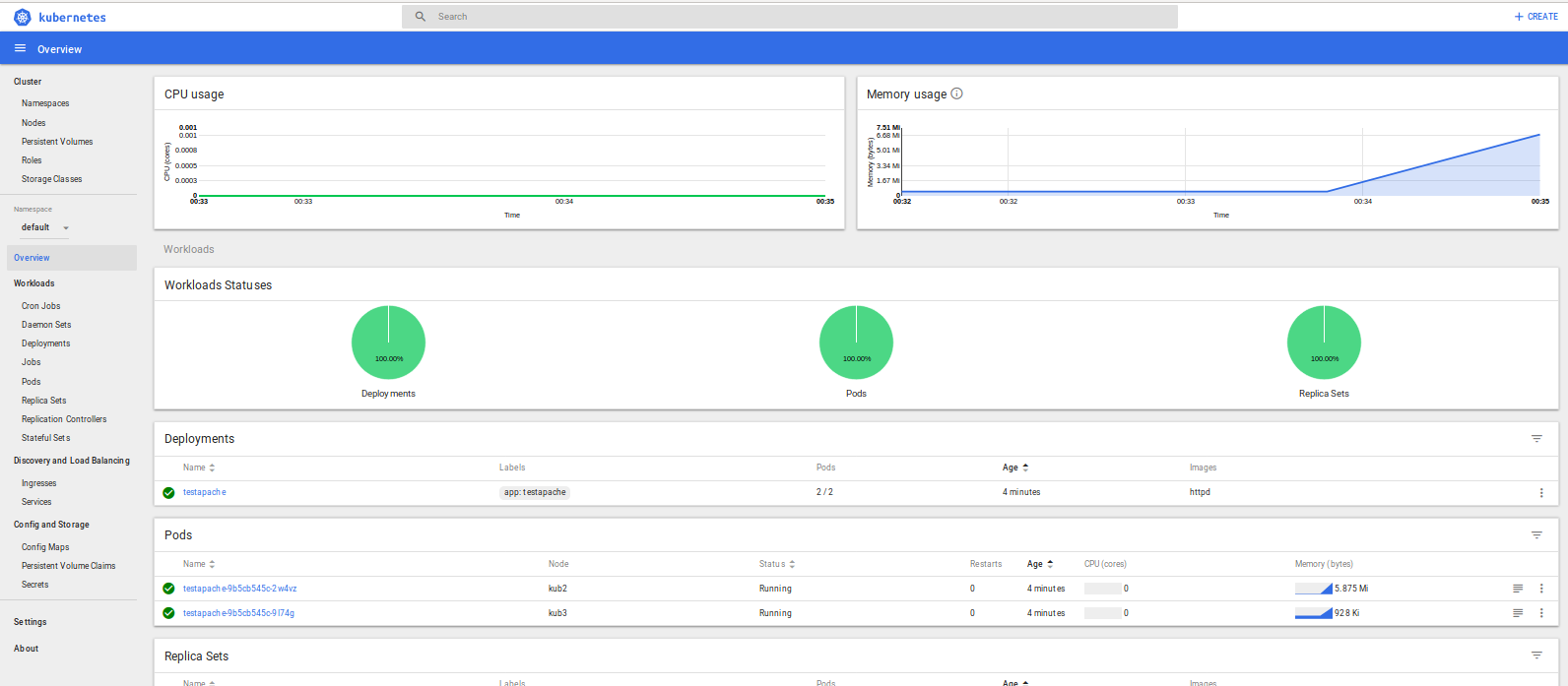
En me connectant sur l'un des nœuds au hasard, mon apache répond bien!
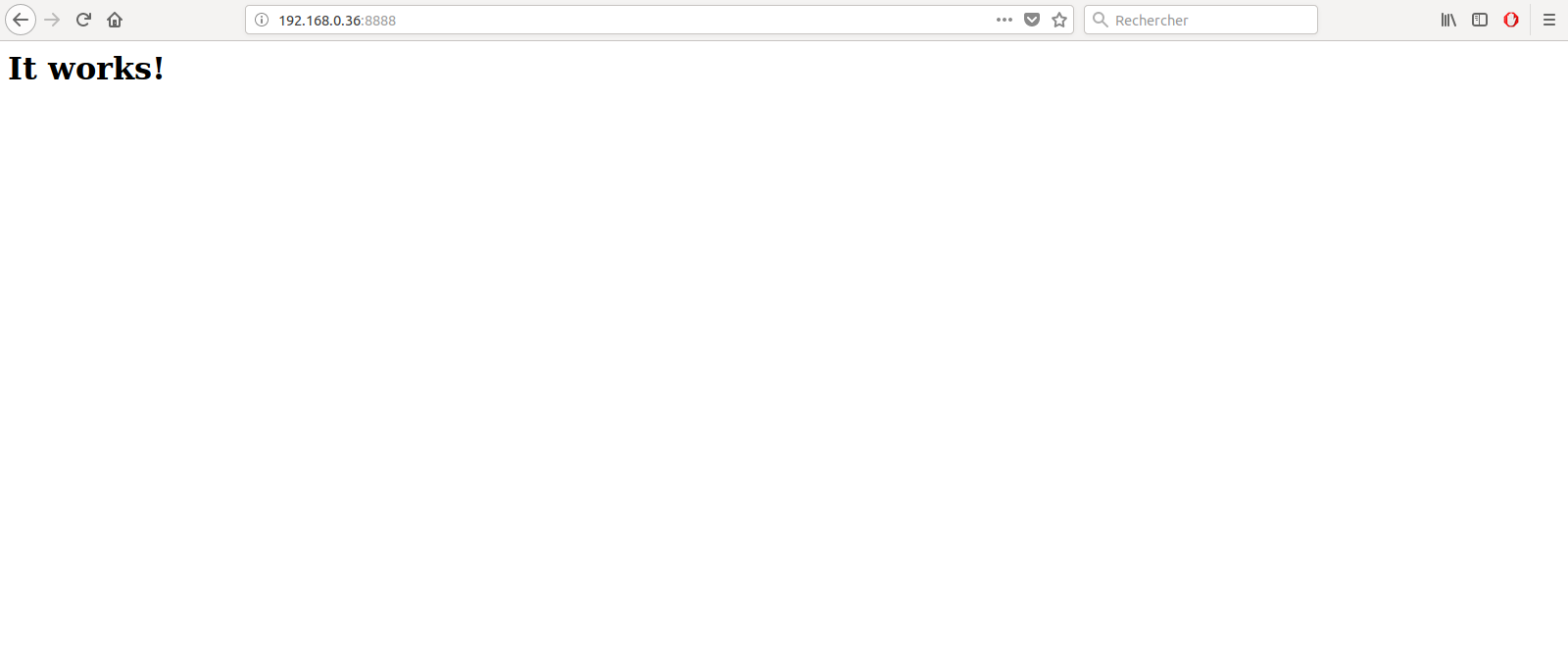
Enjoy!
AWX l’alternative gratuite à Ansible Tower
Article publiée le 03 octobre 2017
Tous les utilisateurs connaissent Ansible Tower, l'interface graphique pour gérer Ansible créé par RedHat qui est une solution très onéreuse! Hors une variante opensource existe également sponsorisé depuis peu par RedHat :AWX
Ci-dessous une petite doc d'installation dédiée adaptée aux distributions RedHat/CentOS:
- Installez Ansible: yum install ansible
- Créer le fichier install_aws.yml qui contiendra le playbook d'installation AWX:
- name: Deploy AWX
hosts: all
become: true
become_user: roottasks:
- name: sort out the yum repos
yum:
name: "{{ item }}"
state: "latest"
with_items:
- "epel-release"
- "yum-utils"- name: add the docker ce yum repo
yum_repository:
name: "docker-ce"
description: "Docker CE YUM repo"
gpgcheck: "yes"
enabled: "yes"
baseurl: "https://download.docker.com/linux/centos/7/$basearch/stable"
gpgkey: "https://download.docker.com/linux/centos/gpg"- name: install the prerequisites using yum
yum:
name: "{{ item }}"
state: "latest"
with_items:
- "epel-release"
- "libselinux-python"
- "python-wheel"
- "python-pip"
- "git"
- "docker-ce"- name: start and enable docker
systemd:
name: "docker"
enabled: "yes"
state: "started"- name: install the python packages using pip
pip:
name: "{{ item }}"
state: "latest"
with_items:
- "pip"
- "ansible"
- "boto"
- "boto3"
- "docker"- name: check out the awx repo
git:
repo: "https://github.com/ansible/awx.git"
dest: "~/awx"
clone: "yes"
update: "yes"- name: install awx
command: "ansible-playbook -i inventory install.yml"
args:
chdir: "~/awx/installer"
- Exécutez le playbook (pensez à rajouter votre machine dans le fichier /etc/ansible/hosts):
ansible-playbook -i hosts install_aws.yml
- Une fois le playbook exécuté vous devriez avoir des container docker monté:

- Connectez vous sur l'interface Web via l'url suivante: http://<ipoudnsdevotremachine>
- Attendez que l'installation de AWX se finalise:

- Une fois l'installation terminée authentifiez vous avec les identifiants par défaut (login : admin, mot de passe: password):
- Une fois authentifié le dashboard AWX sera affiché :
Comme vous pouvez le constater l'interface AWX est identique à celle de Tower!
Tutoriel | Gérez vos container docker avec Portainer
Article publié le 2 Octobre 2017
Un petit tutoriel afin de vous présenter un outil peu connu mais extrêmement puissant vous permettant de gérer vos environnements Docker avec une simplicité sans égale: Portainer.
Si vous cherchez une interface graphique pour gérer votre environnement docker, portainer est fait pour vous!
Afin de suivre ce tuto, Docker doit-être installé sur votre machine. Un tuto sur l'installation et la configuration de docker est disponible :
https://journaldunadminlinux.fr/tuto-docker-demarrer-avec-docker/
1) Installation de Portainer
Portainer est livré nativement dans un container docker. Pour le déployer :
docker run -d -p 9000:9000 -v /var/run/docker.sock:/var/run/docker.sock -v /opt/portainer:/data portainer/portainer
Une fois le container déployé connectez vous à l'interface web via l'adresse suivante: http://ipdevotremachine:9000
2) Configuration
Lors de la première connexion, il vous sera demandé de créer le mot de passe du user admin:
Il vous sera demandé ensuite de "brancher" votre instance portainer à votre machine Docker.
Dans mon cas mon instance portainer est installée au même endroit que mon instance Docker.
Vous voilà connecté au dashboard:
2.1) Déployer un container
Nous allons tout d'abord faire un pull d'une image, pour cela cliquer sur "images" dans le menu de gauche:
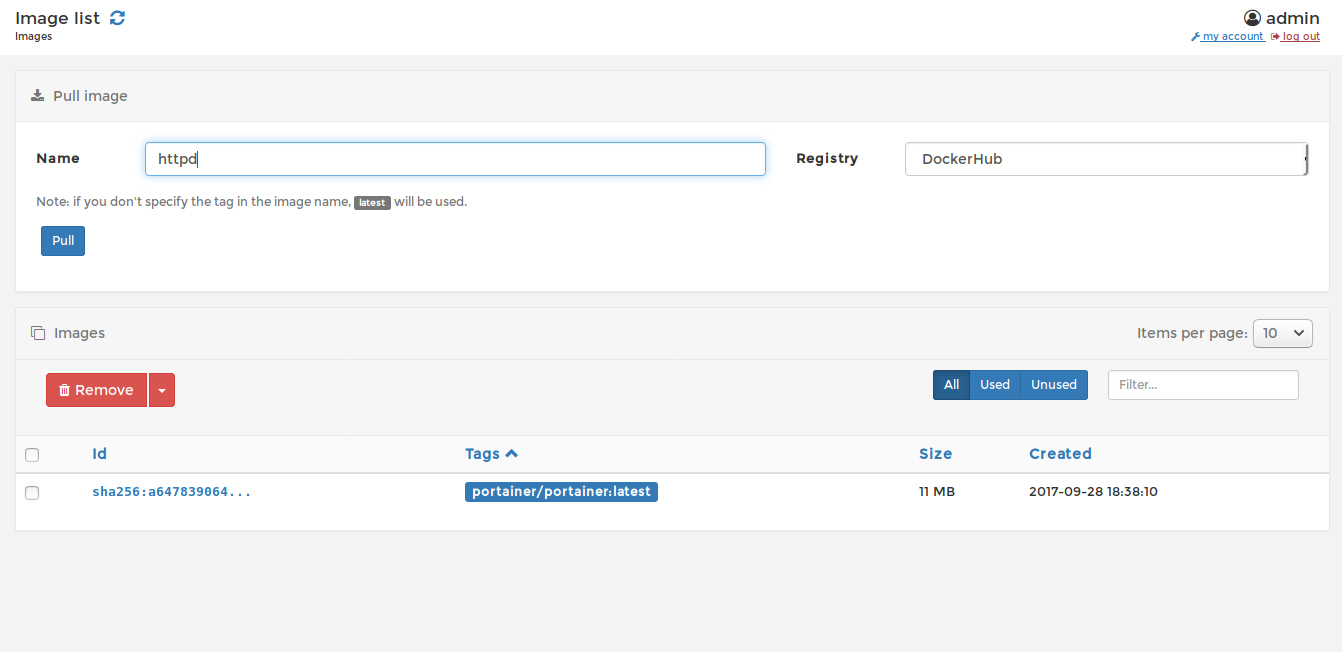
Tapez le nom de l'image Docker que vous voulez utiliser puis cliquez sur "pull" (dans notre cas, nous allons faire un pull de l'image httpd).
Une fois le pull terminé, notre image sera présente dans la liste:
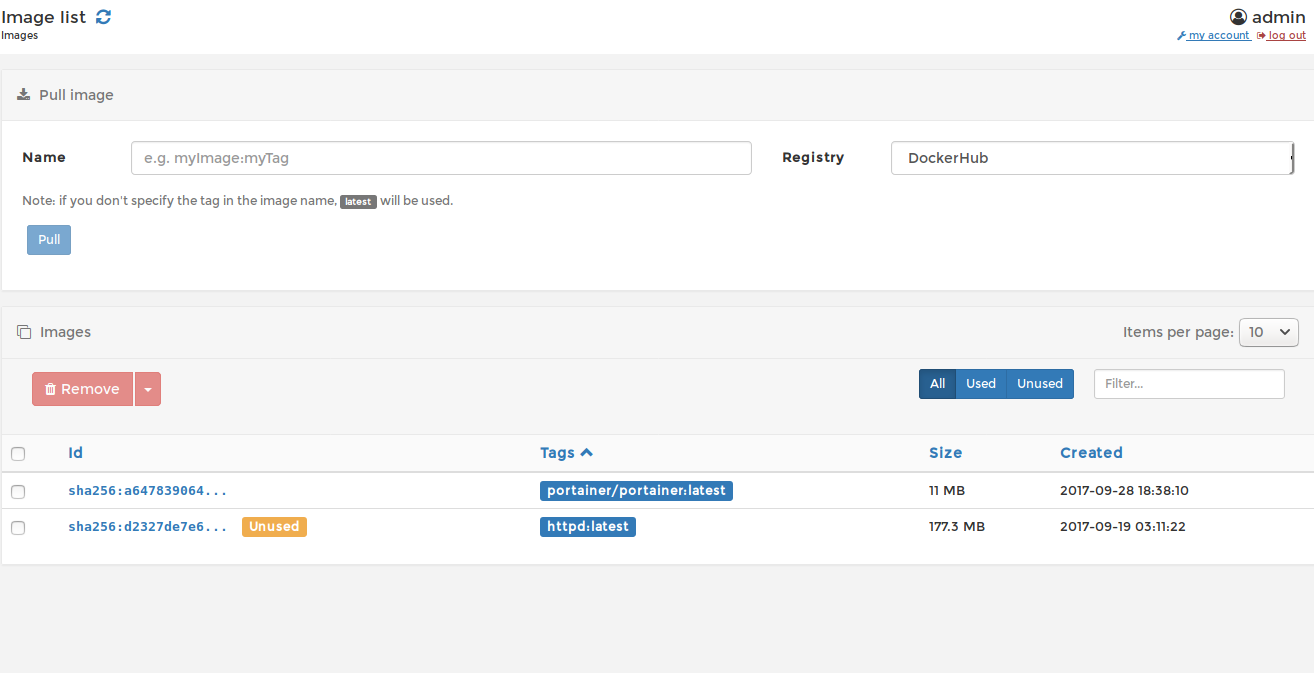
Nous allons maintenant déployer un container docker apache. Pour cela cliquez sur "container"
Puis sur le bouton "Add container".
Procédez au paramétrage de votre container docker grâce à cette superbe interface intuitive puis cliquez sur le bouton "start container"
Votre container est à présent démarré!
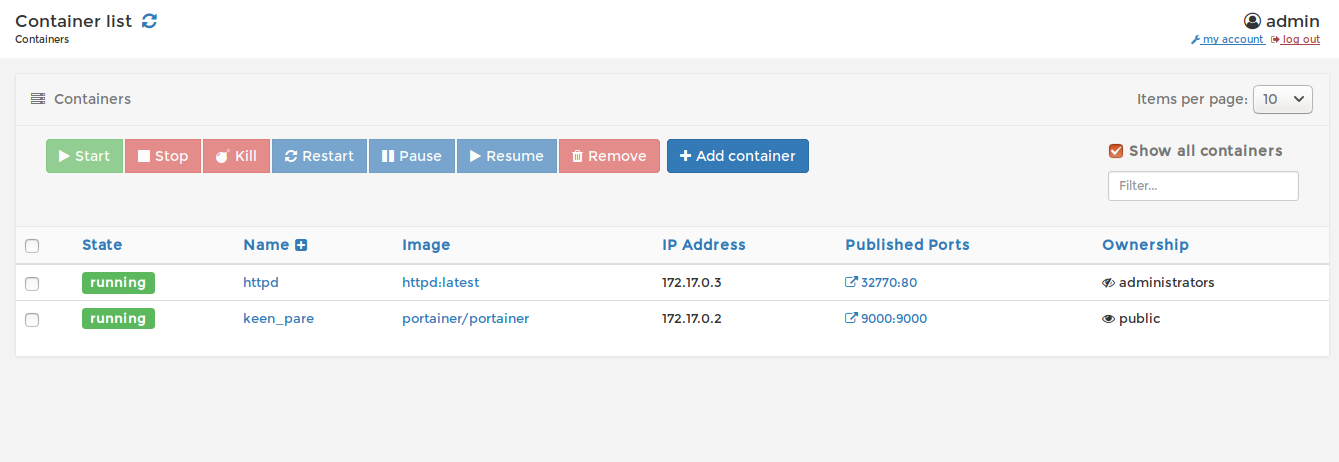
En cliquant sur le nom de votre container, vous aurez accès à toute la supervision nécessaire:
En cliquant sur "Stats":
2.2) Rajouter une machine docker ou un cluster docker Swarm
Comme vous avez pu le constater dans le chapitre précédent l'interface est extrêmement simple et intuitive. Cet outil vous simplifiera grandement la vie pour gérer vos environnements docker.
Pour rajouter une machine ou un cluster swarm, cliquez sur le bouton "Endpoints" situé dans le menu en bas à gauche
Comme vous l'avez compris grâce à cette fonctionnalité, vous pouvez ajouter et gérer tout vos environnement dockers!
Pour plus d'info le github du projet: https://github.com/portainer/portainer et un grand bravo aux développeurs!!
Présentation de Zentyal 5
Article publié le 1er Octobre 2017
Deux après la rédaction de mon article sur la solution IPCOP (https://journaldunadminlinux.fr/tutoriel-securiser-son-reseau-avec-ipcop/), je vais partager aujourd'hui ma nouvelle découverte: Zentyal.
Zentyal est une solution de sécurité (mais pas seulement) Opensource vous offrant pleins de fonctionnalités:
- Mise en réseau (Networking)
- Pare-feu (informatique) et routage
- Filtrage
- NAT (Network address translation) et redirections de port
- VLAN 802.1Q (Réseau local virtuel)
- Support de passerelles IP multiples (PPPoE and DHCP)
- Règles de passerelle multiple, équilibrage de charge et basculement automatique
- Lissage du trafic (à l'aide d'une couche d'application)
- Suivi graphique de la vitesse du trafic
- Système de détection d'intrusions dans le système
- Client DNS dynamique
- Infrastructure réseau
- Serveur DHCP (Dynamic Host Configuration Protocol)
- Serveur NTP (Network Time Protocol)
- Serveur DNS
- Mises à jour dynamiques via DHCP (Dynamic Host Configuration Protocol)
- Serveur RADIUS (Remote Authentication Dial-In User Service)
- Prise en charge VPN
- Autoconfiguration de routes dynamiques
- Proxy HTTP
- Cache Internet
- Authentification de(s) utilisateur(s)
- Filtrage de contenu (avec des listes par catégorie)
- Antivirus transparent
- Système de détection d'intrusions
- Serveur mail
- Domaines virtuels
- Quotas
- Soutien pour Sieve
- Récupération de compte externe
- POP3 et IMAP avec SSL/TLS
- Filtre antispam et antivirus
- Listes grises, noires et blanches
- Filtre proxy transparent POP3
- Compte "catch-all" (fourre-tout)
- Pare-feu (informatique) et routage
- Messagerie internet (webmail)
- Serveur internet (web server)
- Hôtes virtuels
- Autorité de certification
- Travail de groupe (workgroup)
- Gestion centralisée des utilisateurs et des groupes
- Soutien maître/esclave
- Synchronisation avec un contrôleur de domaine Windows Active Directory
- Windows PDC
- Système de mot de passe
- Assistance pour les clients Windows 7
- Partage des ressources en réseau
- Serveur de fichiers
- Antivirus
- Corbeille
- Serveur d'impression
- Serveur de fichiers
- Groupware: partage de calendriers, agendas, repertoire, boîte mail, wiki, etc.
- Serveur VoIP
- Messagerie vocale
- Salles de conférence
- Appels via un fournisseur externe
- Transferts d'appels
- Parking d'appel
- Musique d'attente
- Files d'attente (mise en attente)
- Journaux d'appels
- Gestion centralisée des utilisateurs et des groupes
- Serveur Jabber et (XMPP)
- Coin des utilisateurs eBox
- Suivi et rapports
- Mises à jour du logiciel
- Sauvegardes (configuration et sauvegarde de données à distance)
Pour moi, le principal avantage de Zentyal est sa simplicité d'implémentation et toutes les fonctionnalités dont elle dispose. Zentyal est la solution parfaite pour une petite entreprise/startup qui désire monter une infra sans dépenser une fortune.
1) Installation/Configuration
Téléchargez directement l'ISO sur le site de Zentyal: http://www.zentyal.org/server/ (Development édition).
Bootez ensuite sur l'ISO:
Sélectionnez la langue d'installation
Sélectionnez "Install Zentyal 5.0.1-development (delete all disk)".

L'installation se fera ensuite de la même manière que l'installation d'une distribution de Linux classique. D'ailleurs, Zentyal est basé sur une Ubuntu 16.04!
2) Présentation des fonctionnalités de Zentyal
Une fois l'installation terminée, connectez vous à l'interface Web de Zentyal via l'adresse:https://ipdevotremchine:8443.
Saisissez les identifiants que vous avez paramétrés durant l'installation:

L'assistant de configuration va démarrer:

Sélectionnez les composants qui vous intéressent.
Confirmez l'installation:
L'assistant d'installation va installer tout les paquets demandés:
Procédez aux paramétrages de vos cartes réseaux:
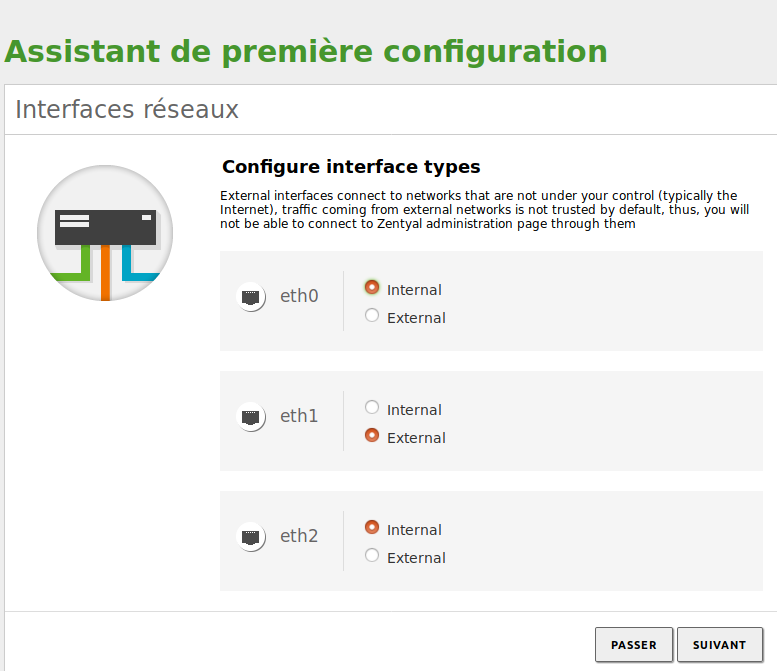
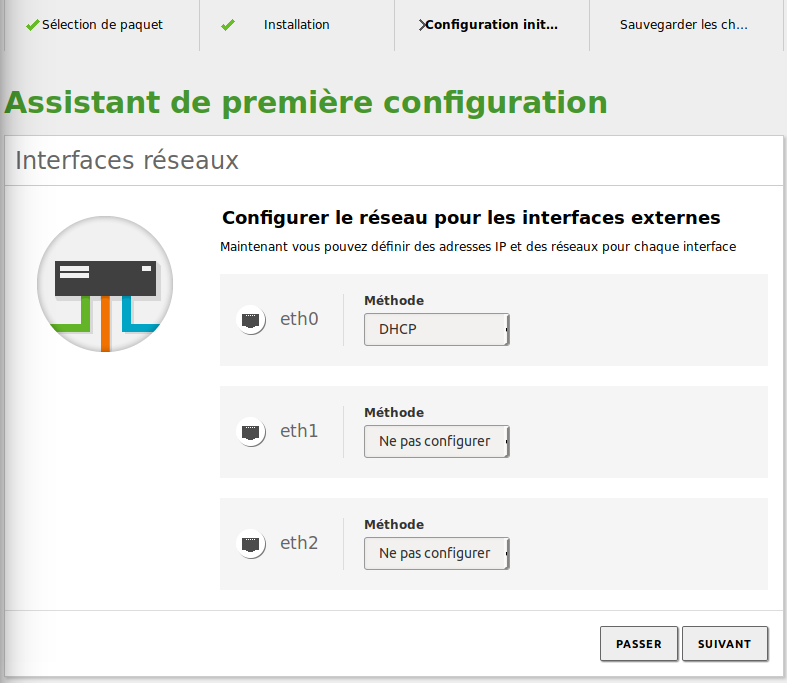
Une fois la configuration terminée cliquez sur le bouton "Go to the dashboard"
3) Présentation
Voici l'interface de Zentyal:
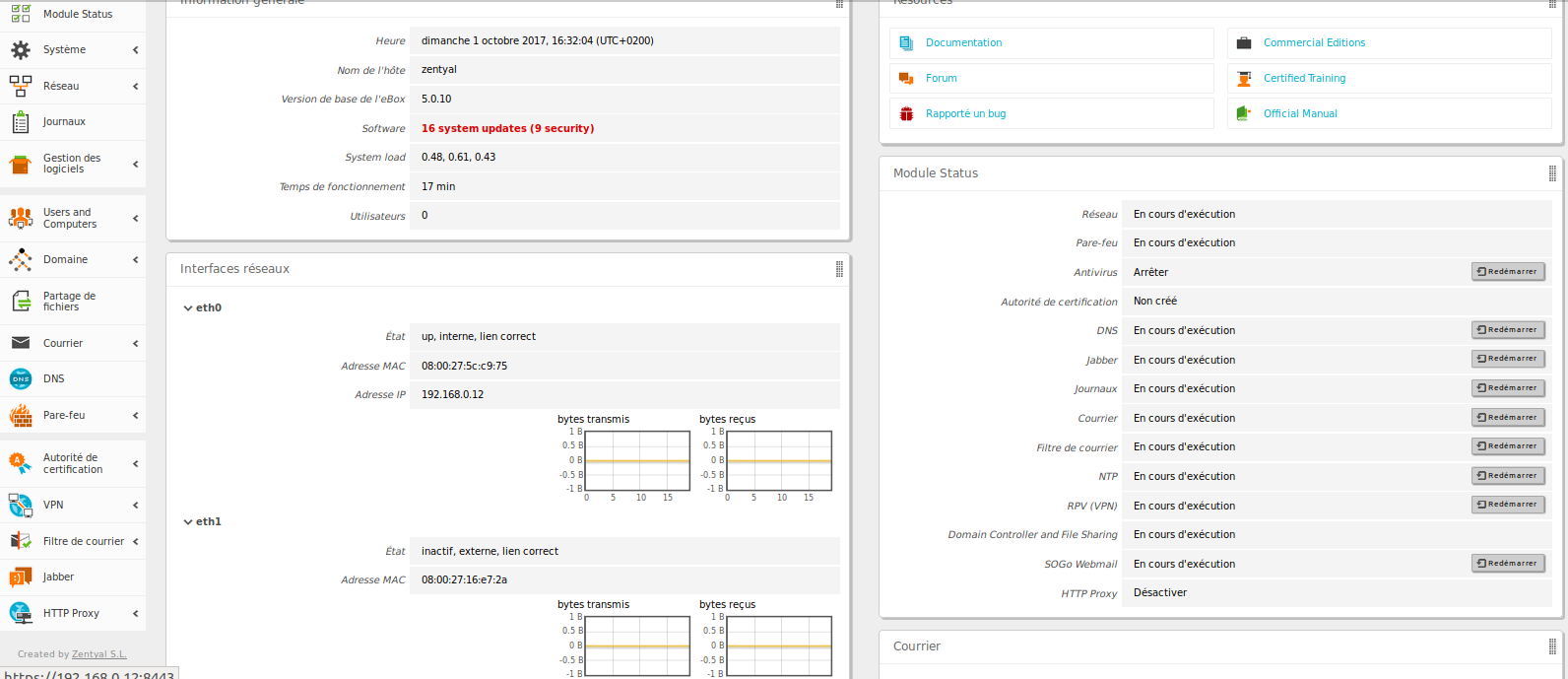
Comme vous pouvez le constater, Zentyal est une véritable boite à clic vous permettant d'installer et d'administrer de manière simple le service dont vous avez besoin (Firewall, Routeur, etc...).
Network
Zentyal n'a absolument rien à envier de ses concurrents payant (sophos, sonicwall, etc...):
On appréciera également les fonctionnalités "Balance Traffic" et "Wan Failover" vous permettant respectivement de dispatcher le trafic sortant sur plusieurs sorties internet (si vous avez deux lignes ) ou de mettre en place une bascule automatique vers une autre ligne internet en cas de perte d'une connexion:
Firewall
L'interface de configuration du Firewall est très bien conçue:
Bref comme vous l'aurez compris Zentyal possède énormément de fonctionnalités à tel point que vous pourriez gérer l'intégralité de l'infra de votre entreprise uniquement avec cette solution.
Il faudrait une bonne centaine de page pour vous présenter l'intégralité des fonctionnalités de Zentyal, c'est pourquoi je vous laisse découvrir par vous-même cette solution absolument géniale!
Enjoy!
